
运行MapReduce作业,执行成功的话跟单机模式相同,输出作业信息。
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar grep input output 'dfs[a-z.]+'查看运行结果
bin/hdfs dfs -cat output/*也可以将运行结果取回到本地。
rm -R ./output bin/hdfs dfs -get output output cat ./output/*结果如下,注意到跟单机模式中用的不是相同的数据,所以运行结果不同(换成原来的数据,结果是一致的)。
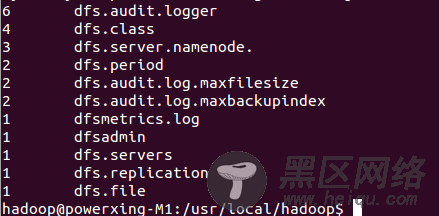
可以看到,使用bin/hdfs dfs -命令可操作分布式文件系统, 如
bin/hdfs dfs -ls /user/hadoop # 查看`/user/hadoop`中的文件 bin/hdfs dfs -rm -R /user/hadoop/input/* # 删除 input 中的文件 bin/hdfs dfs -rm -R /user/hadoop/output # 删除 output 文件夹运行程序时,输出目录需不存在
运行 Hadoop 程序时,结果的输出目录(如output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。建议在程序中加上如下代码进行删除,避免繁琐的命令行操作:
Configuration conf = new Configuration(); Job job = new Job(conf); ... /* 删除输出目录 */ Path outputPath = new Path(args[1]); outputPath.getFileSystem(conf).delete(outputPath, true); ...结束Hadoop进程,则运行
sbin/stop-dfs.sh注意
下次再启动hadoop,无需进行HDFS的初始化,只需要运行 sbin/stop-dfs.sh 就可以!
--------------------------------------分割线 --------------------------------------
Ubuntu14.04下Hadoop2.4.1单机/伪分布式安装配置教程
CentOS安装和配置Hadoop2.2.0