//将返回字段设置到该UDTF的返回值类型中
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void close() throws HiveException {
}
//处理函数的输入并且输出结果的过程
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
input = input.replace("\"", "");
String[] result = input.split(" ");
//如果解析错误或失败,则返回三个字段内容都是"--"
if(result.length != 3){
result[0] = "--";
result[1] = "--";
result[2] = "--";
}
forward(result);
}
}
依照上面的步骤,导出jar包,上传到Linux服务器上。在此不再赘述,其实是攒着另一种上传文件的方式,下次教给大家。
Step 1: add jar “jar-path”
略
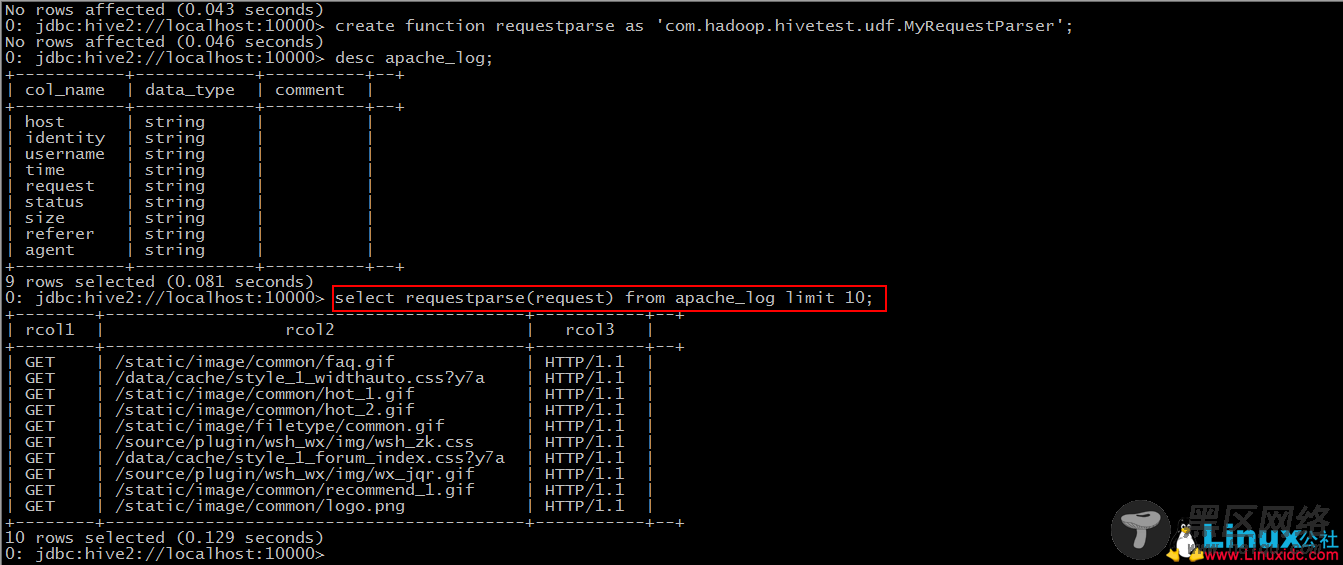
Step 2: create function requestparse as ‘包名+类名’

Step 3: 使用该函数
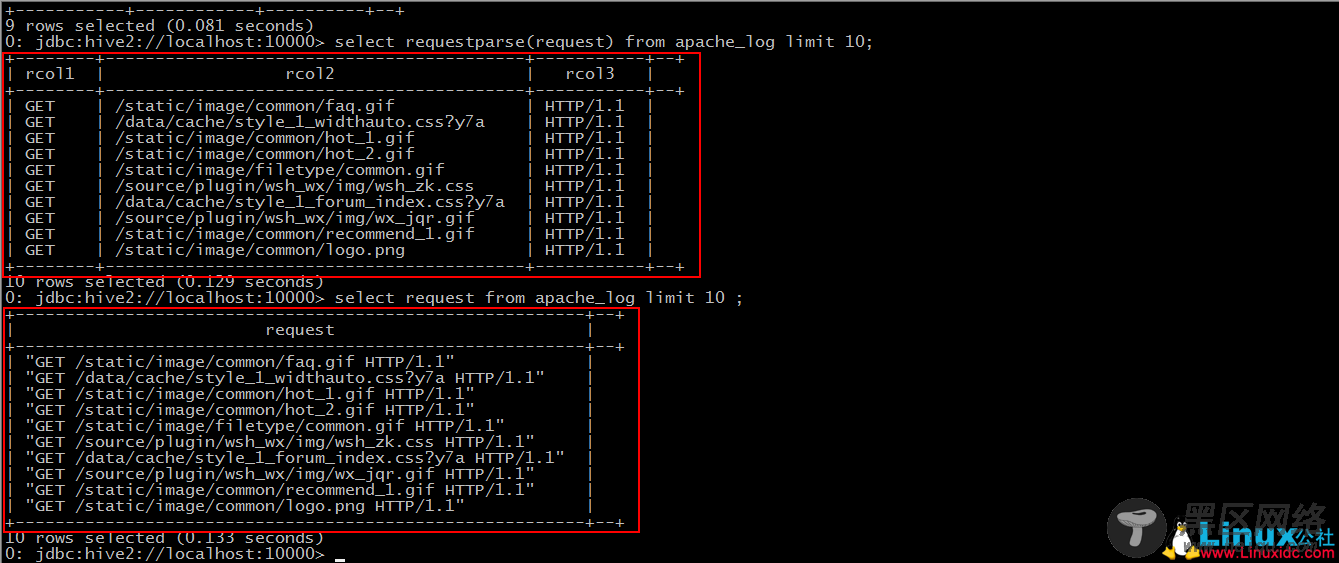
对比我们之前导入的数据
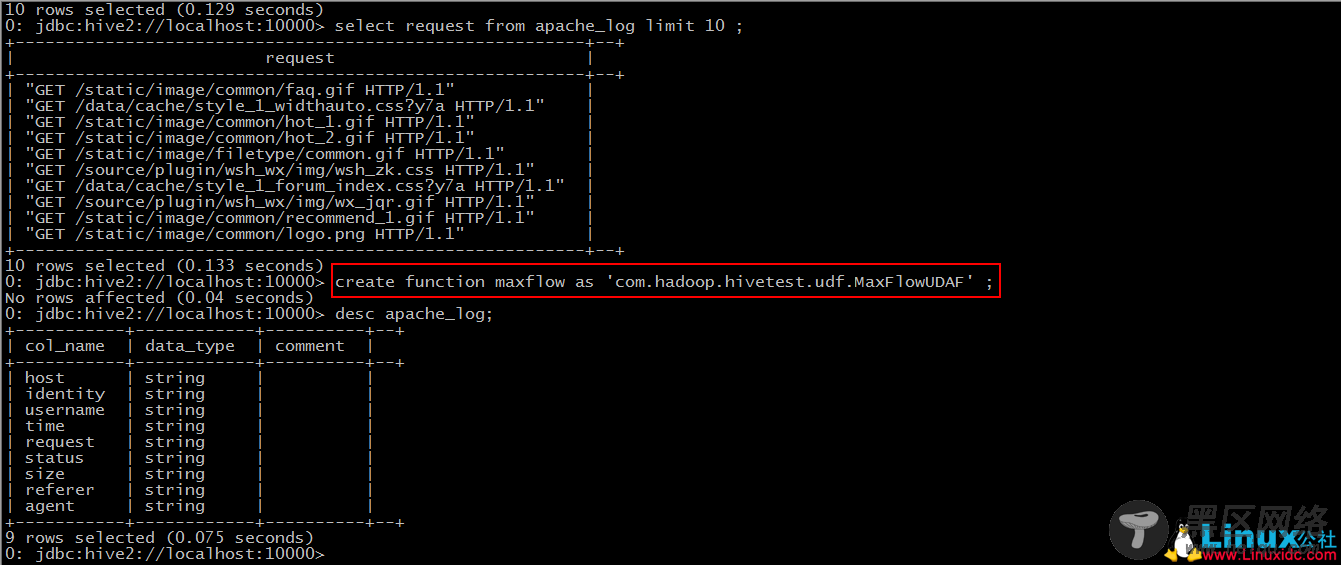
UDAF(user-defined aggregation functions)
“小”需求:
求出最大的流量值
要点:
1.继承自”org.apache.hadoop.hive.ql.exec.UDAF”;
2.自定义的内部类要实现接口”org.apache.hadoop.hive.ql.exec.UDAFEvaluator”;
3.要实现iterate()、terminatePartial()、merge()、terminate()四个方法。
*JAVA代码
package com.hadoop.hivetest.udf;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable;
@SuppressWarnings("deprecation")
public class MaxFlowUDAF extends UDAF {
public static class MaxNumberUDAFEvaluator implements UDAFEvaluator{
private IntWritable result;
public void init() {
result = null;
}
//聚合的多行中每行的被聚合的值都会被调用interate方法,所以这个方法里面我们来定义聚合规则
public boolean iterate(IntWritable value){
if(value == null){
return false;
}
if(result == null){
result = new IntWritable(value.get());
}else{
//需求是求出流量最大值,在这里进行流量的比较,将最大值放入result
result.set(Math.max(result.get(), value.get()));
}
return true;
}
//hive需要部分聚合结果时会调用该方法,返回当前的result作为hive取部分聚合值得结果
public IntWritable terminatePartial(){
return result;
}
//聚合值,新行未被处理的值会调用merge加入聚合,这里直接调用上面定义的聚合规则方法iterate
public boolean merge(IntWritable other){
return iterate(other);
}
//hive需要最后总聚合结果时调用的方法,返回聚合的最终结果
public IntWritable terminate(){
return result;
}
}
}
导出jar包,上传到Linux服务器…
Step 1: add jar ‘jar-path’
略
Step 2: create function maxflow as ‘包名+类名’