
通过命令 hdfs dfsadmin -report 可查看集群状态,其中 Live datanodes (2) 表明两个从节点都已正常启动,如果是 0 则表示不成功:

可以通过下列三个地址查看 hadoop 的 web UI,其中 ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com 是该实例的外部 DNS 主机名,50070、8088、19888 分别是 hadoop、yarn、JobHistoryServer 的默认端口:
ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:50070 ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:8088 ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:19888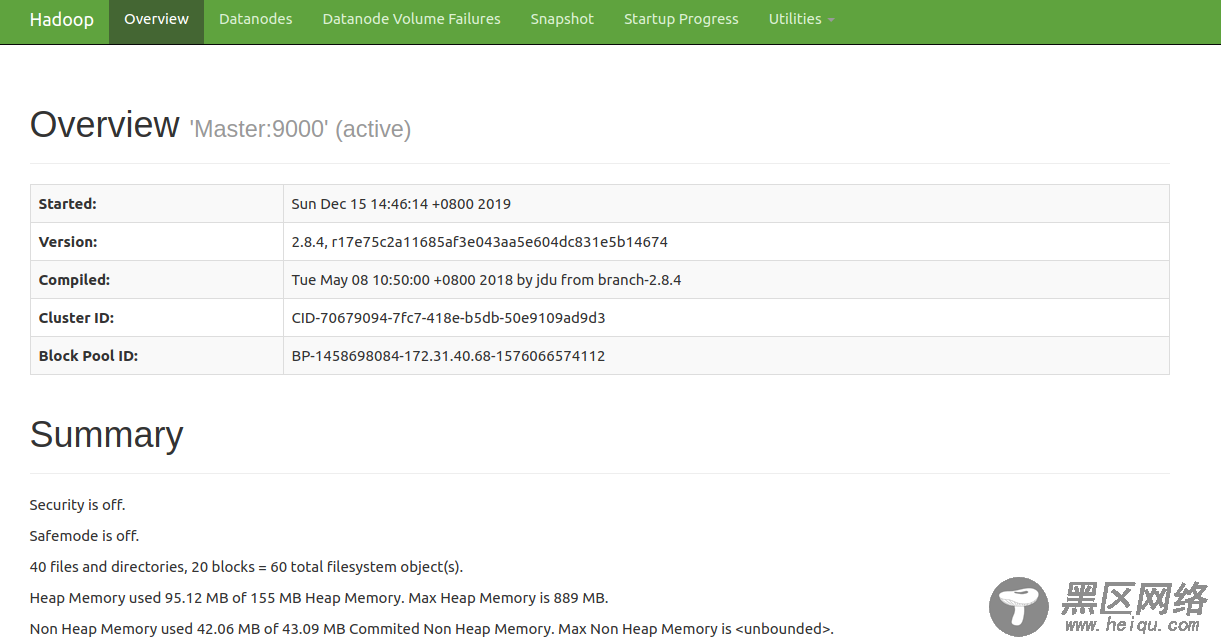
如果成功可以看到以下输出:
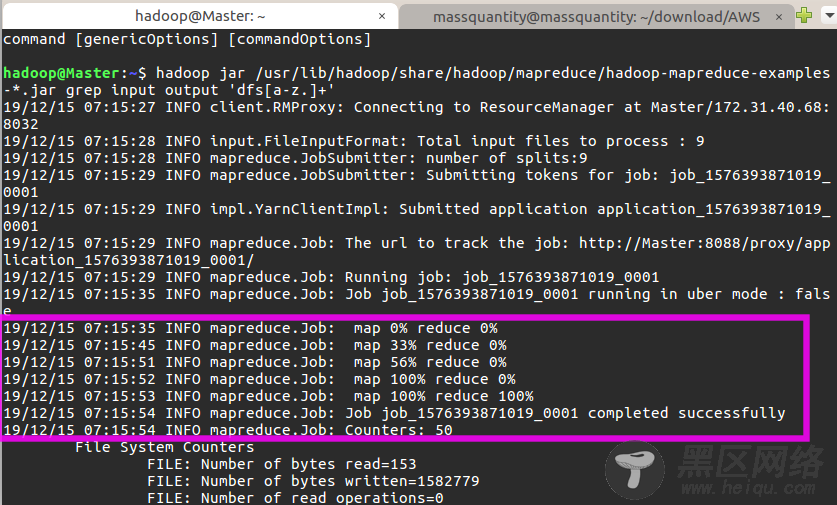

最后关闭 Hadoop 集群需要执行以下命令:
$ stop-yarn.sh $ stop-dfs.sh $ mr-jobhistory-daemon.sh stop historyserver 安装 Spark去到镜像站 https://archive.apache.org/dist/spark/ 下载,由于之前已经安装了Hadoop,所以我下载的是无 Hadoop 版本的,即 spark-2.3.3-bin-without-hadoop.tgz 。在 Master 节点上执行:
$ sudo tar -zxf /home/ubuntu/spark-2.3.3-bin-without-hadoop.tgz -C /usr/lib # 解压到/usr/lib中 $ cd /usr/lib/ $ sudo mv ./spark-2.3.3-bin-without-hadoop/ ./spark # 将文件夹名改为spark $ sudo chown -R hadoop ./spark # 修改文件权限将 spark 目录加到环境变量,执行 vim ~/.bashrc 添加如下配置:
export SPARK_HOME=/usr/lib/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin保存后执行 source ~/.bashrc 使配置生效。
接着需要配置了两个文件,先执行 cd /usr/lib/spark/conf 。
1、 配置 slaves 文件
mv slaves.template slaves # 将slaves.template重命名为slavesslaves文件设置从节点。编辑 slaves 内容,把默认内容localhost替换成两个从节点的名字:
Slave01 Slave022、配置 spark-env.sh 文件
mv spark-env.sh.template spark-env.sh编辑 spark-env.sh 添加如下内容:
export SPARK_DIST_CLASSPATH=$(/usr/lib/hadoop/bin/hadoop classpath) export HADOOP_CONF_DIR=/usr/lib/hadoop/etc/hadoop export SPARK_MASTER_IP=172.31.40.68 # 注意这里填的是Master节点的私有IP export JAVA_HOME=/usr/lib/java配置好后,将 Master 上的 /usr/lib/spark 文件夹复制到各个 slave 节点上。在 Master 节点上执行:
$ cd /usr/lib $ tar -zcf ~/spark.master.tar.gz ./spark $ scp ~/spark.master.tar.gz Slave01:/home/hadoop $ scp ~/spark.master.tar.gz Slave02:/home/hadoop然后分别在两个 slave 节点上执行:
$ sudo tar -zxf ~/spark.master.tar.gz -C /usr/lib $ sudo chown -R hadoop /usr/lib/spark在启动 Spark 集群之前,先确保启动了 Hadoop 集群:
$ start-dfs.sh $ start-yarn.sh $ mr-jobhistory-daemon.sh start historyserver $ start-master.sh # 启动 spark 主节点 $ start-slaves.sh # 启动 spark 从节点可通过 ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:8080 访问 spark web UI 。

1、通过命令行提交 JAR 包:
$ spark-submit --class org.apache.spark.examples.SparkPi --master spark://Master:7077 /usr/lib/spark/examples/jars/spark-examples_2.11-2.3.3.jar 100 2>&1 | grep "Pi is roughly"结果如下说明成功:

2、通过 IDEA 远程连接运行程序:
可以在 本地 IDEA 中编写代码,远程提交到云端机上执行,这样比较方便调试。需要注意的是 Master 地址填云端机的公有 IP 地址。下面以一个 WordVec 程序示例,将句子转换为向量形式:
import org.apache.spark.{SparkConf, SparkContext} import org.apache.log4j.{Level, Logger} import org.apache.spark.ml.feature.Word2Vec import org.apache.spark.ml.linalg.Vector import org.apache.spark.sql.Row import org.apache.spark.sql.SparkSession object Word2Vec { def main(args: Array[String]) { Logger.getLogger("org").setLevel(Level.ERROR) // 控制输出信息 Logger.getLogger("com").setLevel(Level.ERROR) val conf = new SparkConf() .setMaster("spark://ec2-54-190-51-132.us-west-2.compute.amazonaws.com:7077") // 填公有DNS或公有IP地址都可以 .setAppName("Word2Vec") .set("spark.cores.max", "4") .set("spark.executor.memory", "2g") val sc = new SparkContext(conf) val spark = SparkSession .builder .appName("Word2Vec") .getOrCreate() val documentDF = spark.createDataFrame(Seq( "Hi I heard about Spark".split(" "), "I wish Java could use case classes".split(" "), "Logistic regression models are neat".split(" ") ).map(Tuple1.apply)).toDF("text") val word2Vec = new Word2Vec() .setInputCol("text") .setOutputCol("result") .setVectorSize(3) .setMinCount(0) val model = word2Vec.fit(documentDF) val result = model.transform(documentDF) result.collect().foreach { case Row(text: Seq[_], features: Vector) => println(s"Text: [${text.mkString(", ")}] => \nVector: $features\n") } } }IDEA 控制台输出:

关闭 Spark 和 Hadoop 集群有以下命令:
$ stop-master.sh $ stop-slaves.sh $ stop-yarn.sh $ stop-dfs.sh $ mr-jobhistory-daemon.sh stop historyserver