
使用java -verbose命令分析一个字节码文件时,将会分析该字节文件的魔数,版本号,常量池,类信息,类的构造方法,类中的信息,类变量与成员变量等信息。
魔数:所有的.class字节码文件的前4个字节都是魔数,魔数值为固定值:0xCAFEBABE。
魔数之后的4个字节为版本信息,前两个字节表示minor version(次版本号),major versio(主版本号)。这里的00 00 00 34 ,换算成十进制,表示次版本号为0,主版本号为52。所以,该文件的版本信息就是1.8.0。可以通过java -version 命令查看一下Java版本号。
常量池(constant pool): 紧接着主版本号之后的就是常量池入口。一个Java类中定义的很多信息都是由常量池来维护和描述的,可以将常量池看作是class文件的资源仓库,比如说Java类中的定义的方法与变量信息,都是存储在常量池中。常量池中主要存储两类常量:字面量与符号引用。
字面量:如文本字符串,Java中声明final的常量等。
符号引用:如类和接口的全局限定名,字段的名称和描述符,方法的名称和描述符等。
常量池的总体结构:Java类所对应的常量池主要由常量池数量与常量池数组这两部分共同构成。常量池数量紧跟在主版本号后边,占据2个字节;而常量池数组紧跟在常量池数量之后。常量池数组与一般的数组不同的是,常量池数组中不同的元素的类型、结构都是不同的,长度当然也就不同。但是,每一种元素的第一个数据都是一个u1类型。该字节是一个标志位,占据1个字节。JVM在解析常量池时,会根据这个u1类型来获取元素的具体类型。值得注意的是,常量池数组中元素的个数=常量池数-1 (其中0暂时不使用)。目的是为了满足某些常量池索引值的数据在特定情况下需要表达「不引用任何一个常量池」的含义;其根本在于,索引0也是一个常量(保留常量),只不过他不位于常量表中,这个常量就对应null;所以常量池的索引是从1而非0开始的。
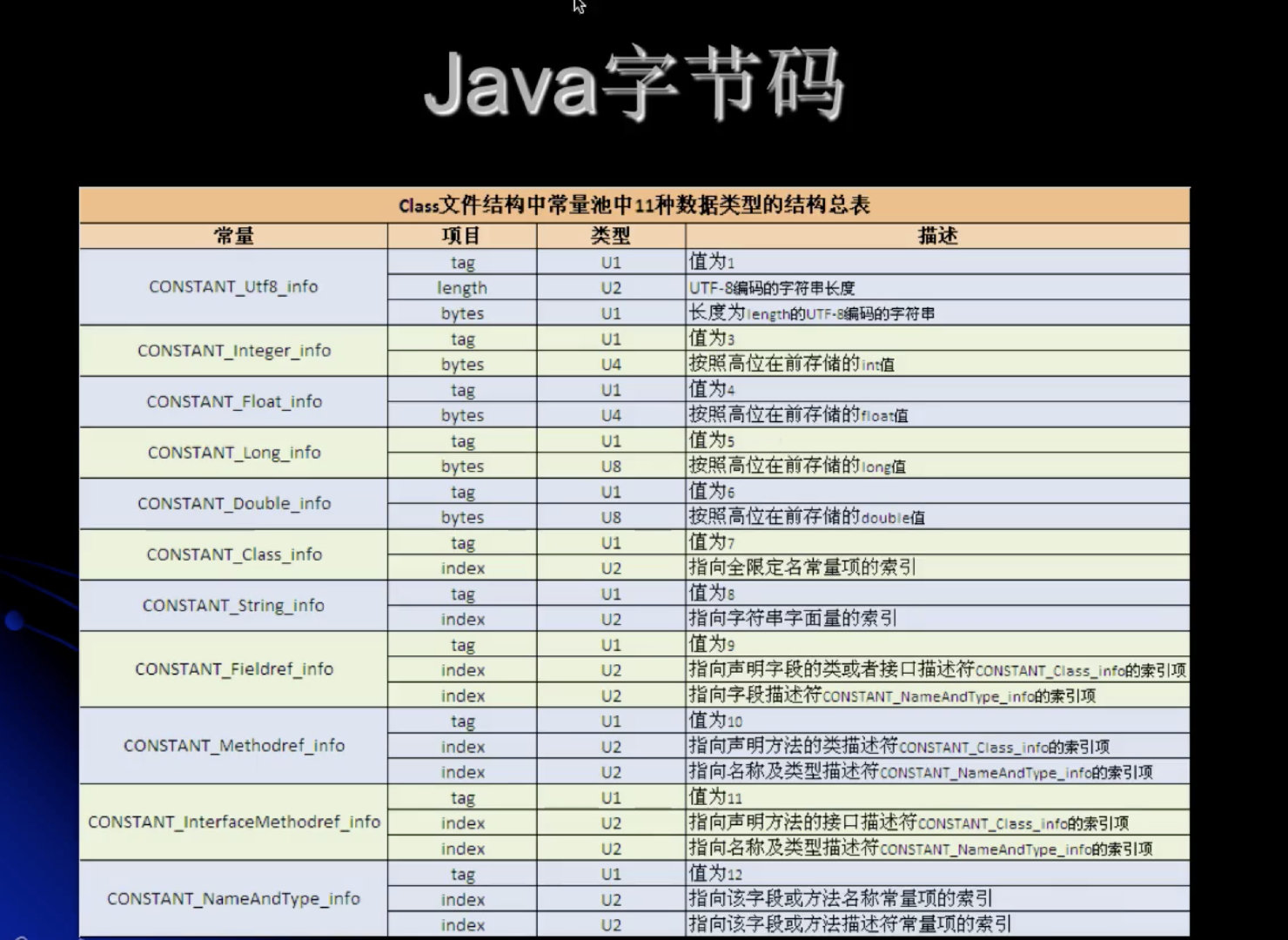
常量池中11中数据类型的结构总表:

在JVM规范中,每个变量/字段都有描述信息,描述信息主要的作用是描述字段的数据类型、方法的参数列表(包括数量,类型与顺序)与返回值。根据描述符规则,基本数据类型和代表无返回值的void类型都用一个大写字符来表示,对象类型则使用字符L加对象的全限定名称来表示。为了压缩字节码文件的体积,对于基本数据类型,JVM都使用一个大写字母来表示,如下所示:B - byte ; C - char ; D - double ; F - float;I - int ; J -long ; S - short ; Z - boolean ; V - void ;L -对象类型,如:Ljava/lang/String.
对于数组类型来说,每一个维度使用一个前置的[来表示,如int[]被记录为I[]。 String[] [] 被记录为[[Ljava/lang/String;