
越来越多的外部客户正选择将自建的ES集群迁移到腾讯云上来,客户通常是使用 logstash 来迁移数据,由于自建集群中完整保留了数据,因此这时候可以将云上的正在写入的索引副本设置为0, 这样可最快完成集群迁移工作。数据迁移完成后再将副本打开即可。
5. 使用 Bulk 接口批量写入数据,每次 bulk 数据量大小控制在 10M 左右
ES为了提升写入性能,提供了 Bulk 批量写入的API,通常客户端会准备好一批数据往ES中写入,ES收到 Bulk 请求后则根据routing 值进行分发,将该批数据组装成若干分子集,然后异步得发送给各分片所在的节点。
这样能够大大降低写入请求时的网络交互和延迟。通常我们建议一次Bulk的数据量控制在10M以下,一次Bulk的doc数在 10000 上下浮动。
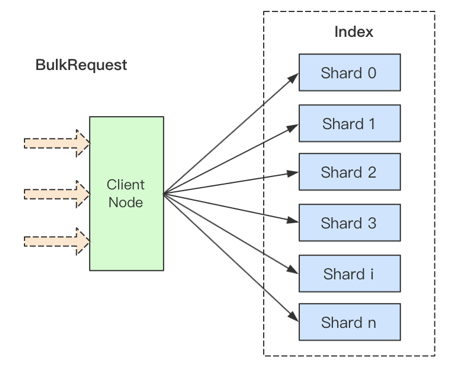
ES Bulk请求示意图
6. 使用自定义 routing 功能,尽量将请求转发到较少的分片
上面我们提到ES提供了Bulk接口支持将数据批量写入到索引,虽然协调节点是异步得将数据发送给所有的分片,但是却需要等待所有的分片响应后才能返回给客户端,因此一次Bulk的延迟则取决于响应最慢的那个分片所在的节点。这就是分布式系统的长尾效应。
因此,我们可以自定义 routing 值,将一次Bulk尽量转发到较少的分片上。
POST _bulk?routing=user_id
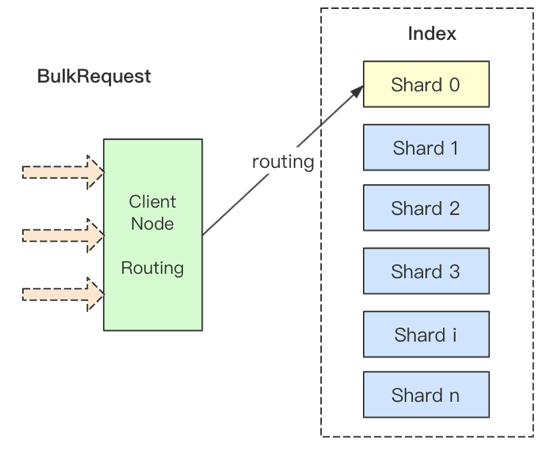
自定义routing
7. 尽量选择 SSD 磁盘类型,并且可选择挂载多块云硬盘
云上目前提供多种类型的磁盘可用选择,其中1T的 SSD 云盘吞吐量为 260M/s,高性能云盘为 150M/s。因此使用SSD磁盘对于写入性能和IO性能都会有一定的提升。
另外腾讯云现在也提供了多盘的能力,相对于单盘节点来说,3块盘的吞吐量大约有2.8倍的提升。
8. 冻结历史索引,释放更多的内存空间
我们知道ES的索引有三种状态,分别是 Open状态、Frozen状态和 Close状态。如下图所示:

ES索引的三种状态
Open状态的索引由于是通过将倒排索引以FST数据结构的方式加载进内存中,因此索引是能够被快速搜索的,且搜索速度也是最快的。
但是需要消耗大量的内存空间,且这部分内存为常驻内存,不会被GC的。1T的索引预计需要消耗2-4GB的JVM堆内存空间。
Frozen状态的索引特点是可被搜索,但是由于它不占用内存,只是存储在磁盘上,因此冻结索引的搜索速度是相对比较慢的。如果我们集群中的数据量比较大,历史数据也不能被删除,则可以考虑使用下面的API将历史索引冻结起来,这样便可释放出较多的内存空间。
POST /index_name/_freeze
对于冻结索引的搜索,可以在API中指定 ignore_throttled=false 参数:
GET /index_name/_search?ignore_throttled=false { "query": { "match": { "name": "wurong" } } }
上面介绍了一些较为常见的写入性能优化的建议和经验,但是更为高效的优化还需要结合具体的业务场景和集群规模。
三、ES集群常规运维经验总结
1. 查看集群健康状态
ES集群的健康状态分为三种,分别是Green、Yellow和Red。
Green(绿色):全部主&副本分片分配成功;
Yellow(黄色):至少有一个副本分片未分配成功;
Red(红色):至少有一个主分片未分配成功。
我们可以通过下面的API来查询集群的健康状态及未分配的分片个数:
GET _cluster/health { "cluster_name": "es-xxxxxxx", "status": "yellow", "timed_out": false, "number_of_nodes": 103, "number_of_data_nodes": 100, "active_primary_shards": 4610, "active_shards": 9212, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 8, "delayed_unassigned_shards": 0, "number_of_pending_tasks": 0, "number_of_in_flight_fetch": 0, "task_max_waiting_in_queue_millis": 0, "active_shards_percent_as_number": 99.91323210412148 }
其中需要重点关注的几个字段有 status、number_of_nodes、unassigned_shards 和 number_of_pending_tasks。
number_of_pending_tasks 这个字段如果很高的话,通常是由于 master 节点触发的元数据更新操作,部分节点响应超时导致的大量的任务堆积。
我们可以通过下面的API来查看具体有那些 task 需要执行: