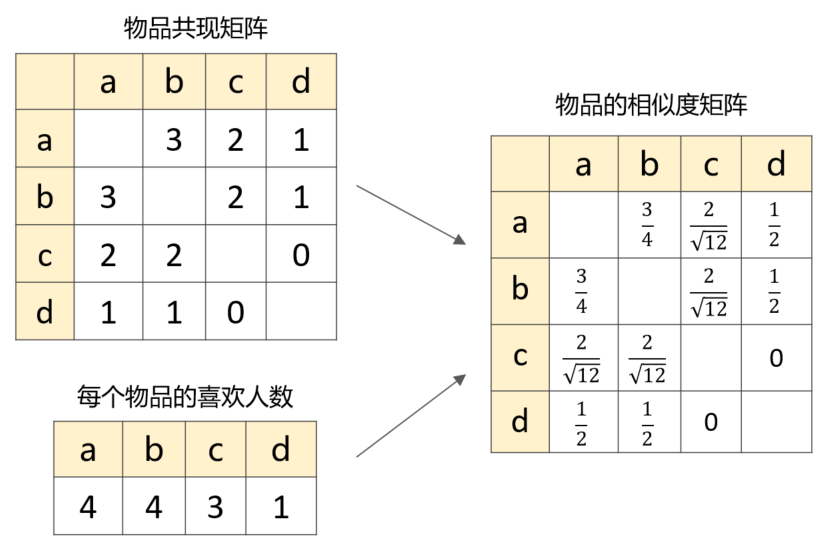
所谓共现,即:两个物品被同一个用户喜欢了。比如物品 a 和 b,由于他们同时被用户 A、B、C 喜欢,所以 a 和 b 的共现次数是3,采用这种统计方法就可以快速构建出共现矩阵。
第二步:计算物品的相似度矩阵
对于 Item-CF 算法来说,一般不采用前面提到的余弦距离来衡量物品的相似度,而是采用下面的公式 :
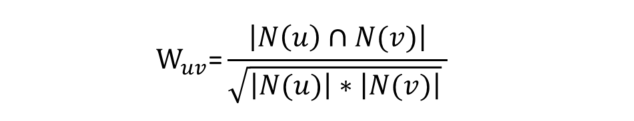
其中,N(u) 表示喜欢物品 u 的用户数,N(v) 表示喜欢物品 v 的用户数,两者的交集表示同时喜欢物品 u 和物品 v 的用户数。很显然,如果两个物品同时被很多人喜欢,那么这两个物品越相似。
基于第1步计算出来的共现矩阵以及每个物品的喜欢人数,便可以构造出物品的相似度矩阵:
第三步:推荐物品
最后一步,便可以基于相似度矩阵推荐物品了,公式如下:
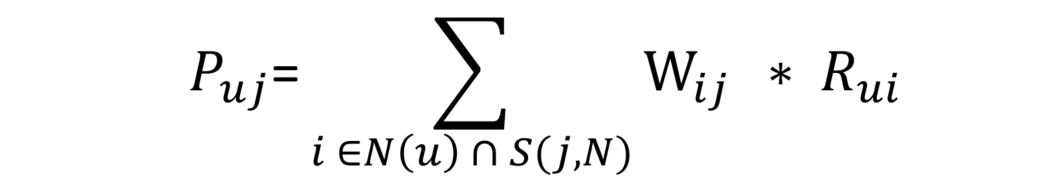
其中,P uj 表示用户 u 对物品 j 的感兴趣程度,值越大,越值得被推荐。N(u) 表示用户 u 感兴趣的物品集合,S(j,N) 表示和物品 j 最相似的前 N 个物品,W ij 表示物品 i 和物品 j 的相似度,R ui 表示用户 u 对物品 i 的兴趣度。
上面的公式有点抽象,直接看例子更容易理解,假设我要给用户 E 推荐物品,前面我们已经知道用户 E 喜欢物品 b 和物品 c,喜欢程度假设分别为 0.6 和 0.4。那么,利用上面的公式计算出来的推荐结果如下:
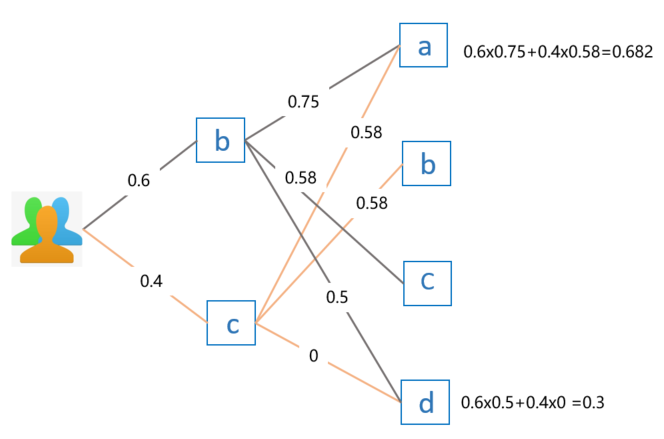
因为物品 b 和物品 c 已经被用户 E 喜欢过了,所以不再重复推荐。最终对比用户 E 对物品 a 和物品 d 的 感兴 趣程度,因为 0.682 > 0.3,因此选择推荐物品 a。
04 从0到1搭建一个推荐系统有了上面的理论基础后,我们就可以用 Python 快速实现出一个推荐系统。
1、选择数据集
这里采用的是推荐领域非常经典的 MovieLens 数据集,它是一个关于电影评分的数据集,官网上提供了多个不同大小的版本,下面以 ml-1m 数据集(大约100万条用户评分记录)为例。
下载解压后,文件夹中包含:ratings.dat、movies.dat、users.dat 3个文件,共6040个用户,3900部电影,1000209条评分记录。各个文件的格式都是一样的,每行表示一条记录,字段之间采用 :: 进行分割。
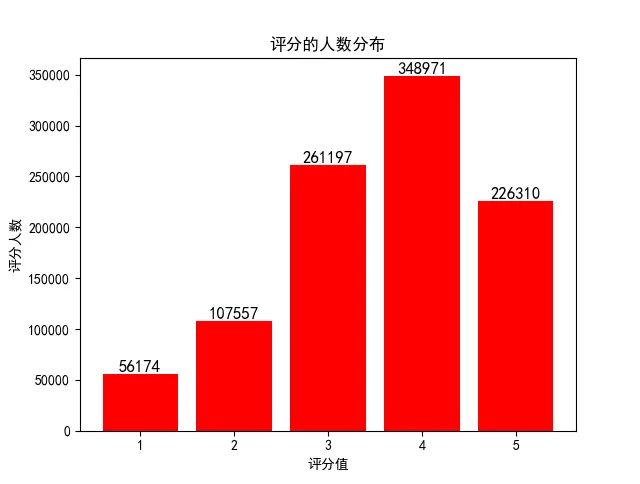
以ratings.dat为例,每一行包括4个属性: UserID, MovieID, Rating, Timestamp。 通过脚本可以统计出不同评分的人数分布:
2、读取原始数据
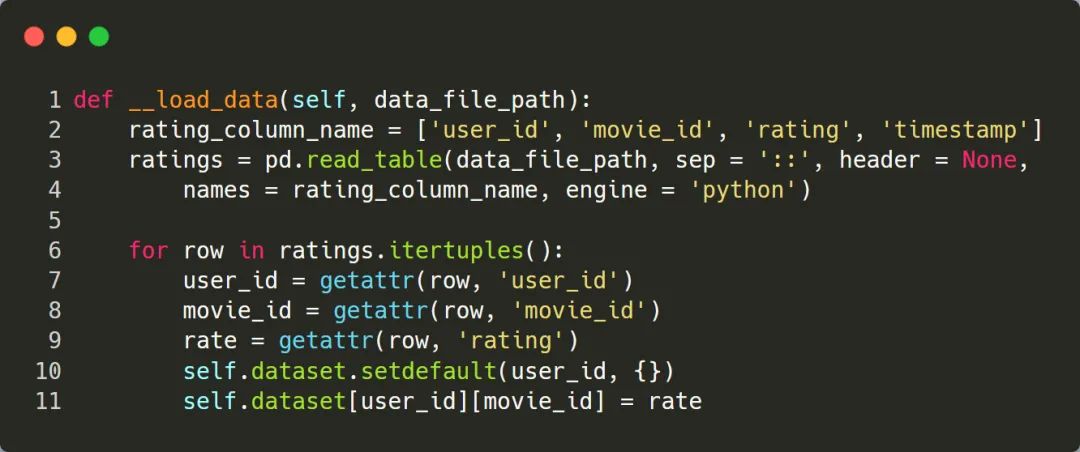
程序主要使用数据集中的 ratings.dat 这个文件,通过解析该文件,抽取出 user_id、movie_id、rating 3个字段,最终构造出算法依赖的数据,并保存在变量 dataset 中,它的格式为:dict[user_id][movie_id] = rate
3、 构造物品的相似度矩阵
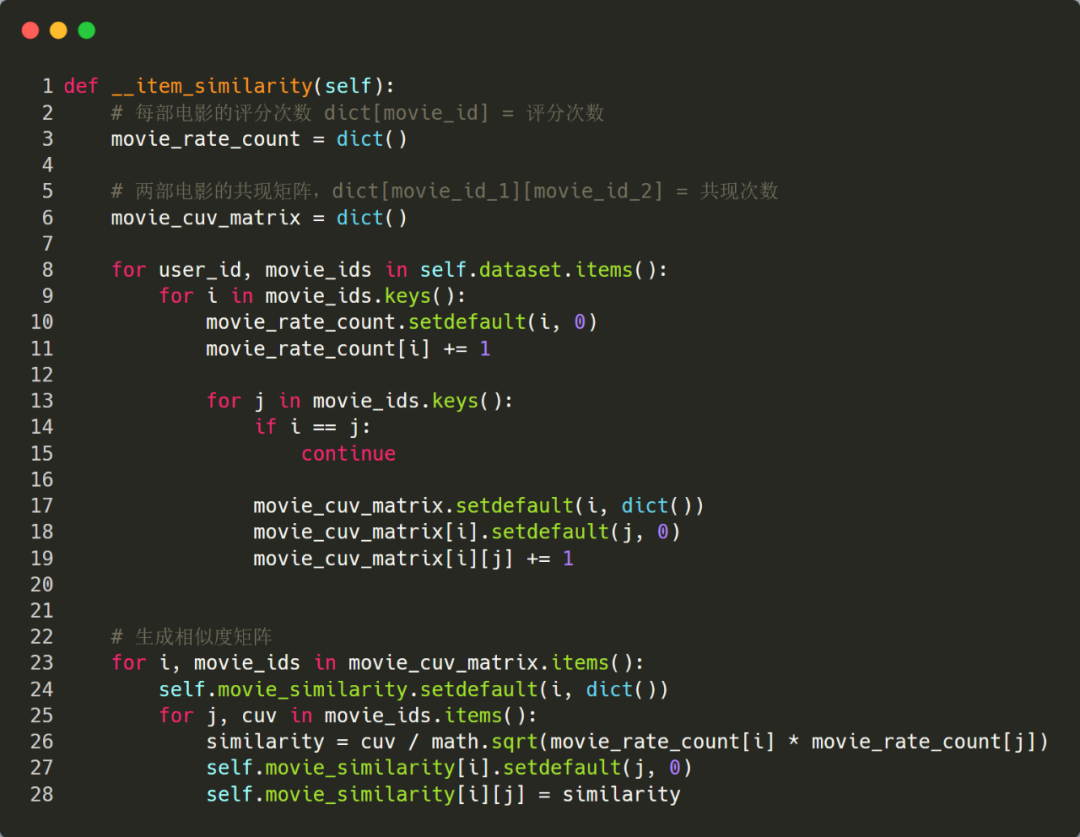
基于第 2 步的 dataset,可以进一步统计出每部电影的评分次数以及电影的共生矩阵,然后再生成相似度矩阵。
4、 基于相似度矩阵推荐物品
最后,可以基于相似度矩阵进行推荐了,输入一个用户id,先针对该用户评分过的电影,依次选出 top 10 最相似的电影,然后加权求和后计算出每个候选电影的最终评分,最后再选择得分前 5 的电影进行推荐。
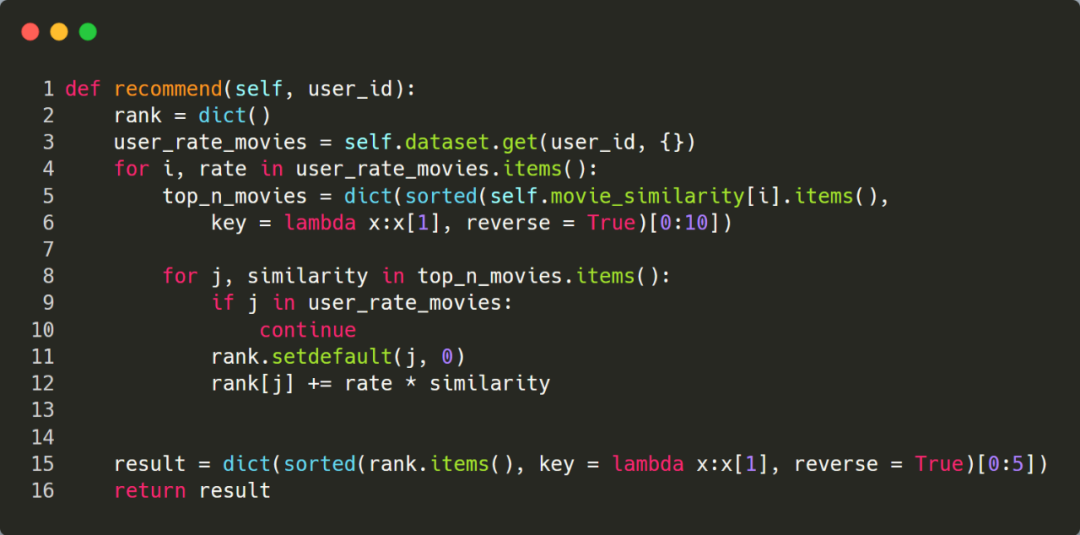
5、 调用推荐系统
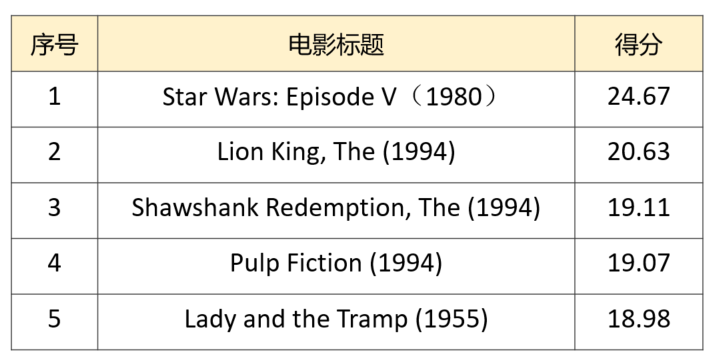
下面选择 UserId=1 这个用户,看下程序的执行结果。由于推荐程序输出的是 movieId 列表,为了更直观的了解推荐结果,这里转换成电影的标题进行输出。
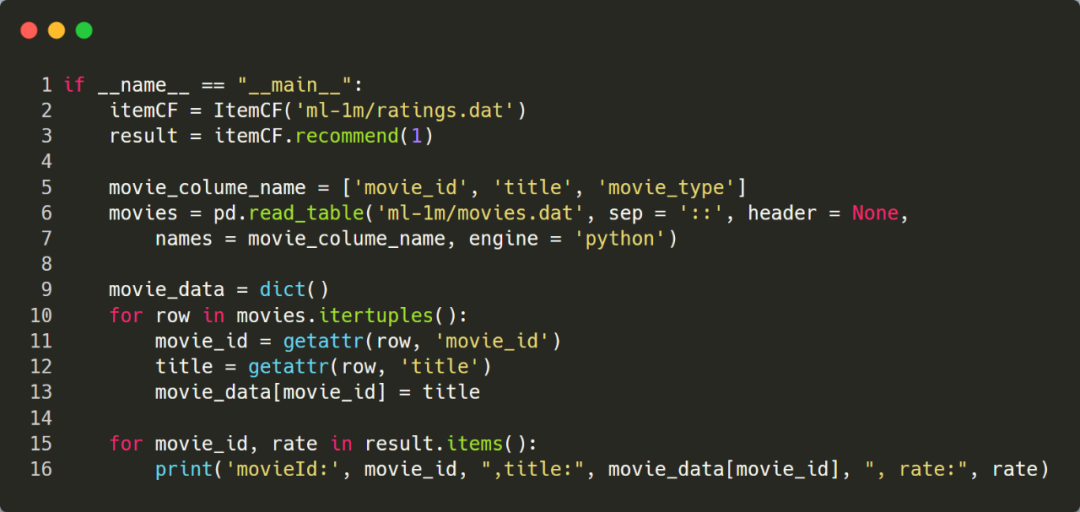
最终推荐的前5个电影为: