
至此,我们就会发现,一个典型的三层结构出现了:接入、逻辑、存储。然而,这种三层结果,并不就能包医百病。例如,当我们需要让用户在线互动(网游就是典型) ,那么分割在不同逻辑服务器上的在线状态数据,是无法知道对方的,这样我们就需要专门做一个类似互动服务器的专门系统,让用户登录的时候,也同时记录一份数据到它那里,表明某个用户登录在某个服务器上,而所有的互动操作,要先经过这个互动服务器,才能正确的把消息转发到目标用户的服务器上。
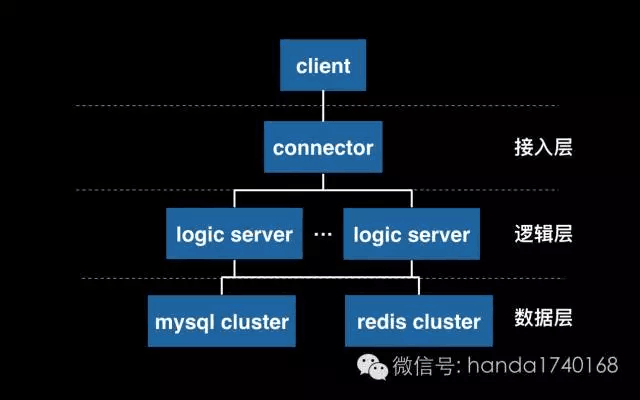
又例如,当我们在使用网上论坛(BBS)系统的时候,我们发的文章,不可能只写入一个数据库里,因为太多人的阅读请求会拖死这个数据库。我们常常会按论坛板块来写入不同的数据库,又或者是同时写入多个数据库。这样把文章数据分别存放到不同的服务器上,才能应对大量的操作请求。然而,用户在读取文章的时候,就需要有一个专门的程序,去查找具体文章在哪一个服务器上,这时候我们就要架设一个专门的代理层,把所有的文章请求先转交给它,由它按照我们预设的存储计划,去找对应的数据库获取数据。
根据上面的例子来看,分布式系统虽然具有三层典型的结构,但是实际上往往不止有三层,而是根据业务需求,会设计成多个层次的。为了把请求转交给正确的进程处理,我们而设计很多专门用于转发请求的进程和服务器。这些进程我们常常以Proxy或者Router来命名,一个多层结构常常会具备各种各样的Proxy进程。这些代理进程,很多时候都是通过TCP来连接前后两端。然而,TCP虽然简单,但是却会有故障后不容易恢复的问题。而且TCP的网络编程,也是有点复杂的。——所以,人们设计出更好进程间通讯机制:消息队列。
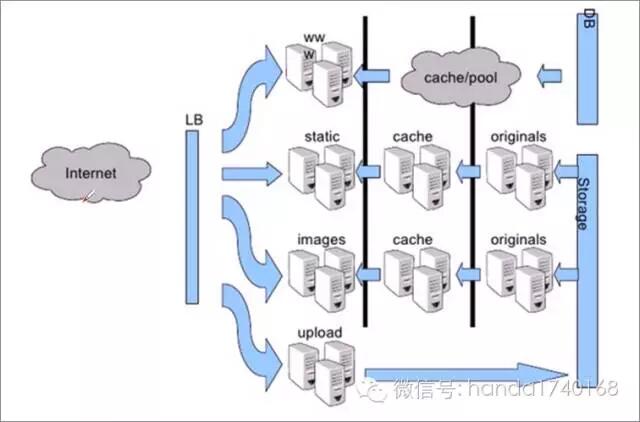
尽管通过各种Proxy或者Router进程能组建出强大的分布式系统,但是其管理的复杂性也是非常高的。所以人们在分层模式的基础上,想出了更多的方法,来让这种分层模式的程序变得更简单高效的方法。
并发模型(多线程、异步)当我们在编写服务器端程序是,我们会明确的知道,大部分的程序,都是会处理同时到达的多个请求的。因此我们不能好像HelloWorld那么简单的,从一个简单的输入计算出输出来。因为我们会同时获得很多个输入,需要返回很多个输出。在这些处理的过程中,往往我们还会碰到需要“等待”或“阻塞”的情况,比如我们的程序要等待数据库处理结果,等待向另外一个进程请求结果等等……如果我们把请求一个挨着一个的处理,那么这些空闲的等待时间将白白浪费,造成用户的响应延时增加,以及整体系统的吞吐量极度下降。
所以在如何同时处理多个请求的问题上,业界有2个典型的方案。一种是多线程,一种是异步。在早期的系统中,多线程或多进程是最常用的技术。这种技术的代码编写起来比较简单,因为每个线程中的代码都肯定是按先后顺序执行的。但是由于同时运行着多个线程,所以你无法保障多个线程之间的代码的先后顺序。这对于需要处理同一个数据的逻辑来说,是一个非常严重的问题,最简单的例子就是显示某个新闻的阅读量。两个++操作同时运行,有可能结果只加了1,而不是2。所以多线程下,我们常常要加很多数据的锁,而这些锁又反过来可能导致线程的死锁。
因此异步回调模型在随后比多线程更加流行,除了多线程的死锁问题外,异步还能解决多线程下,线程反复切换导致不必要的开销的问题:每个线程都需要一个独立的栈空间,在多线程并行运行的时候,这些栈的数据可能需要来回的拷贝,这额外消耗了CPU。同时由于每个线程都需要占用栈空间,所以在大量线程存在的时候,内存的消耗也是巨大的。而异步回调模型则能很好的解决这些问题,不过异步回调更像是“手工版”的并行处理,需要开发者自己去实现如何“并行”的问题。
异步回调基于非阻塞的I/O操作(网络和文件),这样我们就不用在调用读写函数的时候“卡”在那一句函数调用,而是立刻返回“有无数据”的结果。而Linux的epoll技术,则利用底层内核的机制,让我们可以快速的“查找”到有数据可以读写的连接\文件。由于每个操作都是非阻塞的,所以我们的程序可以只用一个进程,就处理大量并发的请求。因为只有一个进程,所以所有的数据处理,其顺序都是固定的,不可能出现多线程中,两个函数的语句交错执行的情况,因此也不需要各种“锁”。从这个角度看,异步非阻塞的技术,是大大简化了开发的过程。由于只有一个线程,也不需要有线程切换之类的开销,所以异步非阻塞成为很多对吞吐量、并发有较高要求的系统首选。