
论文:《Learning Fashion Compatibility with Bidirectional LSTMs》
论文地址:https://arxiv.org/abs/1707.05691
代码地址:https://github.com/xthan/polyvore
联系方式:
Github:https://github.com/ccc013
知乎专栏:机器学习与计算机视觉,AI 论文笔记
微信公众号:AI 算法笔记

时尚搭配推荐的需求越来越大,本文是基于两个方面的时尚推荐:
给定已有的服饰,推荐一件空缺的衣服,从而形成一套搭配,即在已经有上衣、裤子的情况下推荐一双鞋子;
根据多种形式的输入,比如文本或者一件衣服图片,生成一套搭配;
目前存在的难点在于:如何对不同时尚类别的单品通过简单计算视觉相似性来建模和推理其匹配性关系。
目前相关的工作,大部分主要集中在对服饰解析、服饰识别和服饰搜索这三个方向的工作,而对于少量做服饰推荐的工作,也存在这些问题:
没有考虑做一套搭配的推荐;
只能支持上述两个方向的其中一种,即要不只是推荐一套搭配或者对已有的搭配推荐缺失的一件衣服;
目前还没有工作可以支持多种形式的输入,比如可以输入关键词,或者输入图片,或者图片+关键词的输入形式;
对于一套合适的搭配,如下图所示,本文认为应该满足这两个关键属性:
这套搭配中的任意一件服饰应该是视觉上匹配并且是形似风格的;
搭配不能存在重复类型的服饰,比如包含两双鞋子或者两条裤子;

目前相关在做搭配推荐的工作中,主要尝试的方法有:
利用语义属性,即规定了哪些衣服之间是匹配的,但是这种需要对数据进行标记,代价很大而且没办法大量使用;
利用度量学习来学习一对时尚单品之间的距离,但是这只能学习两两之间的匹配性,而非一套搭配;
对于 2 的改进是采用投票策略,但是同样是计算代价非常的大,而且也没办法利用好集合中所有单品的一致性;
为了解决上述的问题,本文提出了通过一个端到端的框架来联合学习视觉语义向量(visual-semantic embedding) 和服饰物品之间的匹配性关系,下图就是本文的整体框架。
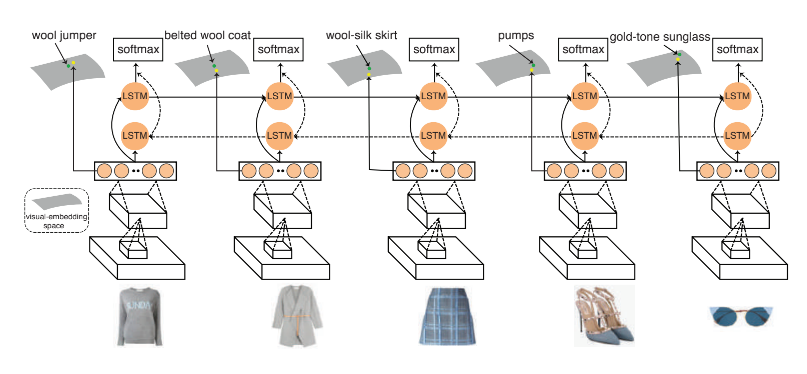
首先是利用 Inception-V3 模型作为特征提取器,将输入图片转成特征向量,然后采用一层共 512 个隐藏单元的双向 LSTM(Bi-LSTM)。之所以采用双向 LSTM,是因为作者认为可以将一套搭配当做是一个特定顺序的序列,搭配中的每件衣服就是一个时间点(time step)。在每个时间点,Bi-LSTM 模型将根据之前的图片来预测下一张图片。
另外,本文的方法还通过将图片特征映射到一个语义表示来学习一个视觉语义向量,它不仅提供了语义属性和类型信息作为训练 LSTM 的输入和正则化方法,还可以实现对用户的多种形式输入来生成一套搭配。
训练好模型后,本文通过三个任务来评估模型,如下图所示,分别是:
Fill in the blank:给定一套缺失某件衣服的搭配,然后给定四个选择,让模型选择最匹配当前搭配的服饰单品;
搭配生成:根据多种输入来生成一套搭配,比如文本输入或者一张服饰图片;
匹配性的预测:给定一套搭配,给出其匹配性得分。

本文实验采用的是一个叫做 Polyvore 的数据集。Polyvore 是一个有名的流行时尚网站,用户可以在网站里创建和上次搭配数据,这些搭配包含了很丰富的多种形式的信息,比如图片和对单品的描述、对该搭配的喜欢数、搭配的一些哈希标签。
Polyvore 数据集总共有 21889 套搭配,本文将其划分成训练集、验证集和测试集,分别是 17316、1497 和 3076 套。
这里参考了论文《 Mining Fashion Outfit Composition Using An End-to-End Deep Learning Approach》,使用一个中图分割算法保证训练集、验证集和测试集不存在重复的衣服,另外对于包含太多单件的搭配,为了方便,仅保留前 8 件衣服,因此,数据集总共包含了 164,379个样本,每个样本是包含了图片以及其文本描述。
对于文本描述的清理,这里删除了出现次数少于 30 次的单词,并构建了一个 2757 个单词的词典。