
当有两个或以上的键被分配到散列表数组同一个索引上时,就发生了键冲突。Redis使用链表法解决散列冲突。每个散列表节点都有一个next指针,多个散列表节点next可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以使用这个单向链表连接起来。
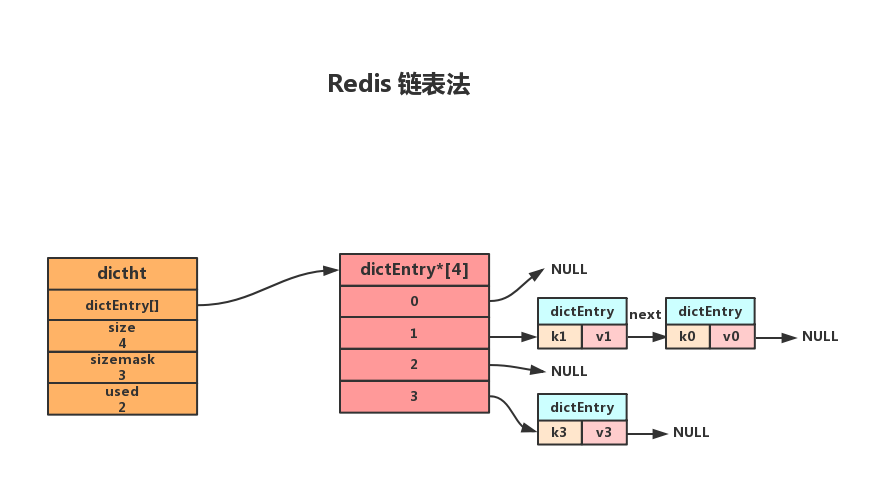
如图所示,当键k0和k1的经过散列函数得到索引值都为1时,就会使用next指针将两个节点连接起来。而由于节点没有指向链尾的指针,因此新的节点总是插入到链表的头部,排在已有节点的前面。
2.2.2 Redis rehash随着操作的进行,散列表中保存的键值对会也会不断地增加或减少,为了保证负载因子维持在一个合理的范围,当散列表内的键值对过多或过少时,内需要定期进行rehash,以提升性能或节省内存。Redis的rehash的步骤如下:

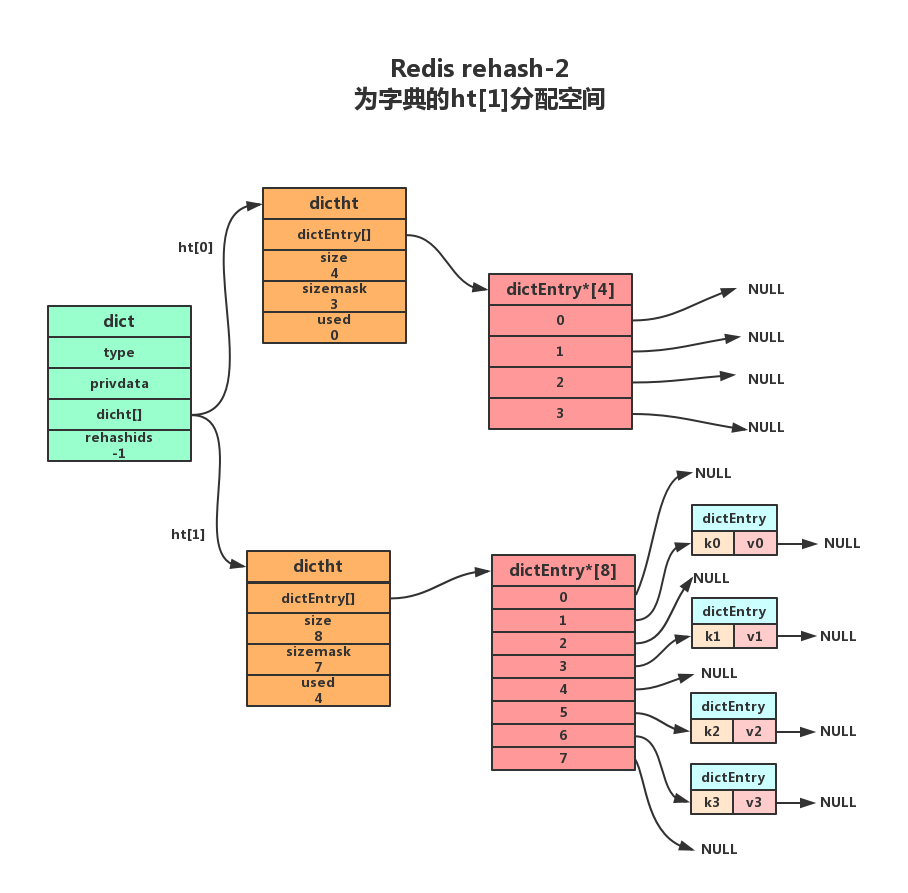
为字典的ht[1]散列表分配空间,这个空间的大小取决于要执行的操作以及ht[0]当前包含的键值对数量(即:ht[0].used的属性值)
扩展操作:ht[1]的大小为 第一个大于等于ht[0].used*2的2的n次方幂。如:ht[0].used=3则ht[1]的大小为8,ht[0].used=4则ht[1]的大小为8。
收缩操作: ht[1]的大小为 第一个大于等于ht[0].used的2的n次方幂。

将保存在ht[0]中的键值对重新计算键的散列值和索引值,然后放到ht[1]指定的位置上。
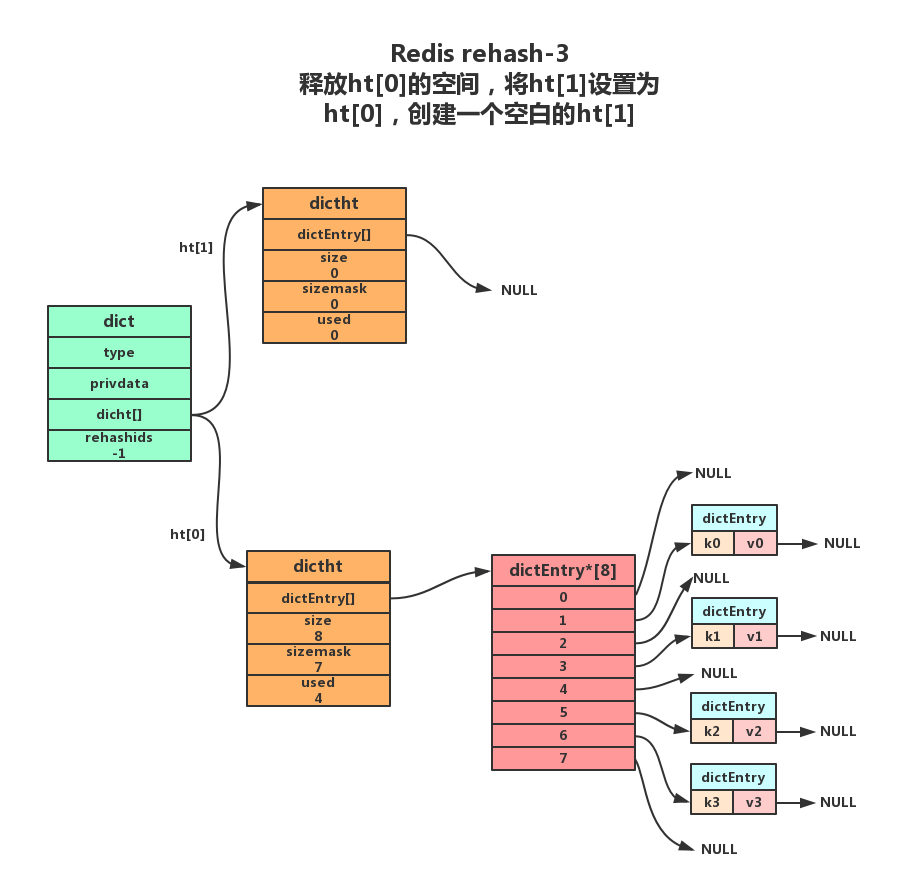
将ht[0]包含的所有键值对都迁移到了ht[1]之后,释放ht[0],将ht[1]设置为ht[0],并创建一个新的ht[1]哈希表为下一次rehash做准备。
rehash操作需要满足以下条件:
服务器目前没有执行BGSAVE(rdb持久化)命令或者BGREWRITEAOF(AOF文件重写)命令,并且散列表的负载因子大于等于1。
服务器目前正在执行BGSAVE命令或者BGREWRITEAOF命令,并且负载因子大于等于5。
当负载因子小于0.1时,程序自动开始执行收缩操作。
Redis这么做的目的是基于操作系统创建子进程后写时复制技术,避免不必要的写入操作。(有关BGSAVE、BGREWRITEAOF以及写时复制会在后续持久化一文详细介绍)。
2.2.3 渐进式 rehash对于rehash我们思考一个问题如果散列表当前大小为 1GB,要想扩容为原来的两倍大小,那就需要对 1GB 的数据重新计算哈希值,并且从原来的散列表搬移到新的散列表。这种情况听着就很耗时,而生产环境中甚至会更大。为了解决一次性扩容耗时过多的情况,可以将扩容操作穿插在插入操作的过程中,分批完成。当负载因子触达阈值之后,只申请新空间,但并不将老的数据搬移到新散列表中。当有新数据要插入时,将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表。每次插入一个数据到散列表,都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了。这样没有了集中的一次一次性数据搬移,插入操作就都变得很快了。
Redis为了解决这个问题采用渐进式rehash方式。以下是Redis渐进式rehash的详细步骤:
为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 ,表示 rehash 工作正式开始。
在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1] , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。
随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
说明:
1.因为在进行渐进式 rehash 的过程中,字典会同时使用 ht[0] 和 ht[1] 两个哈希表,所以在渐进式 rehash 进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行。