接着在 Slave01和 Slave02 节点上,将 ssh 公匙加入授权:
$ mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略 $ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys这样,在 Master 节点上就可以无密码 SSH 到各个 Slave 节点了���可在 Master 节点上执行如下命令进行检验,如下图所示变为 Slave01了,再按 exit 可退回到 Master:
至此网络配置完成。
安装 Hadoop去到镜像站 https://archive.apache.org/dist/hadoop/core/ 下载,我下载的是 hadoop-2.8.4.tar.gz 。在 Master 节点上执行:
$ sudo tar -zxf /home/ubuntu/hadoop-2.8.4.tar.gz -C /usr/lib # 解压到/usr/lib中 $ cd /usr/lib/ $ sudo mv ./hadoop-2.8.4/ ./hadoop # 将文件夹名改为hadoop $ sudo chown -R hadoop ./hadoop # 修改文件权限将 hadoop 目录加到环境变量,这样就可以在任意目录中直接使用 hadoop、hdfs 等命令。执行 vim ~/.bashrc ,加入一行:
export PATH=$PATH:/usr/lib/hadoop/bin:/usr/lib/hadoop/sbin保存后执行 source ~/.bashrc 使配置生效。
完成后开始修改 Hadoop 配置文件(这里也顺便配置了 Yarn),先执行 cd /usr/lib/hadoop/etc/hadoop ,共有 6 个需要修改 —— hadoop-env.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1、文件 hadoop-env.sh 中把 export JAVA_HOME=${JAVA_HOME} 修改为 export JAVA_HOME=/usr/lib/java ,即 Java 安装路径。
2、 文件 slaves 把里面的 localhost 改为 Slave01和 Slave02 。

3、core-site.xml 改为如下配置:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/lib/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>4、hdfs-site.xml 改为如下配置:
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:50090</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/lib/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/lib/hadoop/tmp/dfs/data</value> </property> </configuration>5、文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template):
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master:19888</value> </property> </configuration>6、文件 yarn-site.xml :
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>配置好后,将 Master 上的 /usr/lib/hadoop 文件夹复制到各个 slave 节点上。在 Master 节点上执行:
$ cd /usr/lib $ tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制 $ scp ~/hadoop.master.tar.gz Slave01:/home/hadoop $ scp ~/hadoop.master.tar.gz Slave02:/home/hadoop分别在两个 slave 节点上执行:
$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/lib $ sudo chown -R hadoop /usr/lib/hadoop安装完成后,首次启动需要先在 Master 节点执行 NameNode 的格式化:
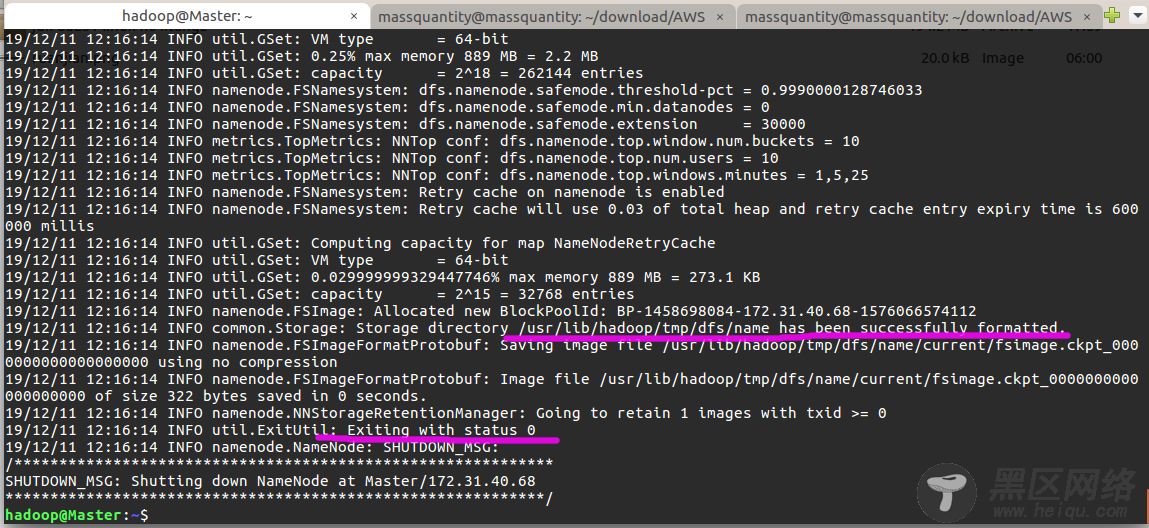
$ hdfs namenode -format # 首次运行需要执行初始化,之后不需要成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
接着可以启动 Hadoop 和 Yarn 了,启动需要在 Master 节点上进行:
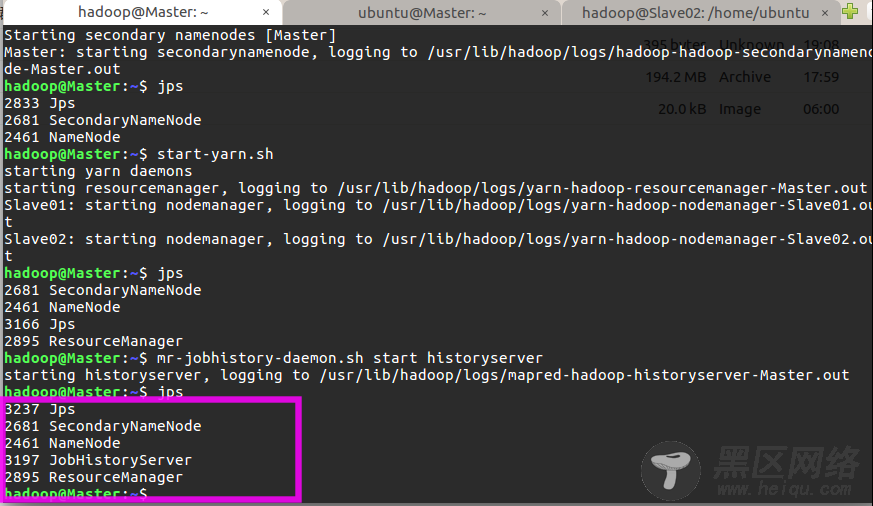
$ start-dfs.sh $ start-yarn.sh $ mr-jobhistory-daemon.sh start historyserver通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示: