
其中前两个就是双向 LSTM 的目标函数,第三个则是计算视觉语义向量 loss。整个模型的训练可以通过 Back-Propagation through time(BPTT) 来实现。对比标准的双向 LSTM,唯一的区别就是 CNN 模型的梯度是两个来源的平均值(即 LSTM 部分和视觉语义向量学习),这让 CNN 同时也可以学习到有用的语义信息。
4. 实验 4.1 实现细节双向 LSTM:采用 InceptionV3 模型,输出 2048 维的 CNN 特征,然后经过一个全连接层,输出 512 维的特征,然后输入到 LSTM,LSTM 的隐藏单元数量是 512,设置 dropout 概率是 0.7;
视觉-语义向量:联合向量空间的维度是 512 维,所以 $W_I$ 的维度是 $2048\times 512$ ,$W_T$ 的维度是 $2757\times 512$ ,2757 是字典的数量,然后令间隔 m=0.2
联合训练:初始学习率是 0.2,然后衰减因子是 2,并且每 2 个 epoch 更新一次学习率;batch 大小是 10,即每个 batch 包含 10 套搭配序列,大概 65 张图片以及相应的文本描述,然后会微调网络的所有层,当验证集 loss 比较稳定的时候会停止训练。
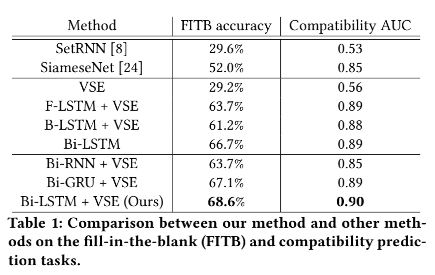
4.2 几种不同实验的结果对于 fill in the blank,实验结果如下:
一些好的例子和不好的例子:

对于搭配匹配性预测,一些预测的例子如下所示:

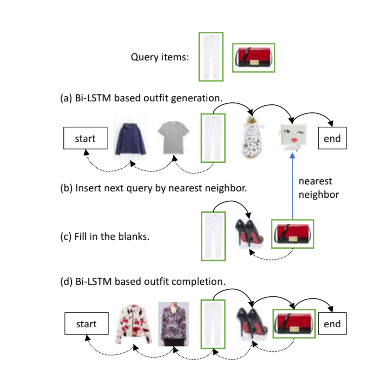
对于搭配生成,第一种实现是输入的只是衣服图片,如下所示:
给定单张图片,那么就如 a 图所示,同时执行两个方向的 LSTM,得到一套完整的搭配;
如果是给定多张图片,如 c 图所示,两张图片,那么会先进行一个类似 fill in the blank 的操作,先预测得到两张图片之间的衣服,然后如 d 所示,再进行预测其他位置的衣服,得到完整的搭配;
如果是输入衣服和文本描述,如下所示:
这种输入的实现,首先会基于给定的衣服图片生成一套初始的搭配,然后对于给定的输入文本描述 $v_q$ ,在初始搭配中的非查询衣服 $f_i$ 会进行更新,更新方式为 $argmin_f d(f, f_i+v_q)$ ,所以更新后的衣服图片将不仅和原始衣服相似,还会在视觉语义向量空间里和输入的查询文本距离很接近。

或者是只输入文本描述,如下所示:
第一种场景,即前两行的图片例子,输入的文本描述是衣服的一种属性或者风格,首先最接近文本描述的衣服图片会被当做是查询图片,然后Bi-LSTM 将通过这张图片来生成一套搭配,接着是会基于给定的图片和文本输入更新搭配;
第二种场景,即后面两行图片例子,给定的文本描述是指向某种衣服类别,所以会根据文本描述检索相应的衣服图片,然后作为查询图片来生成搭配。
