
某天突然收到线上应用的gc时间过长的告警,刚开始只有一台机器偶尔报一下,后续其他机器也纷纷告警,具体告警的阈值是应用10分钟内ygc的总时长达到了6.6s。
初步排除过程按照gc问题常规排查流程,还是先保留现场,jmap -dump:format=b,file=temp.dump pid。
查看下gc日志,发现出问题的时候的单次ygc耗时几乎有200ms以上了。正常来说单次ygc在100ms以下,基本可以认为应用是比较健康的。所以这时候已经可以确定告警的原因就是ygc比较慢。
jvisualvm打开刚刚dump的文件看下能不能发现什么东西,看了下,也看不出什么特殊的,因为本身dump的时候会触发一次full gc,dump下来的堆里面的内容只有1G左右(jvm参数堆内存配置的是4G)如下图,也没发现什么特殊的东西
然后看下ygc近期耗时的走势图,下图纵坐标每10分钟gc总耗时(单位:s),横坐标日期,可以看到在2月22号应用重启后gc总耗时降下来了,然后随着时间推移,gc变得越来越慢,并且这个变慢的过程非常缓慢,正常情况下重启一次到应用触发gc告警,需要1至2周才能出现。

网上搜了下有没有相关案例,相关资料也非常少,然后看到 了 笨神的一篇文章,这篇文章简单总结起来就是使用jdk中的1.8的nashorn js引擎使用不当触发了底层JVM的一个缺陷。然后回到我这边来,发现和我这边的场景也挺类似的,应用也大量使用了nashorn 引擎来执行javascript脚步,所以我初步猜测也是nashorn引擎使用不当导致。
为了验证我以上的想法,找运维加了-XX:+PrintReferenceGC参数,经过一段时间观察,应用重启后,观察了一段时间,发现gc日志中JNI Weak Reference处理时长变得越来越长。而且占用整个ygc时长的大部分。
再回到刚刚dump的那张图里面,能看到实例数排在前面的也有nashorn引擎相关的内容,如下图,现在几乎可以断定问题出在的执行某个javascript脚步。
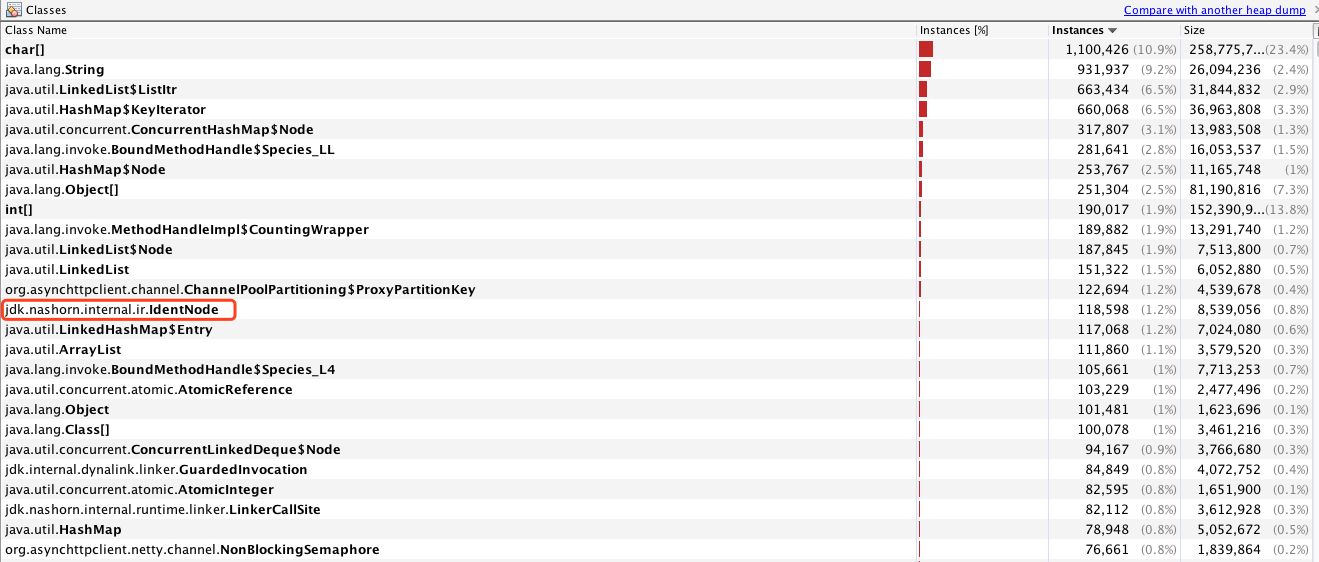
现在确认了出问题的大致方向。但是该应用执行的javascript脚步也有10多个,所以还没发直接定位到是哪个脚步导致的。所以接下来就是定位具体的脚步了。初步想法是直接根据上图的中的jdk.nashorn.internal.ir.IdenNode通过引用链找到可疑的js脚步对应的String,尝试了很多次发现都失败了。主要本身对jdk.nashorn包下类不是很熟悉,再加上引用链都比较长,所以找了很久都没有找到这个类和脚步的应用关系。
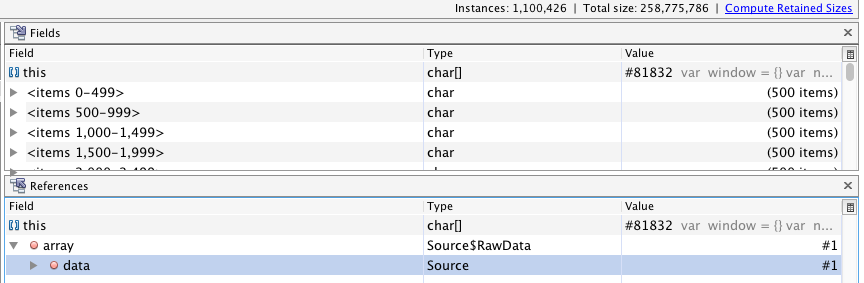
于是换了一种思路,内存中,脚步肯定会以String对象存在,String底层采用char[]来存储字符。所以直接找char[]实例中内容为js脚步的,但是这里又遇到一个问题,看上面的dump文件图,会发现char[]实例数当前内存有100w+,这里就抓住了部分js脚步长度比较长的一个特点。直接根据size正序排列,长度前10的字符串,就直接就找到了一个脚步,顺着引用链会轻易发现,js脚步的内容都是保存在Source$RawData对象中的,如下图
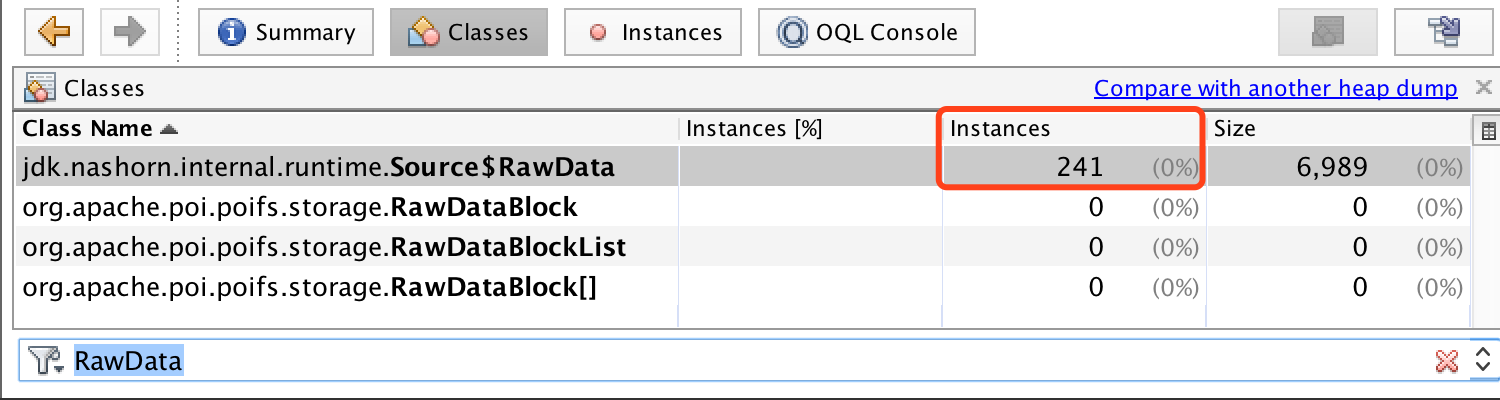
然后回到VisualVM的Classes栏目,直接搜索Source$RawData,可以看到有241个实例,如下图
如何解决:修改了这个脚步的调用方式。不用每次执行eval方法,换成Bindings的方式调用。
修改后,经过一周的观察。ygc时间以及区域稳定了,如下图

小插曲:其实这个问题在18年10月份左右都出现了,早期也考虑彻底解决过,也探索了不少方法。比如下:
最开始的时候怀疑是G1 收集器的问题,直接把G1收集器改回CMS收集器,其中调整该参数的过程中也发生了一个小问题,具体如下。
从G1改到CMS改回来的参数设置堆空间大小相关的参数变成了-Xms4000m -Xmx4000m -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:MaxDirectMemorySize=512m -XX:+UseCMSInitiatingOccupancyOnly -XX:SurvivorRatio=8 -XX:+ExplicitGCInvokesConcurrent -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:-OmitStackTraceInFastThrow -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/var/www/logs/gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=10m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=http://www.likecs.com/var/www/logs -Djava.io.tmpdir=http://www.likecs.com/var/www/tmp -Dio.netty.availableProcessors=4 -XX:ParallelGCThreads=4 -Dpinpoint.applicationName=crawler-worker.product-bank这样,其中-Xms4000m是初始化堆大小,-Xmx4000m是最大堆大小,然后重启应用,重启后,就收到ygc频繁的告警,然后用jstat -gc pid 3000看了下,发现了奇怪的地方(如下图)
