
– 打开editplus,选择”File—FTP—FTP Setting” –
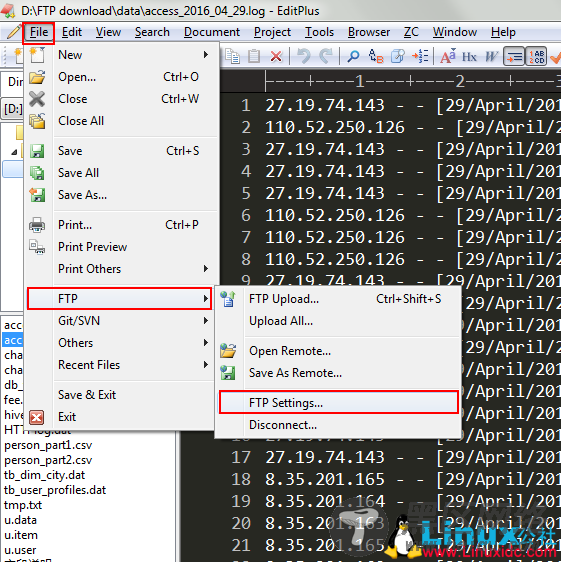
– 选择添加 –
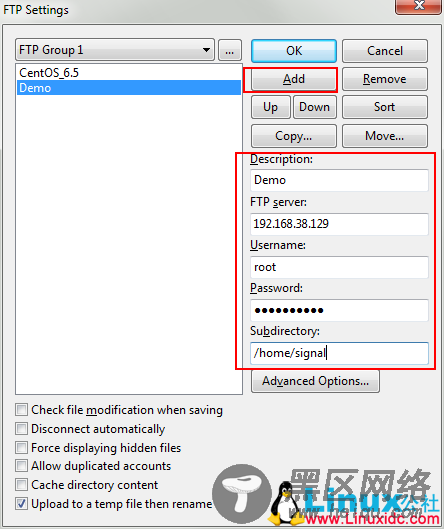
并且在相应的字段上填上值,对于”Subdirectory”这一项要填写的是你希望上传到Linux上的哪个目录。
– 点击”Advanced Options” –
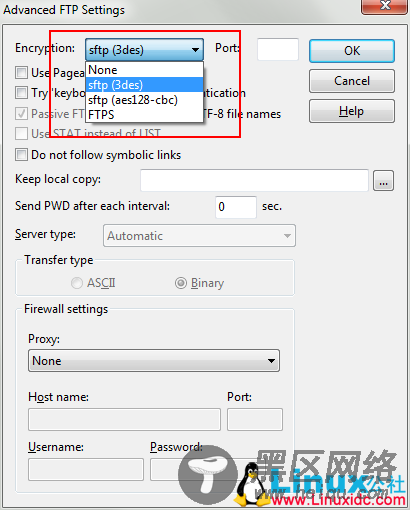
之后便可以一路OK回去。
– 选择FTP Upload –
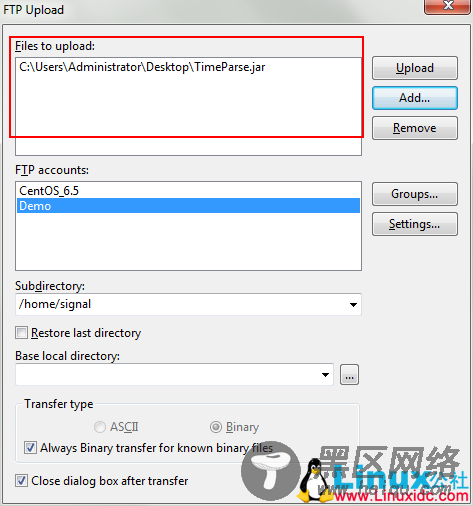
在这里找到要上传的文件,选择要上传到哪一个账户上,并选择”Upload”即可。
然后我们就可以在”Subdirectory”中写到的目录下去找我们的文件了。
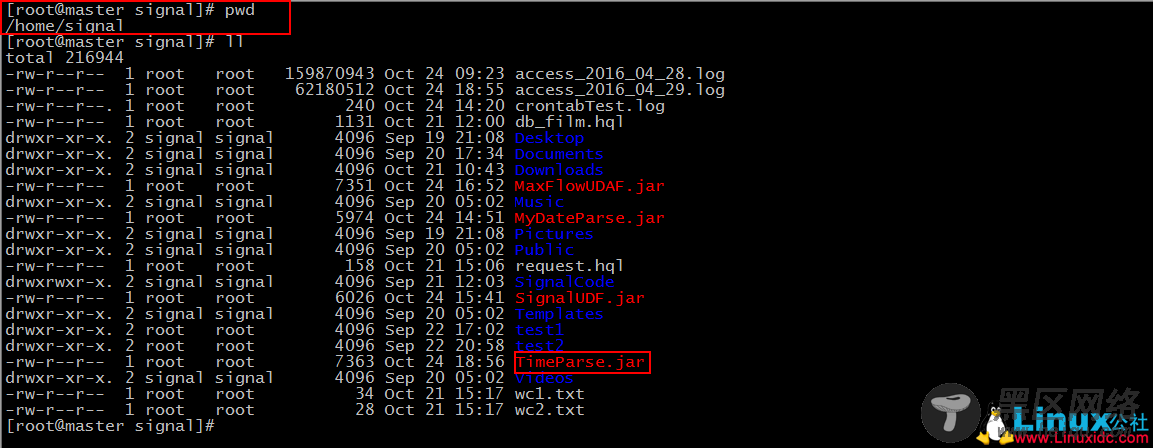
– 小插曲结束 –
之后我们使用beeline客户端来连接hive
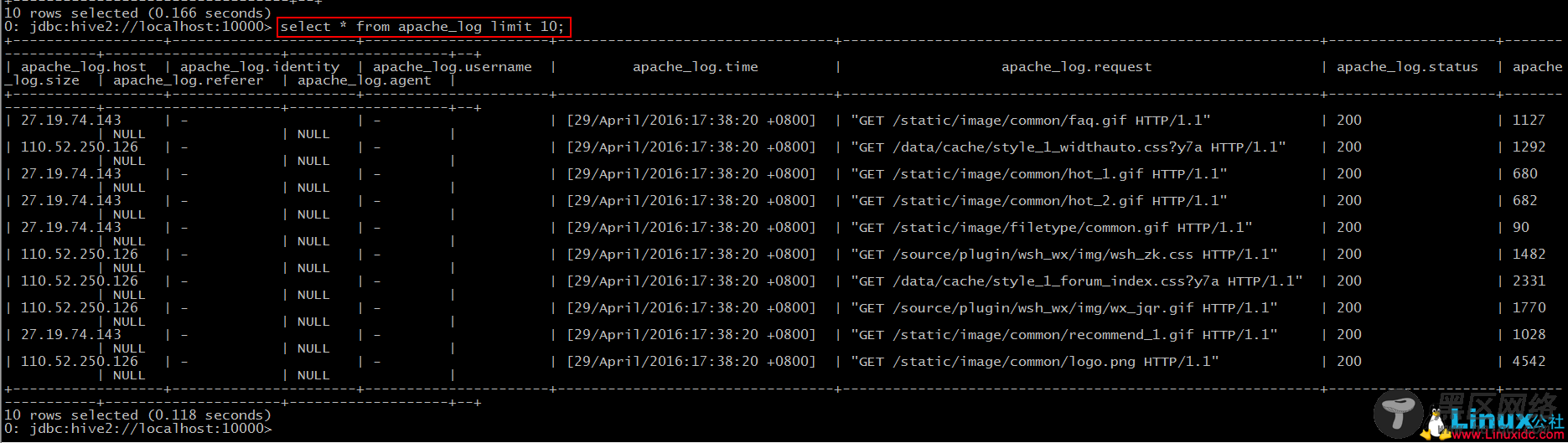
然后我们可以新建一个数据库,并使用之前的建表语句来创建”apache_log”,并导入数据(默认大家都会了^.^)。
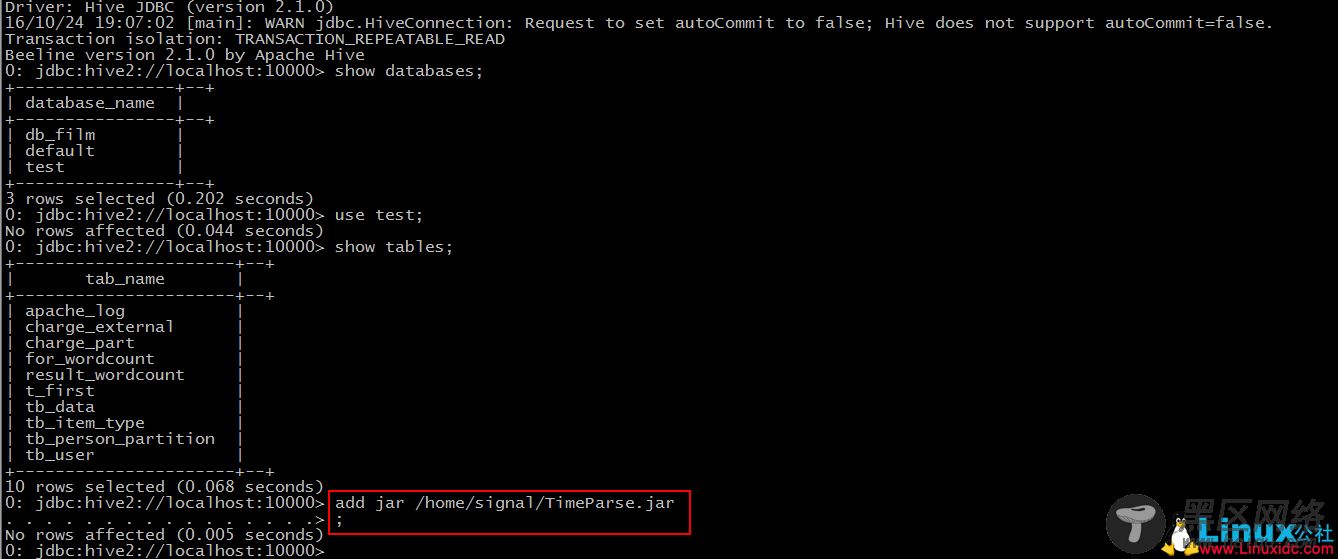
Step 1: add jar “jar-path”
Step 2: create function timeparse as ‘包名+类名’
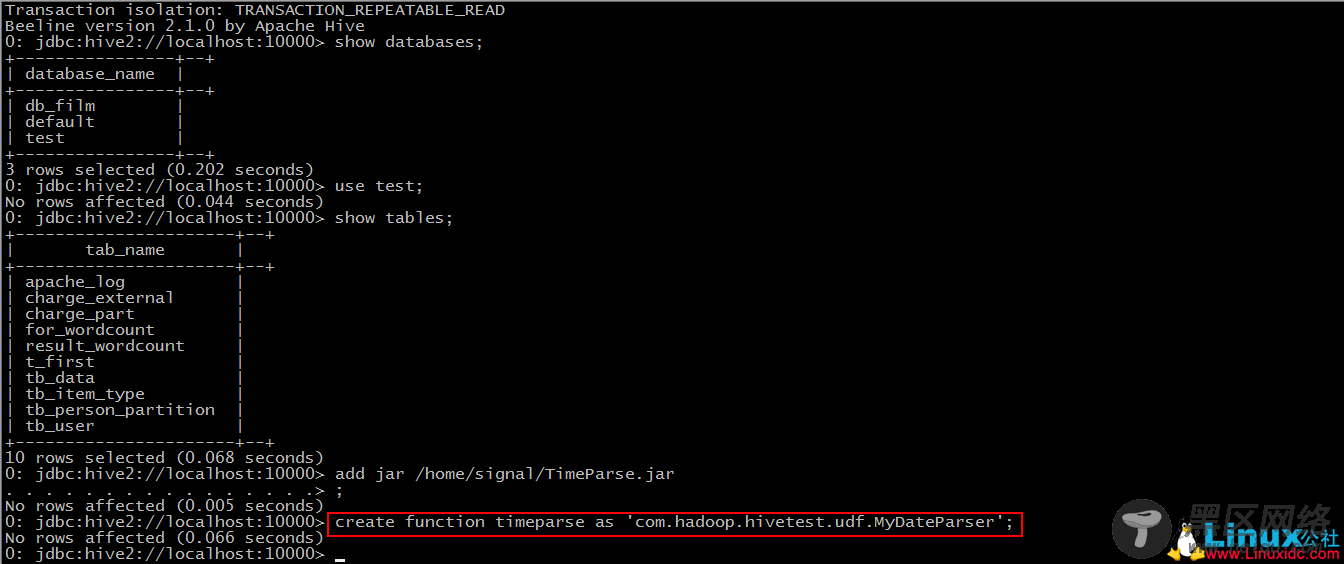
Step 3: 使用该函数
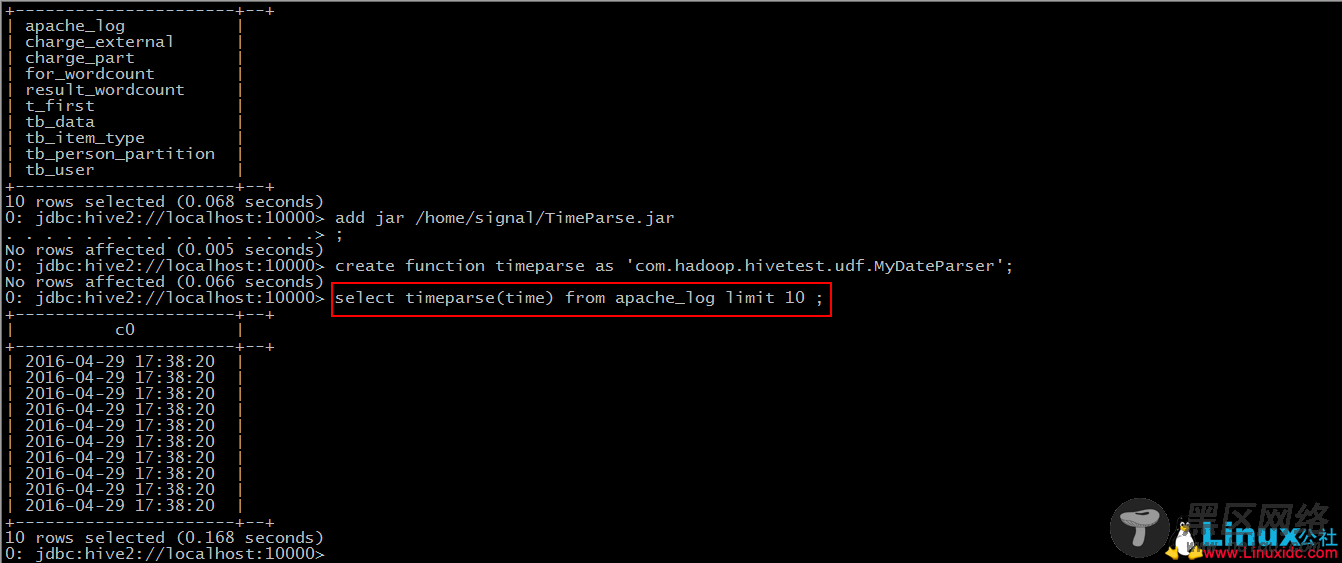
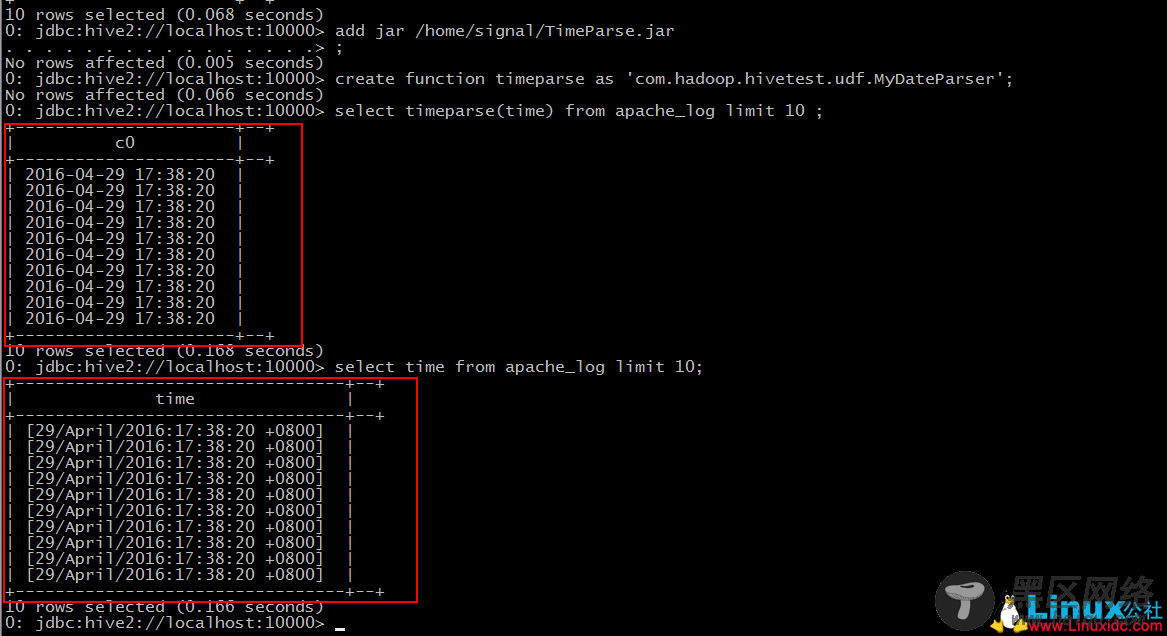
对比之前我们导入的数据
UDTF(user-defined table-generating functions)
“小”需求:
针对”request”字段,将其拆分,获取到用户的请求连接。
第一部分表示请求的方式,第二部分为用户请求的连接,第三部分为协及版本号。
要点:
1.继承自”org.apache.hadoop.hive.ql.udf.generic.GenericUDTF”;
2.实现initialize()、process()、close()三个方法。
*JAVA代码
package com.hadoop.hivetest.udf;
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyRequestParser extends GenericUDTF {
@Override
public StructObjectInspector initialize(ObjectInspector[] arg0) throws UDFArgumentException {
if(arg0.length != 1){
throw new UDFArgumentException("参数不正确。");
}
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
//添加返回字段设置
fieldNames.add("rcol1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("rcol2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("rcol3");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);