
字典在Redis中的应用非常广泛,数据库与哈希对象的底层实现就是字典。
系列文章图解Redis之数据结构篇——简单动态字符串SDS
图解Redis之数据结构篇——链表
图解Redis之数据结构篇——字典
一、复习散列表 1.1 散列表散列表(哈希表),其思想主要是基于数组支持按照下标随机访问数据时间复杂度为O(1)的特性。可是说是数组的一种扩展。假设,我们为了方便记录某高校数学专业的所有学生的信息。要求可以按照学号(学号格式为:入学时间+年级+专业+专业内自增序号,如2011 1101 0001)能够快速找到某个学生的信息。这个时候我们可以取学号的自增序号部分,即后四位作为数组的索引下标,把学生相应的信息存储到对应的空间内即可。
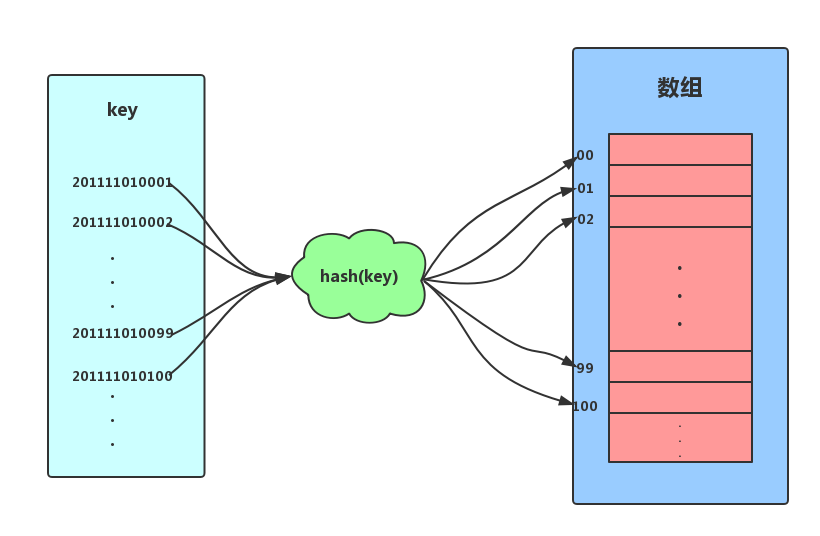
如上图所示,我们把学号作为key,通过截取学号后四位的函数后计算后得到索引下标,将数据存储到数组中。当我们按照键值(学号)查找时,只需要再次计算出索引下标,然后取出相应数据即可。以上便是散列思想。
1.2 散列函数上面的例子中,截取学号后四位的函数即是一个简单的散列函数。
//散列函数 伪代码 int Hash(string key) { // 获取后四位字符 string hashValue =int.parse(key.Substring(key.Length-4, 4)); // 将后两位字符转换为整数 return hashValue; }在这里散列函数的作用就是讲key值映射成数组的索引下标。关于散列函数的设计方法有很多,如:直接寻址法、数字分析法、随机数法等等。但即使是再优秀的设计方法也不能避免散列冲突。在散列表中散列函数不应设计太复杂。
1.3 散列冲突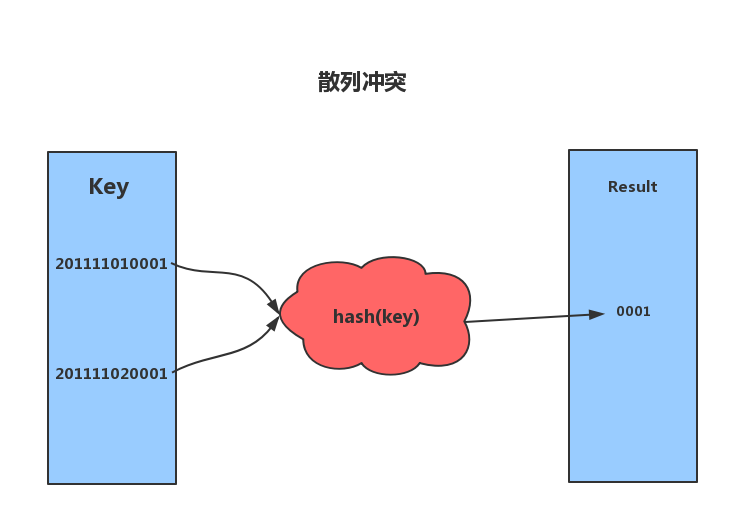
散列函数具有确定性和不确定性。
确定性:哈希的散列值不同,那么哈希的原始输入也就不同。即:key1=key2,那么hash(key1)=hash(key2)。
不确定性:同一个散列值很有可能对应多个不同的原始输入。即:key1≠key2,hash(key1)=hash(key2)。
散列冲突,即key1≠key2,hash(key1)=hash(key2)的情况。散列冲突是不可避免的,如果我们key的长度为100,而数组的索引数量只有50,那么再优秀的算法也无法避免散列冲突。关于散列冲突也有很多解决办法,这里简单复习两种:开放寻址法和链表法。
1.3.1 开放寻址法开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一一个空闲位置,将其插入。比如,我们可以使用线性探测法。当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,如果遍历到尾部都没有找到空闲的位置,那么我们就再从表头开始找,直到找到为止。
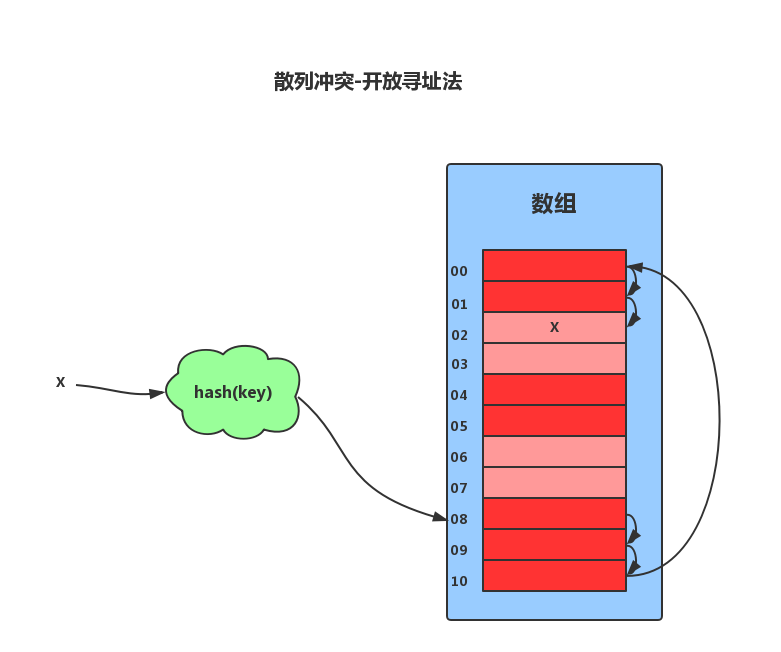
散列表中查找元素的时候,我们通过散列函数求出要查找元素的键值对应的散列值,然后比较数组中下标为散列值的元素和要查找的元素。如果相等,则说明就是我们要找的元素;否则就顺序往后依次查找。如果遍历到数组中的空闲位置还没有找到,就说明要查找的元素并没有在散列表中。
对于删除操作稍微有些特别,不能单纯地把要删除的元素设置为空。因为在查找的时候,一旦我们通过线性探测方法,找到一个空闲位置,我们就可以认定散列表中不存在这个数据。但是,如果这个空闲位置是我们后来删除的,就会导致原来的查找算法失效。这里我们可以将删除的元素,特殊标记为 deleted。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。
线性探测法存在很大问题。当散列表中插入的数据越来越多时,其散列冲突的可能性就越大,极端情况下甚至要探测整个散列表,因此最坏时间复杂度为O(N)。在开放寻址法中,除了线性探测法,我们还可以二次探测和双重散列等方式。
1.3.2 链表法链表法是一种比较常用的散列冲突解决办法,Redis使用的就是链表法来解决散列冲突。链表法的原理是:如果遇到冲突,他就会在原地址新建一个空间,然后以链表结点的形式插入到该空间。当插入的时候,我们只需要通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可。
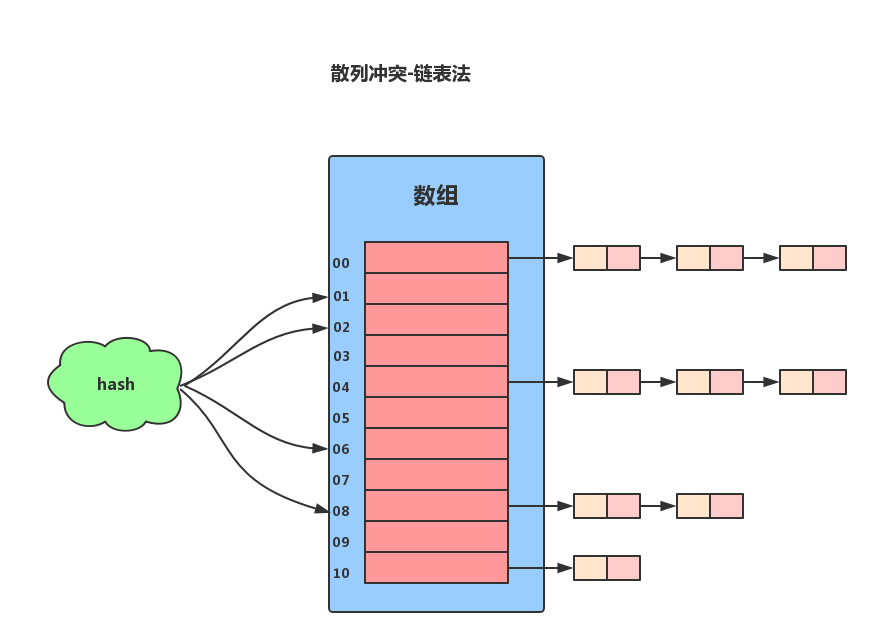
我们可以使用装载因子来衡量散列表的“健康状况”。
散列表的负载因子 = 填入表中的元素个数/散列表的长度散列表负载因子越大,代表空闲位置越少,冲突也就越多,散列表的性能会下降。