
Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分离的Java进程来运行,节点即是NameNode也是DataNode。需要修改2个配置文件etc/hadoop/core-site.xml和etc/hadoop/hdfs-site.xml。Hadoop的配置文件是xml格式,声明property的name和value。
修改配置文件etc/hadoop/core-site.xml,将
<configuration> </configuration>修改为下面配置:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>修改配置文件etc/hadoop/hdfs-site.xml为
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>关于配置的一点说明:上面只要配置 fs.defaultFS 和 dfs.replication 就可以运行,不过有个说法是如没有配置 hadoop.tmp.dir 参数,此时 Hadoop 默认的使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在每次重启后都会被干掉,必须重新执行 format 才行(未验证),所以伪分布式配置中最好还是设置一下。此外也需要显式指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则下一步可能会出错。
配置完成后,首先初始化文件系统 HDFS:
bin/hdfs namenode -format成功的话,最后的提示如下,Exitting with status 0 表示成功,Exitting with status 1: 则是出错。若出错,可试着加上 sudo, 既 sudo bin/hdfs namenode -format 试试看。

接着开启NaneNode和DataNode守护进程。
sbin/start-dfs.sh若出现下面SSH的提示,输入yes即可。

有可能会出现如下很多的warn提示,下面的步骤中也会出现,特别是native-hadoop library这个提示,可以忽略,并不会影响hadoop的功能。想解决这些提示可以看后面的附加教程(最好还是解决下,不困难,省得看这么多无用提示)。

成功启动后,可以通过命令jps看到启动了如下进程NameNode、DataNode和SecondaryNameNode。
通过查看启动日志分析启动失败原因
有时Hadoop无法正确启动,如 NameNode 进程没有顺利启动,这时可以查看启动日志来排查原因,不过新手可能需要注意几点:
启动时会提示形如 “Master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-Master.out”,其中 Master 对应你的机器名,但其实启动日志信息是记录在 /usr/local/hadoop/logs/hadoop-hadoop-namenode-Master.log 中,所以应该查看这个 .log 的文件;
每一次的启动日志都是追加在日志文件之后,所以得拉到最后面看,这个看下记录的时间就知道了。
一般出错的提示在最后面,也就是写着 Fatal、Error 或者 Java Exception 的地方。
通过jps查看启动的Hadoop进程
此时可以访问Web界面:50070来查看Hadoop的信息。
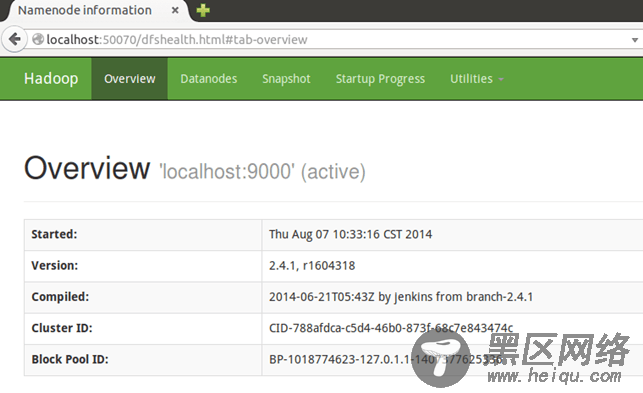
首先创建所需的几个目录
bin/hdfs dfs -mkdir /user bin/hdfs dfs -mkdir /user/hadoop接着将etc/hadoop中的文件作为输入文件复制到分布式文件系统中,即将/usr/local/hadoop/etc/hadoop复制到分布式文件系统中的/user/hadoop/input中。上一步创建的 /user/hadoop 相当于 HDFS 中的用户当前目录,可以看到复制文件时无需指定绝对目录,下面的命令的目标路径就是 /user/hadoop/input:
bin/hdfs dfs -put etc/hadoop input