
随着阿里巴巴Blink的开源,Flink中国社区开始活跃起来。很多人会开始对各种计算平台进行对比,比如Storm、Spark、JStorm、Flink等,并且有人提到之前阿里巴巴开源的JStorm比Flink性能高出10-15倍,为什么阿里巴巴却转战基于Flink的Blink呢? 在最近Flink的线下技术会议上,阿里巴巴的人已经回答了这一问题。其实很多技术都是从业务实战出来的,随着业务的发展可能还会有更多的计算平台出现,没有必要对此过多纠结。
不过,既然大家最近讨论得这么火热,这里也列出一些最近问的比较多的、有代表性的关于Beam的问题,逐一进行回答。
1. Flink支持SQL,请问Beam支持吗?
现在Beam是支持SQL处理的,底层技术跟Flink底层处理是一样的。
Beam SQL现在只支持Java,底层是Apache Calcite 的一个动态数据管理框架,用于大数据处理和一些流增强功能,它允许你自定义数据库功能。例如Hive 使用了Calcite的查询优化,当然还有Flink解析和流SQL处理。Beam在这之上添加了额外的扩展,以便轻松利用Beam的统一批处理/流模型以及对复杂数据类型的支持。 以下是Beam SQL具体处理流程图:
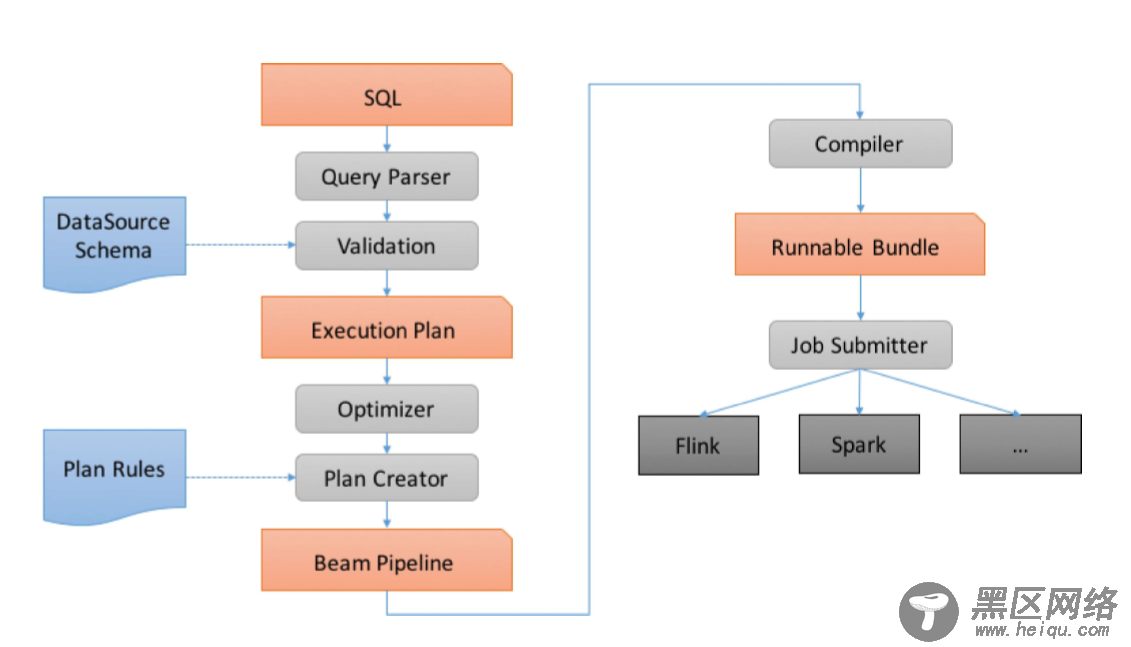
Beam SQL一共有两个比较重要的概念:
SqlTransform:用于PTransforms从SQL查询创建的接口。
Row:Beam SQL操作的元素类型。例如:PCollection<Row>。
在将SQL查询应用于PCollection 之前,集合中Row的数据格式必须要提前指定。 一旦Beam SQL 指定了 管道中的类型是不能再改变的。PCollection行中字段/列的名称和类型由Schema进行关联定义。您可以使用Schema.builder()来创建 Schemas。
示例:
// Define the schema for the records. Schema appSchema = Schema .builder() .addInt32Field("appId") .addStringField("description") .addDateTimeField("rowtime") .build(); // Create a concrete row with that type. Row row = Row .withSchema(appSchema) .addValues(1, "Some cool app", new Date()) .build(); // Create a source PCollection containing only that row PCollection<Row> testApps = PBegin .in(p) .apply(Create .of(row) .withCoder(appSchema.getRowCoder()));也可以是其他类型,不是直接是Row,利用PCollection<T>通过应用ParDo可以将输入记录转换为Row格式。如:
// An example POJO class. class AppPojo { Integer appId; String description; Date timestamp; } // Acquire a collection of POJOs somehow. PCollection<AppPojo> pojos = ... // Convert them to Rows with the same schema as defined above via a DoFn. PCollection<Row> apps = pojos .apply( ParDo.of(new DoFn<AppPojo, Row>() { @ProcessElement public void processElement(ProcessContext c) { // Get the current POJO instance AppPojo pojo = c.element(); // Create a Row with the appSchema schema // and values from the current POJO Row appRow = Row .withSchema(appSchema) .addValues( pojo.appId, pojo.description, pojo.timestamp) .build(); // Output the Row representing the current POJO c.output(appRow); } }));2. Flink 有并行处理,Beam 有吗?
Beam 在抽象Flink的时候已经把这个参数抽象出来了,在Beam Flink 源码解析中会提到。
3. 我这里有个流批混合的场景,请问Beam是不是支持?
这个是支持的,因为批也是一种流,是一种有界的流。Beam 结合了Flink,Flink dataset 底层也是转换成流进行处理的。
4. Flink流批写程序的时候和Beam有什么不同?底层是Flink还是Beam?