
从数据存储层到召回层、再到融合过滤层和排序层,候选集逐层减少,但是精准性要求越来越高,因此也带来了计算复杂度的逐层增加,这个便是推荐系统的最大挑战。
其实对于推荐引擎来说,最核心的部分主要是两块:特征和算法。
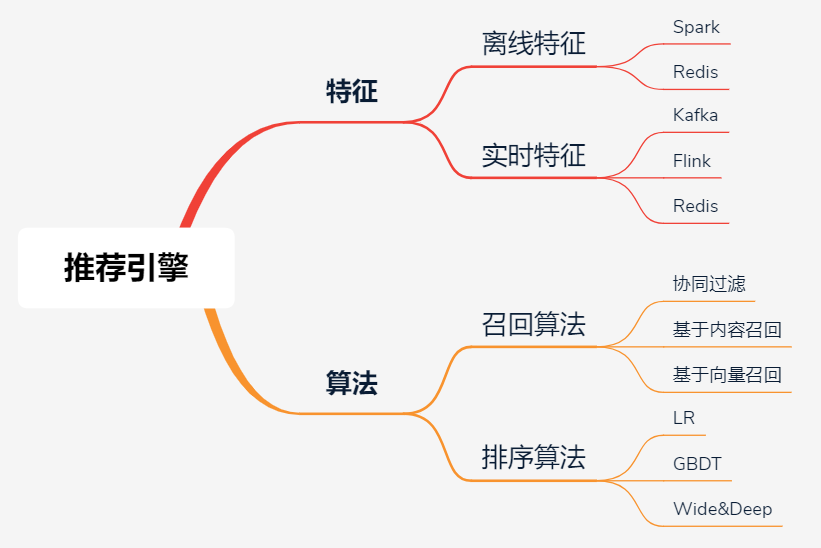
特征计算由于数据量大,通常采用大数据的离线和实时处理技术,像Spark、Flink等,然后将计算结果保存在Redis或者其他存储系统中(比如HBase、MongoDB或者ES),供召回和排序模块使用。
召回算法的作用是:从海量数据中快速获取一批候选数据,要求是快和尽可能的准。这一层通常有丰富的策略和算法,用来确保多样性,为了更好的推荐效果,某些算法也会做成近实时的。
排序算法的作用是:对多路召回的候选集进行精细化排序。它会利用物品、用户以及它们之间的交叉特征,然后通过复杂的机器学习或者深度学习模型进行打分排序,这一层的特点是计算复杂但是结果更精准。
03 图解经典的协同过滤算法了解了推荐系统的整体架构和技术方案后,下面带大家深入一下算法细节。这里选择图解的是推荐系统中的明星算法:协同过滤(Collaborative Filtering,CF)。
对于工程同学来说,可能觉得 AI 算法晦涩难懂,门槛太高,确实很多深度学习算法的确是这样,但是协同过滤却是一个简单同时效果很好的算法,只要你有初中数学的基础就能看懂。
1、协同过滤是什么?
协同过滤算法的核心就是「找相似」,它基于用户的历史行为(浏览、收藏、评论等),去发现用户对物品的喜好,并对喜好进行度量和打分,最终筛选出推荐集合。它又包括两个分支:
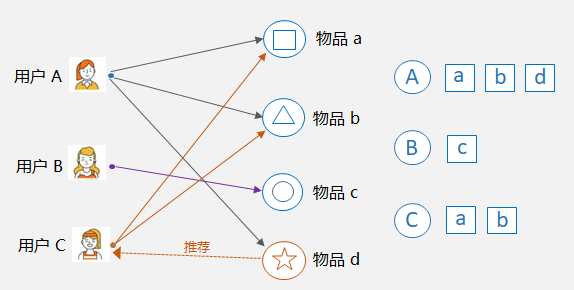
基于用户的协同过滤: User-CF,核心是找相似的人。比如下图中,用户 A 和用户 C 都购买过物品 a 和物品 b,那么可以认为 A 和 C 是相似的,因为他们共同喜欢的物品多。这样,就可以将用户 A 购买过的物品 d 推荐给用户 C 。
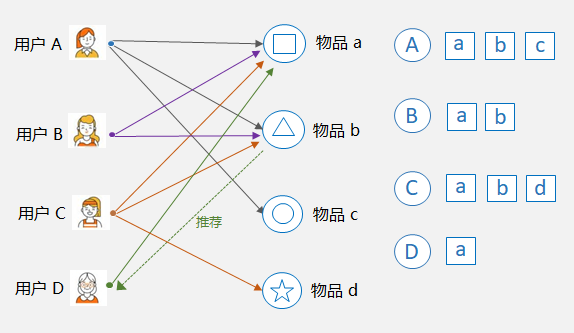
基于物品的协同过滤:Item-CF,核心是找相似的物品。比如下图中,物品 a 和物品 b 同时被用户 A,B,C 购买了,那么物品 a 和 物品 b 被认为是相似的,因为它们的共现次数很高。这样,如果用户 D 购买了物品 a,则可以将和物品 a 最相似的物品 b 推荐给用户 D。
2、如何找相似?
前面讲到,协同过滤的核心就是找相似,User-CF是找用户之间的相似,Item-CF是找物品之间的相似,那到底如何衡量两个用户或者物品之间的相似性呢?
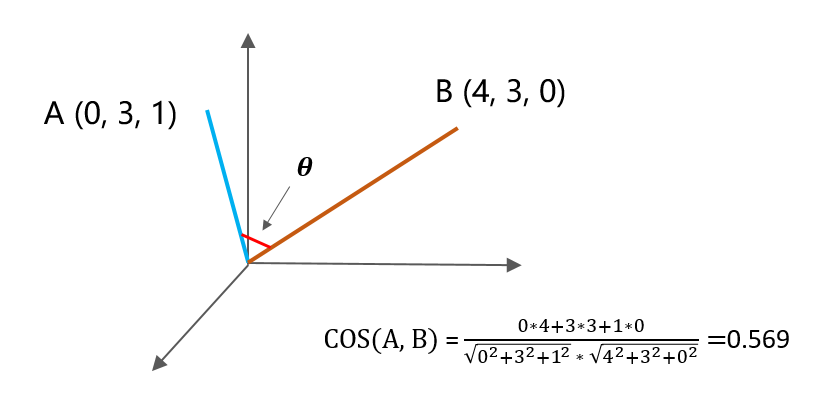
我们都知道,对于坐标中的两个点,如果它们之间的夹角越小,这两个点越相似,这就是初中学过的余弦距离,它的计算公式如下:
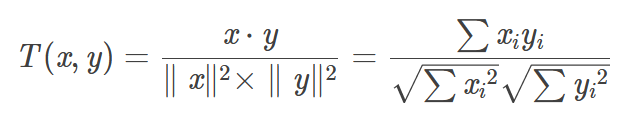
举个例子,A坐标是(0,3,1),B坐标是(4,3,0),那么这两个点的余弦距离是0.569,余弦距离越接近1,表示它们越相似。
除了余弦距离,衡量相似性的方法还有很多种,比如:欧式距离、皮尔逊相关系数、Jaccard 相似系数等等,这里不做展开,只是计算公式上的差异而已。
3、Item-CF的算法流程
清楚了相似性的定义后,下面以Item-CF为例,详细说下这个算法到底是如何选出推荐物品的?
第一步:整理物品的共现矩阵
假设有 A、B、C、D、E 5个用户,其中用户 A 喜欢物品 a、b、c,用户 B 喜欢物品 a、b等等。
