4)编写以下代码:
public static void main(String[] args) { //创建管道工厂 PipelineOptions options = PipelineOptionsFactory.create(); // 显式指定PipelineRunner:FlinkRunner必须指定如果不制定则为本地 options.setRunner(FlinkRunner.class); //设置相关管道 Pipeline pipeline = Pipeline.create(options); //这里kV后说明kafka中的key和value均为String类型 PCollection<KafkaRecord<String, String>> lines = pipeline.apply(KafkaIO.<String, // 必需设置kafka的服务器地址和端口 String>read().withBootstrapServers("192.168.1.110:11092,192.168.1.119:11092,192.168.1.120:11092") .withTopic("testmsg")// 必需设置要读取的kafka的topic名称 .withKeyDeserializer(StringDeserializer.class)// 必需序列化key .withValueDeserializer(StringDeserializer.class)// 必需序列化value .updateConsumerProperties(ImmutableMap.<String, Object>of("auto.offset.reset", "earliest")));//这个属性kafka最常见的. // 为输出的消息类型。或者进行处理后返回的消息类型 PCollection<String> kafkadata = lines.apply("Remove Kafka Metadata", ParDo.of(new DoFn<KafkaRecord<String, String>, String>() { private static final long serialVersionUID = 1L; @ProcessElement public void processElement(ProcessContext ctx) { System.out.print("输出的分区为----:" + ctx.element().getKV()); ctx.output(ctx.element().getKV().getValue());// 其实我们这里是把"张海 涛在发送消息***"进行返回操作 } })); PCollection<String> windowedEvents = kafkadata.apply(Window.<String>into(FixedWindows.of(Duration.standardSeconds(5)))); PCollection<KV<String, Long>> wordcount = windowedEvents.apply(Count.<String>perElement()); // 统计每一个kafka消息的Count PCollection<String> wordtj = wordcount.apply("ConcatResultKVs", MapElements.via( // 拼接最后的格式化输出(Key为Word,Value为Count) new SimpleFunction<KV<String, Long>, String>() { private static final long serialVersionUID = 1L; @Override public String apply(KV<String, Long> input) { System.out.print("进行统计:" + input.getKey() + ": " + input.getValue()); return input.getKey() + ": " + input.getValue(); } })); wordtj.apply(KafkaIO.<Void, String>write() .withBootstrapServers("192.168.1.110:11092,192.168.1.119:11092,192.168.1.120:11092")//设置写会kafka的集群配置地址 .withTopic("senkafkamsg")//设置返回kafka的消息主题 // .withKeySerializer(StringSerializer.class)//这里不用设置了,因为上面 Void .withValueSerializer(StringSerializer.class) // Dataflow runner and Spark 兼容, Flink 对kafka0.11才支持。我的版本是0.10不兼容 //.withEOS(20, "eos-sink-group-id") .values() // 只需要在此写入默认的key就行了,默认为null值 ); // 输出结果 pipeline.run().waitUntilFinish(); }5)打包jar,本示例是简单的实战,并没有用Docker,Apache Beam新版本是支持Docker的。
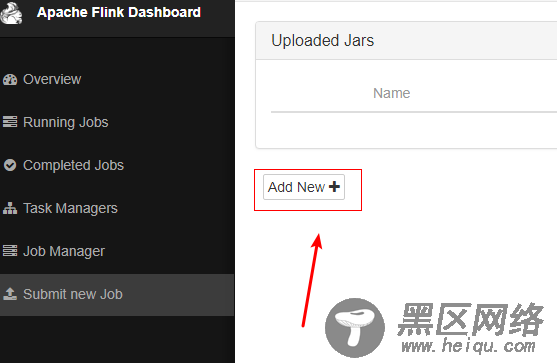
6)通过Apache Flink Dashboard 提交job
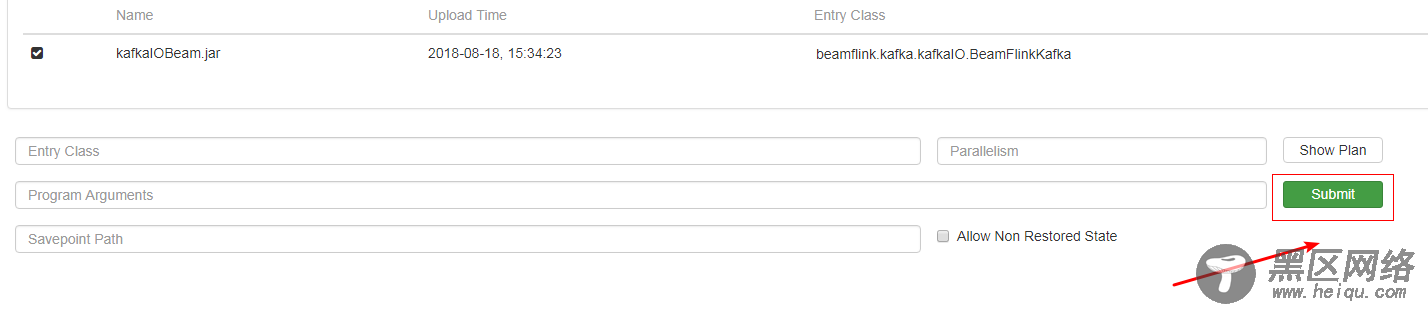
7)查看结果
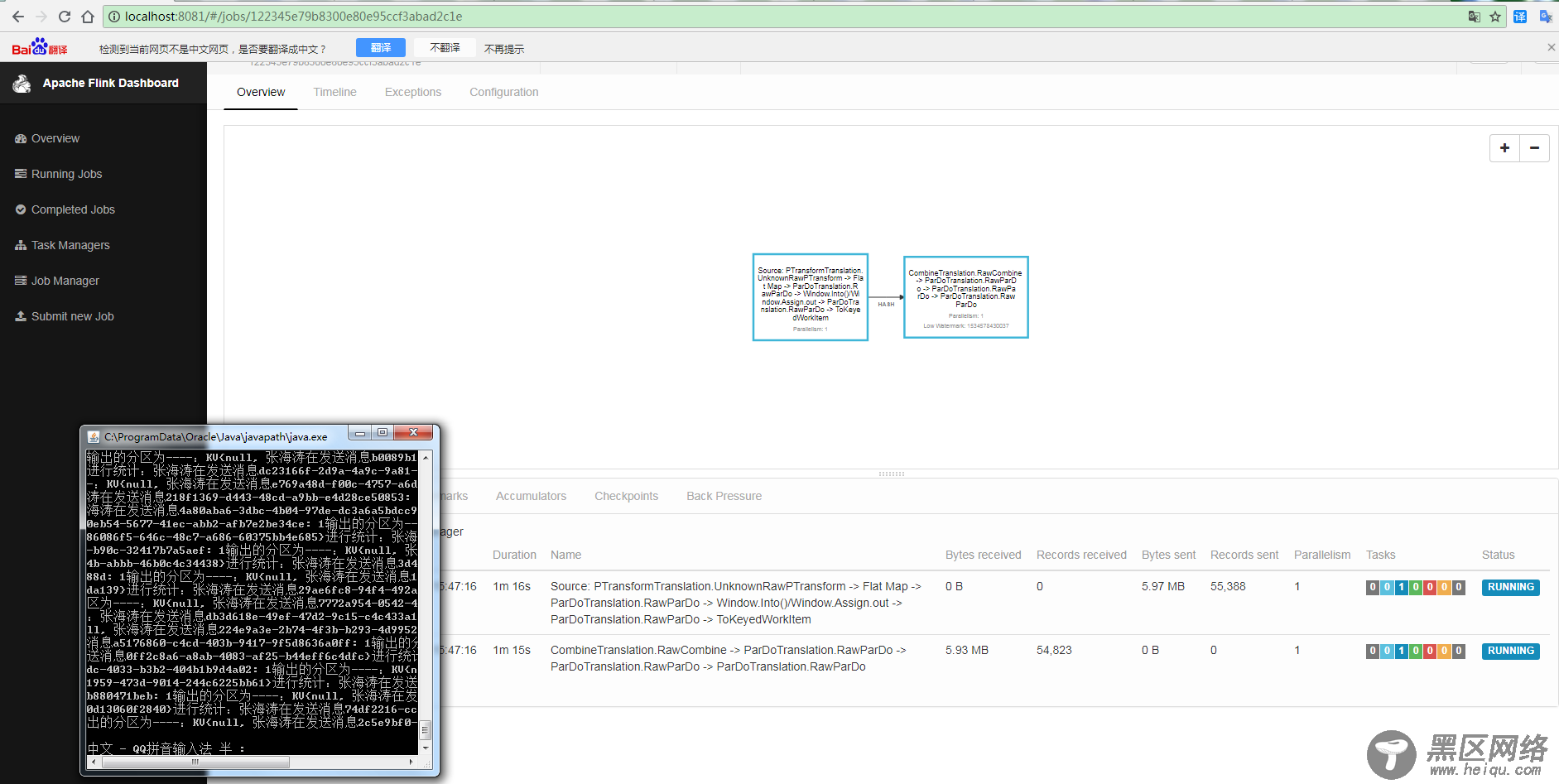
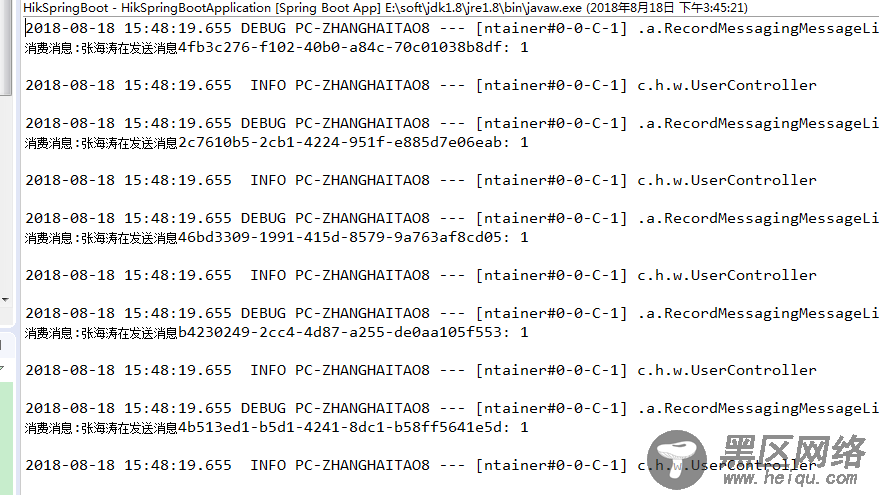
程序接收的日志如下: