
所谓高斯朴素贝叶斯,就是当特征属性为连续值并且服从高斯分布时,可以使用高斯分布的概率公式直接计算条件概率的值。
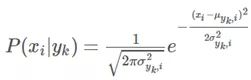 此时,我们只需要计算各个类别下的特征划分的均值和标准差.
多项式朴素贝叶斯(一般使用在特征属性离散的情况下)
所谓多项式朴素贝叶斯,就是特征属性服从多项式分布,进而对于每一个类别y,参数
,其中n为特征属性数目,那么P(xi|y)的概率为θyi。
伯努利朴素贝叶斯(一般使用在缺失值较多的情况下)
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,伯努利模型中每个特征的取值只能是1和0(以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0).
sklearn中有3种不同类型的朴素贝叶斯:
高斯分布型:用于classification问题,假定属性/特征服从正态分布的。
多项式型:用于离散值模型里。比如文本分类问题里面我们提到过,我们不光看词语是否在文本中出现,也得看出现次数。如果总词数为n,出现词数为m的话,有点像掷骰子n次出现m次这个词的场景。
伯努利型:最后得到的特征只有0(没出现)和1(出现过)。
例1 我们使用iris数据集进行分类
from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import cross_val_score from sklearn import datasets iris = datasets.load_iris() gnb = GaussianNB() scores=cross_val_score(gnb, iris.data, iris.target, cv=10) print("Accuracy:%.3f"%scores.mean())输出: Accuracy:0.953
例2 Kaggle比赛之“旧金山犯罪分类预测”
题目背景:『水深火热』的大米国,在旧金山这个地方,一度犯罪率还挺高的,然后很多人都经历过大到暴力案件,小到东西被偷,车被划的事情。当地警方也是努力地去总结和想办法降低犯罪率,一个挑战是在给出犯罪的地点和时间的之后,要第一时间确定这可能是一个什么样的犯罪类型,以确定警力等等。后来干脆一不做二不休,直接把12年内旧金山城内的犯罪报告都丢带Kaggle上,说『大家折腾折腾吧,看看谁能帮忙第一时间预测一下犯罪类型』。犯罪报告里面包括日期,描述,星期几,所属警区,处理结果,地址,GPS定位等信息。当然,分类问题有很多分类器可以选择,我们既然刚讲过朴素贝叶斯,刚好就拿来练练手好了。
(1) 首先我们来看一下数据
import pandas as pd import numpy as np from sklearn import preprocessing from sklearn.metrics import log_loss from sklearn.cross_validation import train_test_split train = pd.read_csv('/Users/liuming/projects/Python/ML数据/Kaggle旧金山犯罪类型分类/train.csv', parse_dates = ['Dates']) test = pd.read_csv('/Users/liuming/projects/Python/ML数据/Kaggle旧金山犯罪类型分类/test.csv', parse_dates = ['Dates']) train我们依次解释一下每一列的含义:
Date: 日期
Category: 犯罪类型,比如 Larceny/盗窃罪 等.
Descript: 对于犯罪更详细的描述
DayOfWeek: 星期几
PdDistrict: 所属警区
Resolution: 处理结果,比如说『逮捕』『逃了』
Address: 发生街区位置
X and Y: GPS坐标
train.csv中的数据时间跨度为12年,包含了将近90w的记录。另外,这部分数据,大家从上图上也可以看出来,大部分都是『类别』型,比如犯罪类型,比如星期几。
(2)特征预处理
sklearn.preprocessing模块中的 LabelEncoder函数可以对类别做编号,我们用它对犯罪类型做编号;pandas中的get_dummies( )可以将变量进行二值化01向量,我们用它对”街区“、”星期几“、”时间点“进行因子化。