
尤其是对于写入量在百万 qps 以上的集群,如果总分片数在 10W+,且索引是自动创建的,那么就经常会在每次切换新索引时候,出现写入陡降、集群不可用的情况。
下面这张图是云上一个 100个节点,总分片数在 11W+ 的集群。每天 8点切换新索引时,写入直接掉0,集群不可用时间在数小时不等。
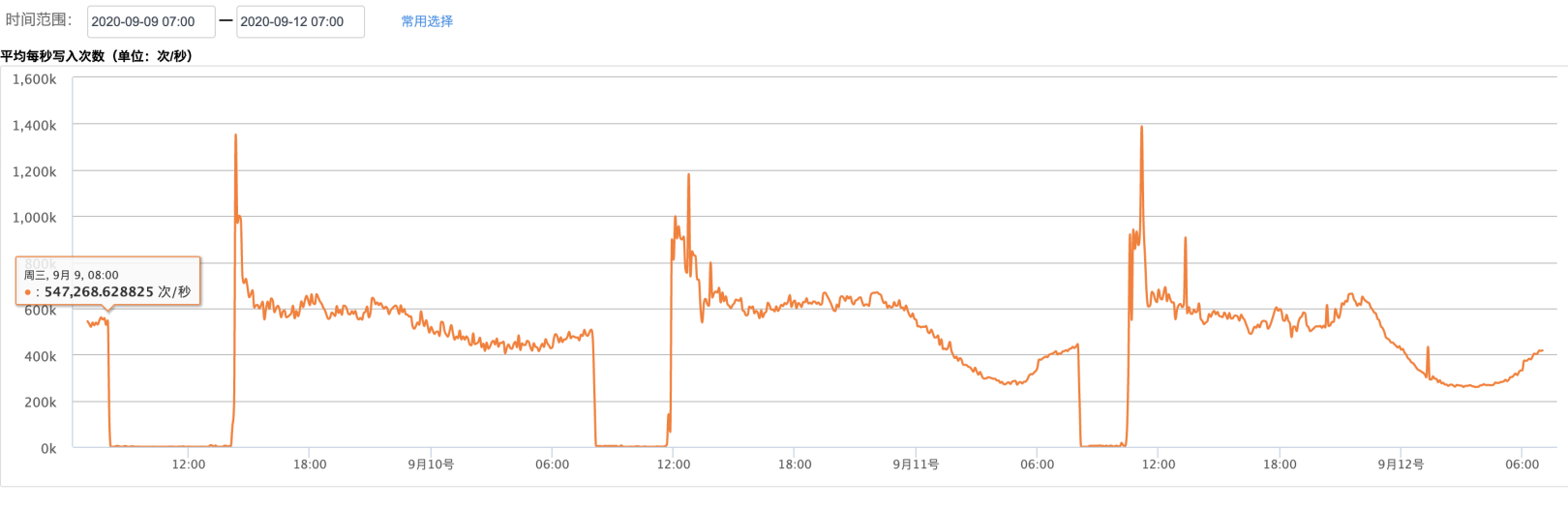
集群每天8点写入性能受到影响
对于这种问题,我们腾讯云ES团队也有一些非常成熟的优化方案。
其中对于每天八点切换新索引时写入陡降的问题,可通过提前创建索引来解决,且建议使用固定的 index mapping,避免大量的 put-mapping 元数据更新操作。因为对于这种节点数量和总分片数量都很大的集群来说,更新元数据是一个非常消耗性能的操作。
对于总分片数超过 10W 的问题,这种一般在日志分析场景中较为常见,如果历史数据不是很重要,则可定期删除历史索引即可。
而对于历史数据较为重要,任何数据都不能删除的场景,则可通过冷热分离架构+索引生命周期管理功能,将7天之前的数据存储到温节点,且在索引数据从热节点迁移到温节点时,通过 Shrink 来将主分片个数降低到一个较小的值,并且可将温节点数据通过快照方式备份到腾讯云COS中,然后将温节点上索引的副本设置为0,这样便可进一步降低集群中的总分片数量。
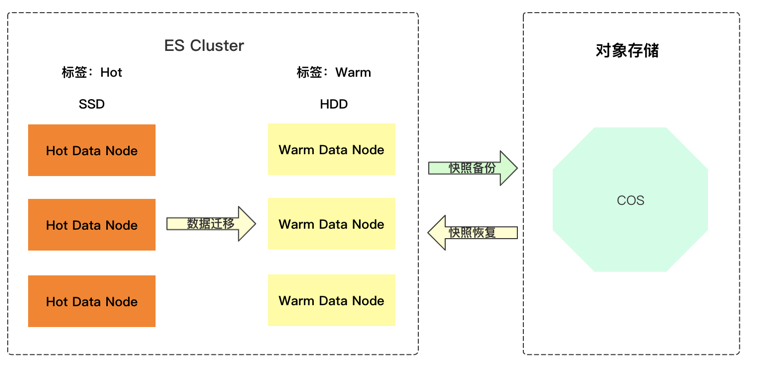
冷热分离+ILM+COS备份集群架构
二、ES写入性能优化
ES集群的写入性能受到很多因素的影响,下面是一些写入性能方面的优化建议:
1. 写入数据不指定doc_id,让 ES 自动生成
索引中每一个 doc 都有一个全局唯一的 doc_id,这个 doc_id 可自定义,也可以让ES自动生成。
如果自定义的话,则ES在写入过程中会多一步判断的过程,即先Get下该 doc_id 是否已经存在。如果存在的话则执行 Update 操作,不存在则创建新的 doc。
因此如果我们对索引 doc_id 没有特别要求,则建议让ES自动生成 doc_id,这样可提升一定的写入性能。
2. 对于规模较大的集群,建议提前创建好索引,且使用固定的 Index mapping
这一条优化建议在上面也提到了,因为创建索引及新加字段都是更新元数据操作,需要 master 节点将新版本的元数据同步到所有节点。
因此在集群规模比较大,写入qps较高的场景下,特别容易出现master更新元数据超时的问题,这可导致 master 节点中有大量的 pending_tasks 任务堆积,从而造成集群不可用,甚至出现集群无主的情况。
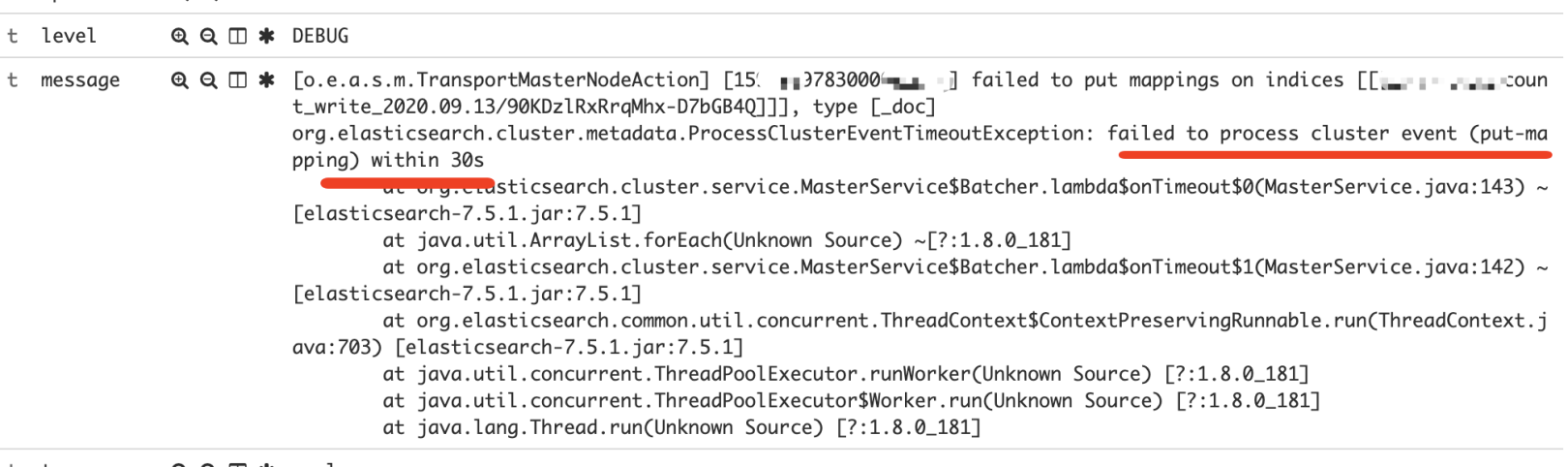
更新集群元数据超时
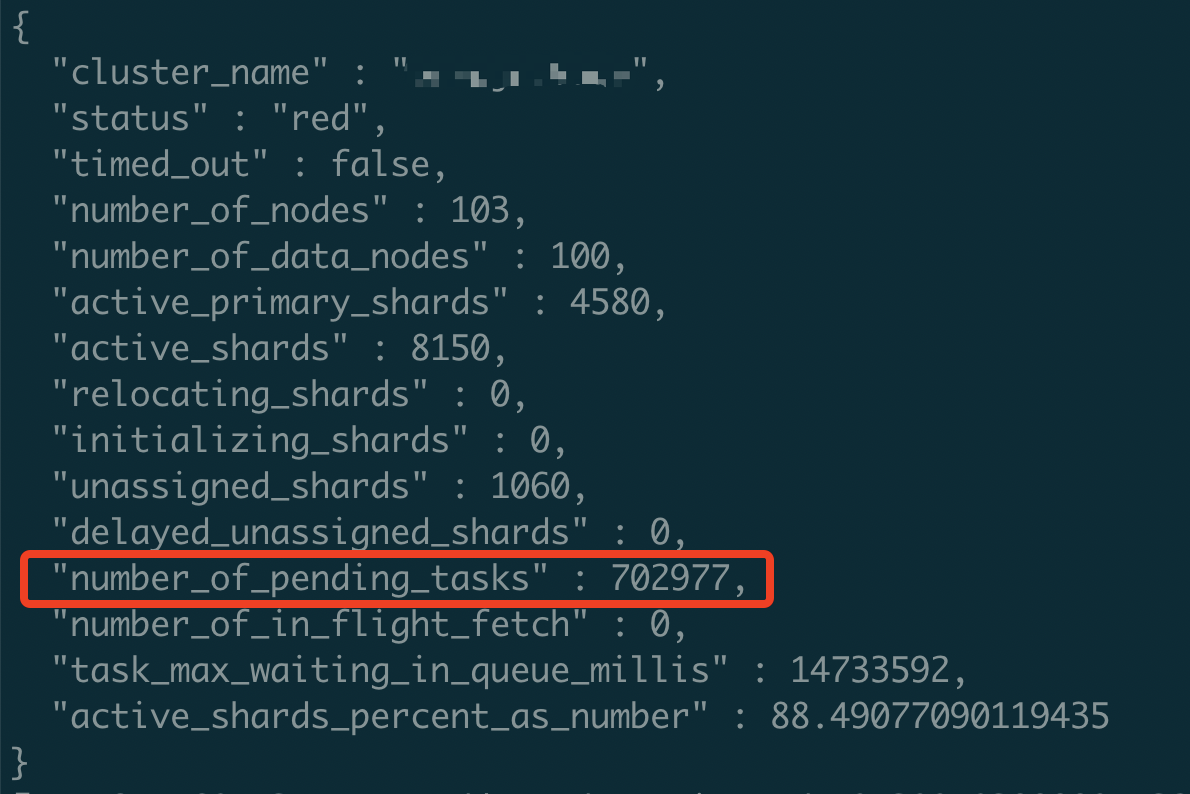
集群大量pending_tasks任务堆积
3. 对于数据实时性要求不高的场景,适当增加 refresh_interval 时间
ES默认的 refresh_interval 是1s,即 doc 写入1s后即可被搜索到。
如果业务对数据实时性要求不高的话,如日志场景,可将索引模版的 refresh_interval 设置成30s,这能够避免过多的小 segment 文件的生成及段合并的操作。
4. 对于追求写入效率的场景,可以将正在写入的索引设置为单副本,写入完成后打开副本