
GET /_cat/pending_tasks insertOrder timeInQueue priority source 1685 855ms HIGH update-mapping [foo][t] 1686 843ms HIGH update-mapping [foo][t] 1693 753ms HIGH refresh-mapping [foo][[t]] 1688 816ms HIGH update-mapping [foo][t]
其中 priority 字段则表示该 task 的优先级,翻看 ES 的源码可以看到一共有六种优先级:
IMMEDIATE((byte) 0), URGENT((byte) 1), HIGH((byte) 2), NORMAL((byte) 3), LOW((byte) 4), LANGUID((byte) 5);
2. 查看分片未分配原因
当集群Red时候,我们可以通过下面的API来查看分片未分配的原因:
GET _cluster/allocation/explain
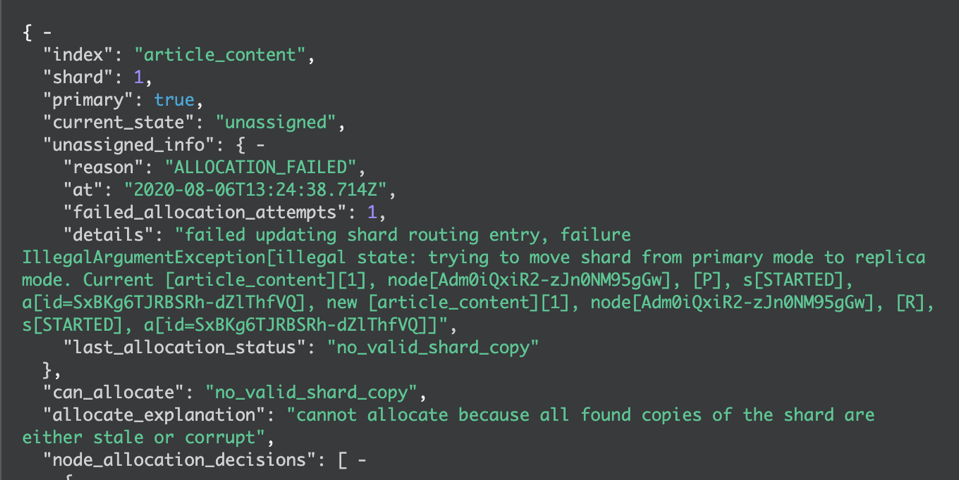
查看分片未分配的原因
其中 index和shard 列出了具体哪个索引的哪个分片未分配成功。reason 字段则列出了哪种原因导致的分片未分配。这里也将所有可能的原因列出来:
INDEX_CREATED:由于创建索引的API导致未分配。 CLUSTER_RECOVERED :由于完全集群恢复导致未分配。 INDEX_REOPENED :由于打开open或关闭close一个索引导致未分配。 DANGLING_INDEX_IMPORTED :由于导入dangling索引的结果导致未分配。 NEW_INDEX_RESTORED :由于恢复到新索引导致未分配。 EXISTING_INDEX_RESTORED :由于恢复到已关闭的索引导致未分配。 REPLICA_ADDED:由于显式添加副本分片导致未分配。 ALLOCATION_FAILED :由于分片分配失败导致未分配。 NODE_LEFT :由于承载该分片的节点离开集群导致未分配。 REINITIALIZED :由于当分片从开始移动到初始化时导致未分配(例如,使用影子shadow副本分片)。 REROUTE_CANCELLED :作为显式取消重新路由命令的结果取消分配。 REALLOCATED_REPLICA :确定更好的副本位置被标定使用,导致现有的副本分配被取消,出现未分配。
detail 字段则列出了更为详细的未分配的原因。下面我会总结下在日常运维工作中常见的几种原因。
如果未分配的分片比较多的话,我们也可以通过下面的API来列出所有未分配的索引和主分片:
GET /_cat/indices?v&health=red3. 常见分片未分配原因总结
(1)磁盘满了 the node is above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=95%], using more disk space than the maximum allowed [95.0%], actual free: [4.055101177689788%]
当我们执行 _cluster/allocation/explain 命令后看到上面的一行语句的话,则可以判断是该索引主分片所在的节点磁盘满了。
解决方法:扩容磁盘提升磁盘容量或者删除历史数据释放磁盘空间。
通常如果磁盘满了,ES为了保证集群的稳定性,会将该节点上所有的索引设置为只读。ES 7.x版本之后当磁盘空间提升后可自动解除,但是7.x版本之前则需要手动执行下面的API来解除只读模式:
PUT index_name/_settings { "index": { "blocks": { "read_only_allow_delete": null } } } (2)分片的文档数超过了21亿条限制
failure IllegalArgumentException[number of documents in the index cannot exceed 2147483519
该限制是分片维度而不是索引维度的。因此出现这种异常,通常是由于我们的索引分片设置的不是很合理。
解决方法:切换写入到新索引,并修改索引模版,合理设置主分片数。
(3)主分片所在节点掉线cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster
这种情况通常是由于某个节点故障或者由于负载较高导致的掉线。
解决方法:找到节点掉线原因并重新启动节点加入集群,等待分片恢复。
(4)索引所需属性和节点属性不匹配
node does not match index setting [index.routing.allocation.require] filters [temperature:\"warm\",_id:\"comdNq4ZSd2Y6ycB9Oubsg\"]
解决方法:重新设置索引所需的属性,和节点保持一致。因为如果重新设置节点属性,则需要重启节点,代价较高。
例如通过下面的API来修改索引所需要分配节点的温度属性: