
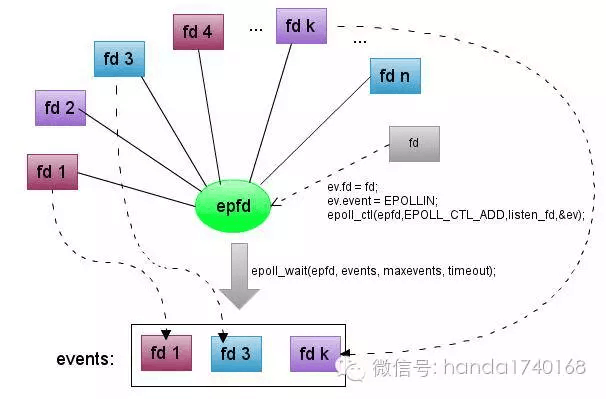
在互联网服务中,大部分的用户交互,都是需要立刻返回结果的,所以对于延迟有一定的要求。而类似网络游戏之类服务,延迟更是要求缩短到几十毫秒以内。所以为了降低延迟,缓冲是互联网服务中最常见的技术之一。
早期的WEB系统中,如果每个HTTP请求的处理,都去数据库(MySQL)读写一次,那么数据库很快就会因为连接数占满而停止响应。因为一般的数据库,支持的连接数都只有几百,而WEB的应用的并发请求,轻松能到几千。这也是很多设计不良的网站人一多就卡死的最直接原因。为了尽量减少对数据库的连接和访问,人们设计了很多缓冲系统——把从数据库中查询的结果存放到更快的设施上,如果没有相关联的修改,就直接从这里读。
最典型的WEB应用缓冲系统是Memcache。由于PHP本身的线程结构,是不带状态的。早期PHP本身甚至连操作“堆”内存的方法都没有,所以那些持久的状态,就一定要存放到另外一个进程里。而Memcache就是一个简单可靠的存放临时状态的开源软件。很多PHP应用现在的处理逻辑,都是先从数据库读取数据,然后写入Memcache;当下次请求来的时候,先尝试从Memcache里面读取数据,这样就有可能大大减少对数据库的访问。
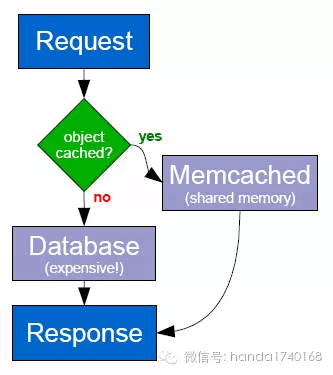
然而Memcache本身是一个独立的服务器进程,这个进程自身并不带特别的集群功能。也就是说这些Memcache进程,并不能直接组建成一个统一的集群。如果一个Memcache不够用,我们就要手工用代码去分配,哪些数据应该去哪个Memcache进程。——这对于真正的大型分布式网站来说,管理一个这样的缓冲系统,是一个很繁琐的工作。
因此人们开始考虑设计一些更高效的缓冲系统:从性能上来说,Memcache的每笔请求,都要经过网络传输,才能去拉取内存中的数据。这无疑是有一点浪费的,因为请求者本身的内存,也是可以存放数据的。——这就是促成了很多利用请求方内存的缓冲算法和技术,其中最简单的就是使用LRU算法,把数据放在一个哈希表结构的堆内存中。
而Memcache的不具备集群功能,也是一个用户的痛点。于是很多人开始设计,如何让数据缓存分不到不同的机器上。最简单的思路是所谓读写分离,也就是缓存每次写,都写到多个缓冲进程上记录,而读则可以随机读任何一个进程。在业务数据有明显的读写不平衡差距上,效果是非常好的。
然而,并不是所有的业务都能简单的用读写分离来解决问题,比如一些在线互动的互联网业务,比如社区、游戏。这些业务的数据读写频率并没很大的差异,而且也要求很高的延迟。因此人们又再想办法,把本地内存和远端进程的内存缓存结合起来使用,让数据具备两级缓存。同时,一个数据不在同时的复制存在所有的缓存进程上,而是按一定规律分布在多个进程上。——这种分布规律使用的算法,最流行的就是所谓“一致性哈希”。这种算法的好处是,当某一个进程失效挂掉,不需要把整个集群中所有的缓存数据,都重新修改一次位置。你可以想象一下,如果我们的数据缓存分布,是用简单的以数据的ID对进程数取模,那么一旦进程数变化,每个数据存放的进程位置都可能变化,这对于服务器的故障容忍是不利的。