
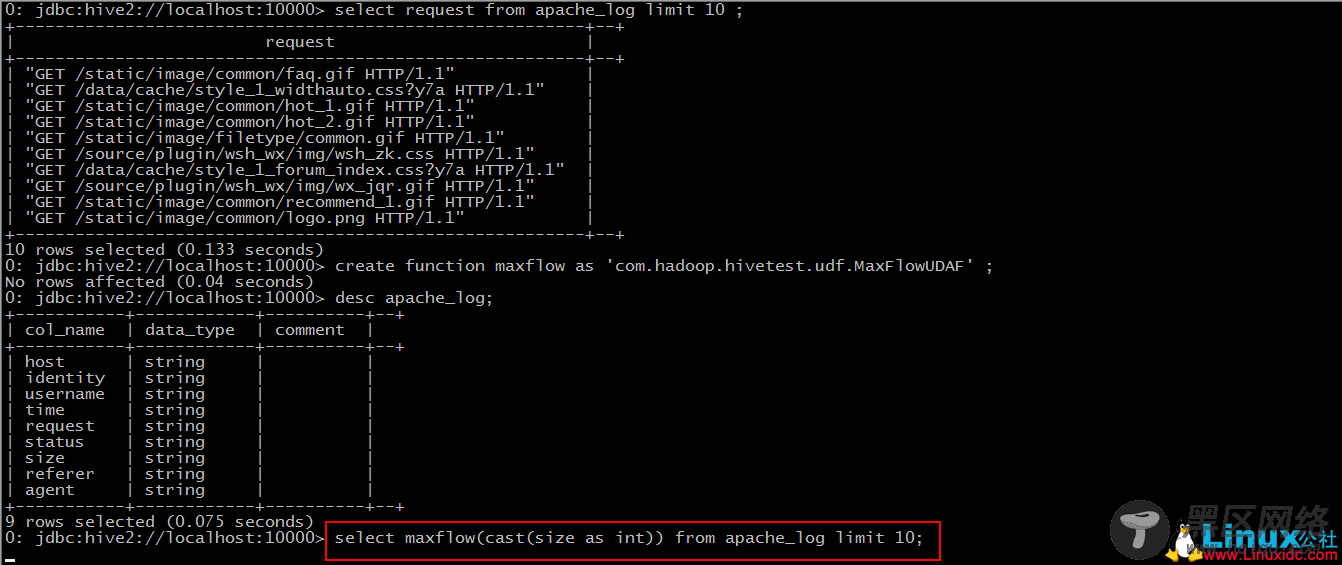
Step 3: 使用该函数
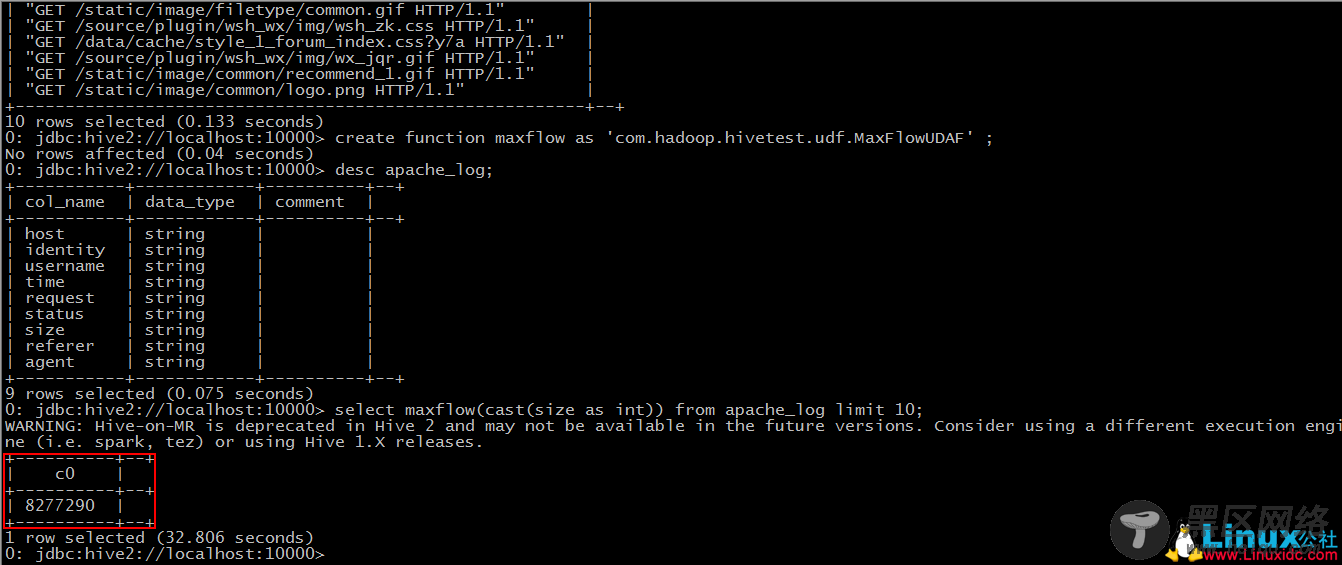
于是此时,hive便会将sql语句转换为mapreduce任务去执行了。
当我们创建函数之后,得出的结果却不是想要的结果的时候,我们将Java代码修改之后,重新打了包上传过来,也重新加到了hive的classpath中,但是新创建出来的函数得出的结果跟修改之前的一样。这个因为新修改过后的类名与之前的类名重复了,在当前session中会优先以之前的来创建函数。此时有两种办法解决,一是断开当前的连接,重新使用beeline客户端登陆一次,还有就是将修改后的Java类改一个名称,重新导入,使用新的Java类来创建函数。
当然,这些才都只是 UDF 的小皮毛,我们可以发现,通过自定义函数,我们可以省去写很多sql,并且通过使用api,我们可以更随意的操作数据库里的字段,实现多种计算和统计。
Hive编程指南 PDF 中文高清版 https://www.linuxidc.com/Linux/2015-01/111837.htm
基于Hadoop集群的Hive安装 https://www.linuxidc.com/Linux/2013-07/87952.htm
Hive内表和外表的区别 https://www.linuxidc.com/Linux/2013-07/87313.htm
Hadoop + Hive + Map +reduce 集群安装部署 https://www.linuxidc.com/Linux/2013-07/86959.htm
Hive本地独立模式安装 https://www.linuxidc.com/Linux/2013-06/86104.htm
Hive学习之WordCount单词统计 https://www.linuxidc.com/Linux/2013-04/82874.htm
Hive运行架构及配置部署 https://www.linuxidc.com/Linux/2014-08/105508.htm
Hive 2.1.1安装配置详解 https://www.linuxidc.com/Linux/2017-04/143053.htm
Hive安装及与HBase的整合 https://www.linuxidc.com/Linux/2016-12/138721.htm