
今天,又是干货满满的一天。这是全网最硬核 JVM 系列的开篇,首先从 TLAB 开始。由于文章很长,每个人阅读习惯不同,所以特此拆成单篇版和多篇版
全网最硬核 JVM TLAB 分析(单篇版不包含额外加菜)
全网最硬核 JVM TLAB 分析 1. 内存分配思想引入
全网最硬核 JVM TLAB 分析 2. TLAB生命周期与带来的问题思考
全网最硬核 JVM TLAB 分析 3. JVM EMA期望算法与TLAB相关JVM启动参数
全网最硬核 JVM TLAB 分析 4. TLAB 基本流程全分析
全网最硬核 JVM TLAB 分析 5. TLAB 源代码全解析
全网最硬核 JVM TLAB 分析 6. TLAB 相关热门Q&A汇总
全网最硬核 JVM TLAB 分析(额外加菜) 7. TLAB 相关 JVM 日志解析
全网最硬核 JVM TLAB 分析(额外加菜) 8. 通过 JFR 监控 TLAB
1. 观前提醒本期内容比较硬核,非常全面,涉及到了设计思想到实现原理以及源码,并且还给出了相应的日志以及监控方式,如果有不清楚或者有疑问的地方,欢迎留言。
其中涉及到的设计思想主要为个人理解,实现原理以及源码解析也是个人整理,如果有不准确的地方,非常欢迎指正!提前感谢~~
2. 分配内存实现思路我们经常会 new 一个对象,这个对象是需要占用空间的,第一次 new 一个对象占用的空间如 图00 所示,
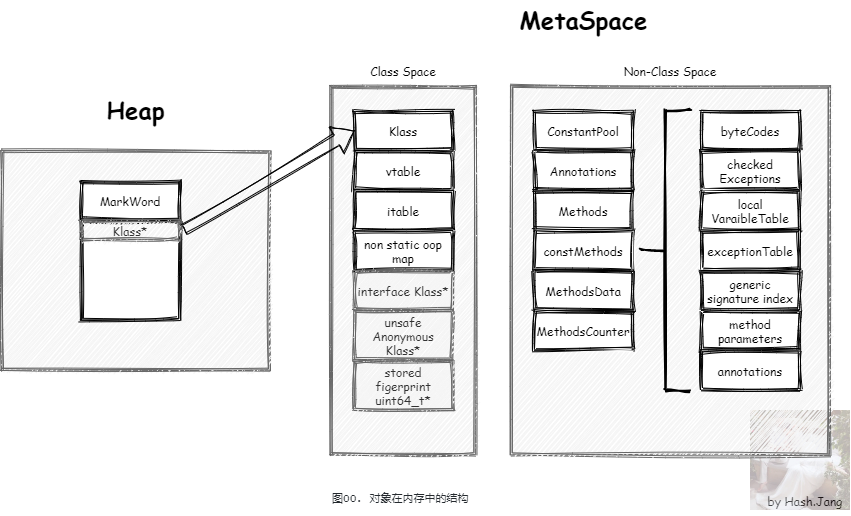
我们这里先只关心堆内部的存储,元空间中的存储,我们会在另一个系列详细讨论。堆内部的存储包括对象头,对象体以及内存对齐填充,那么这块空间是如何分配的呢?
首先,对象所需的内存,在对象的类被解析加载进入元空间之后,就可以在分配内存创建前计算出来。假设现在我们自己来设计堆内存分配,一种最简单的实现方式就是线性分配,也被称为撞针分配(bump-the-pointer)。
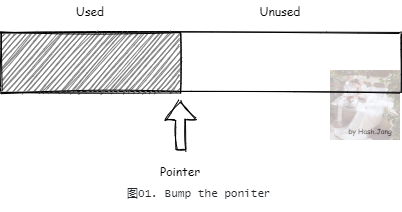
每次需要分配内存时,先计算出需要的内存大小,然后 CAS 更新如 图01 中所示的内存分配指针,标记分配的内存。但是内存一般不是这么整齐的,可能有些内存在分配有些内存就被释放回收了。所以一般不会只靠撞针分配。一种思路是在撞针分配的基础上,加上一个 FreeList。
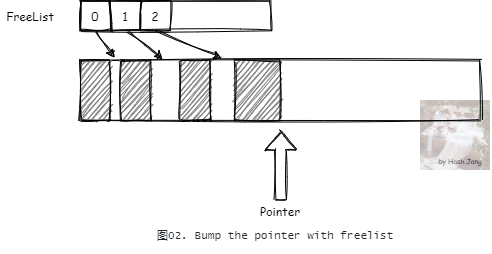
简单的实现是将释放的对象内存加入 FreeList,下次分配对象的时候,优先从 FreeList 中寻找合适的内存大小进行分配,之后再在主内存中撞针分配。
这样虽然一定程度上解决了问题,但是目前大多数应用是多线程的,所以内存分配是多线程的,都从主内存中分配,CAS 更新重试过于频繁导致效率低下。目前的应用,一般根据不同业务区分了不同的线程池,在这种情况下,一般每个线程分配内存的特性是比较稳定的。这里的比较稳定指的是,每次分配对象的大小,每轮 GC 分配区间内的分配对象的个数以及总大小。所以,我们可以考虑每个线程分配内存后,就将这块内存保留起来,用于下次分配,这样就不用每次从主内存中分配了。如果能估算每轮 GC 内每个线程使用的内存大小,则可以提前分配好内存给线程,这样就更能提高分配效率。这种内存分配的实现方式,在 JVM 中就是 TLAB (Thread Local Allocate Buffer)。
3. JVM 对象堆内存分配流程简述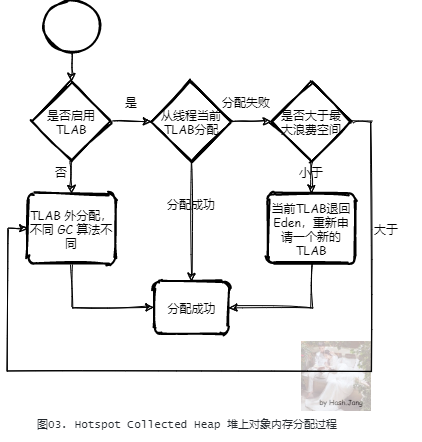
我们这里不考虑栈上分配,这些会在 JIT 的章节详细分析,我们这里考虑的是无法栈上分配需要共享的对象。
对于 HotSpot JVM 实现,所有的 GC 算法的实现都是一种对于堆内存的管理,也就是都实现了一种堆的抽象,它们都实现了接口 CollectedHeap。当分配一个对象堆内存空间时,在 CollectedHeap 上首先都会检查是否启用了 TLAB,如果启用了,则会尝试 TLAB 分配;如果当前线程的 TLAB 大小足够,那么从线程当前的 TLAB 中分配;如果不够,但是当前 TLAB 剩余空间小于最大浪费空间限制(这是一个动态的值,我们后面会详细分析),则从堆上(一般是 Eden 区) 重新申请一个新的 TLAB 进行分配。否则,直接在 TLAB 外进行分配。TLAB 外的分配策略,不同的 GC 算法不同。例如G1:
如果是 Humongous 对象(对象在超过 Region 一半大小的时候),直接在 Humongous 区域分配(老年代的连续区域)。
根据 Mutator 状况在当前分配下标的 Region 内分配
4. TLAB 的生命周期