现在可以启动 Hadoop 了,这实际上要启动每个 Hadoop 守护进程。但是,首先使用 hadoop 命令对 Hadoop File System (HDFS) 进行格式化。hadoop 命令有许多用途,稍后讨论其中一部分。
首先,请求 namenode 对 DFS 文件系统进行格式化。在安装过程中完成了这个步骤,但是了解是否需要生成干净的文件系统是有用的。
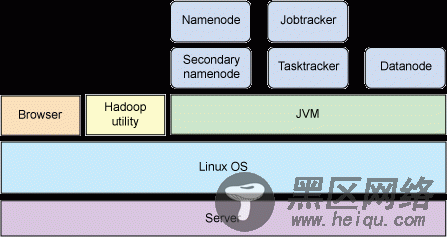
# hadoop-0.20 namenode -format在确认请求之后,文件系统进行格式化并返回一些信息。接下来,启动 Hadoop 守护进程。Hadoop 在这个伪分布式配置中启动 5 个守护进程:namenode、secondarynamenode、datanode、jobtracker 和 tasktracker。在启动每个守护进程时,会看到一些相关信息(指出存储日志的位置)。每个守护进程都在后台运行。图 1 说明完成启动之后伪分布式配置的架构。
图 1. 伪分布式 Hadoop 配置
Hadoop 提供一些简化启动的辅助工具。这些工具分为启动(比如 start-dfs)和停止(比如 stop-dfs)两类。下面的简单脚本说明如何启动 Hadoop 节点:
# /usr/lib/hadoop-0.20/bin/start-dfs.sh # /usr/lib/hadoop-0.20/bin/start-mapred.sh #要想检查守护进程是否正在运行,可以使用 jps 命令(这是用于 JVM 进程的 ps 实用程序)。这个命令列出 5 个守护进程及其进程标识符。
既然 Hadoop 守护进程已经在运行了,现在看看每个守护进程在 Hadoop 框架中的作用。namenode 是 Hadoop 中的主服务器,它管理文件系统名称空间和对集群中存储的文件的访问。还有一个 secondary namenode,它不是 namenode 的冗余守护进程,而是提供周期检查点和清理任务。在每个 Hadoop 集群中可以找到一个 namenode 和一个 secondary namenode。
datanode 管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode 守护进程。
最后,每个集群有一个 jobtracker,它负责调度 datanode 上的工作。每个 datanode 有一个 tasktracker,它们执行实际工作。jobtracker 和 tasktracker 采用主-从形式,jobtracker 跨 datanode 分发工作,而 tasktracker 执行任务。jobtracker 还检查请求的工作,如果一个 datanode 由于某种原因失败,jobtracker 会重新调度以前的任务。
在这个简单的配置中,所有节点都驻留在同一个主机上(见 图 1)。但是,通过前面的讨论很容易看出 Hadoop 如何提供并行处理。尽管架构很简单,但是 Hadoop 能够方便地实现数据分发、负载平衡以及以容错的方式并行处理大量数据。