
导读:企业数字化使得运维智能化转型成为必然,宜信积极推动 AIOps 在科技金融企业的落地实践。本次主题是探索 AIOps 落地的一种形式:通过行为采集、仿真模拟、主动感知等手段,从用户侧真实系统使用体验出发,结合全维监控数据,更加有效的实现智能异常检测和根因分析。
一、运维的发展 1.1 运维的价值早期的运维工作比较简单,一般是先由系统集成工程师及研发工程师研发完项目后交付出来,再由负责运维工作的人员从后台做一些操作,保证系统正常运行。
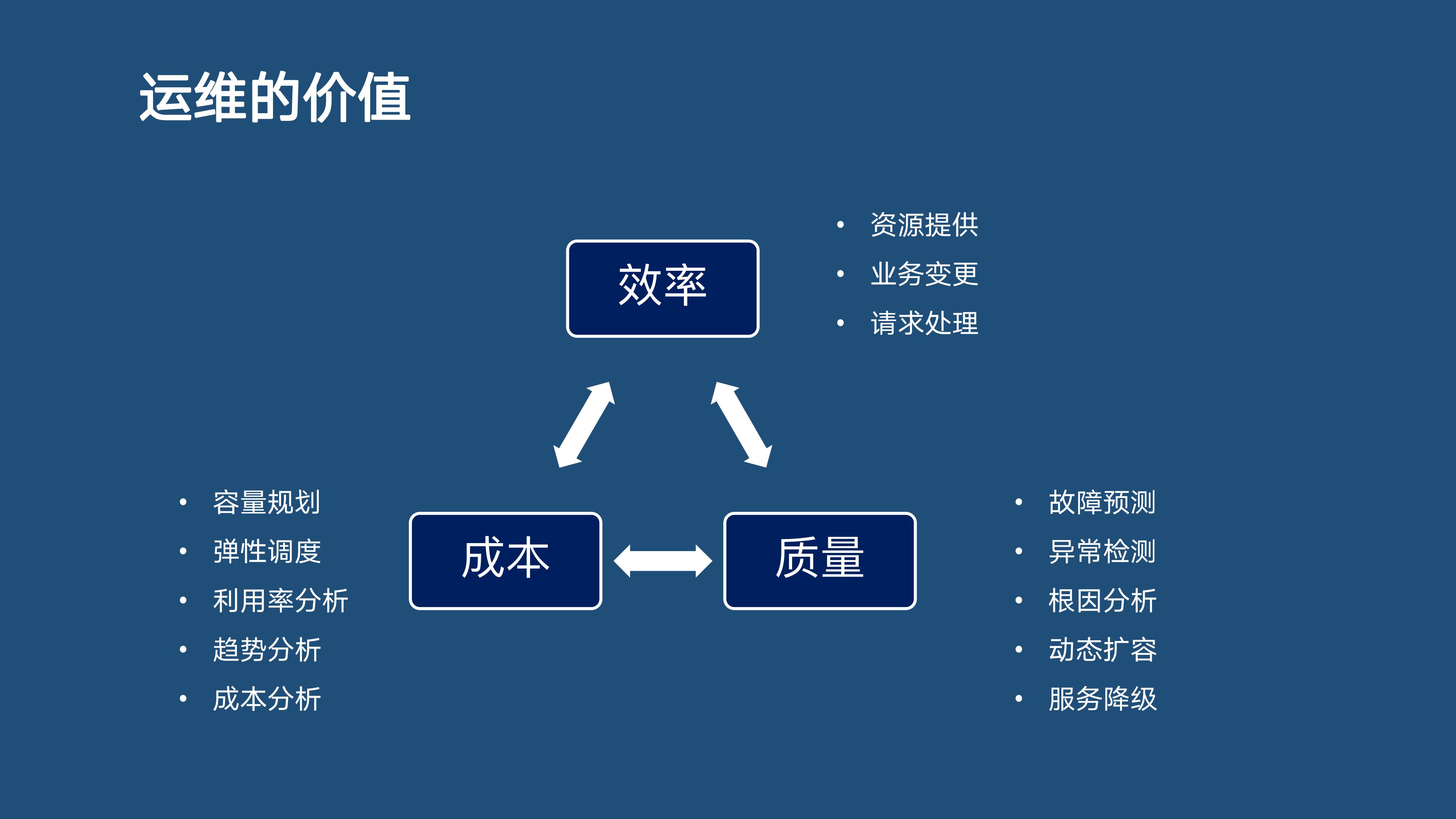
图1
随着软件研发行业和技术的发展,运维的工作也变得越来越丰富。现阶段运维的工作与价值主要集中在三个方面:
1)效率大量业务上线,运维人员需要保障快速高效地为系统提供资源、应对业务变更、响应操作请求。
2)质量运维的目标是保障质量及系统的稳定性。也就是说,要保障业务和系统7*24小时在线上稳定运行,为用户提供流畅舒适的体验。为实现这个目标,运维的相关工作包括:
故障预测:没出现问题之前预测到故障发生的可能。
异常检测:出现问题时很快检测并定位到异常点。
根因分析:分析问题的诱因,找出真正导致问题的根本原因。
动态扩容:问题处理的过程中可能受到复杂因素的影响,需要对系统进行动态扩容。
服务降级:不影响核心业务的边缘业务可能需要做服务降级处理。
3)成本随着公司规模的不断壮大,投入产出比也越来越被重视。运维的另外一个价值在于降低成本。主要体现为:
容量规划:规划每年在IT运维层面投入多少人员和资源。
弹性调度:如何调度和分配资源,实现资源的充分利用。
利用率分析:利用率分析包括动态和静态两个方面。
趋势分析:比如今年花了多少钱在IT运维层面,明年要花多少钱在这个方面,这是一个趋势分析。
成本分析:成本分析包括今年有多少业务、每个业务用了多少钱、多少IT技术设施、多少人员。
1.2 运维的困境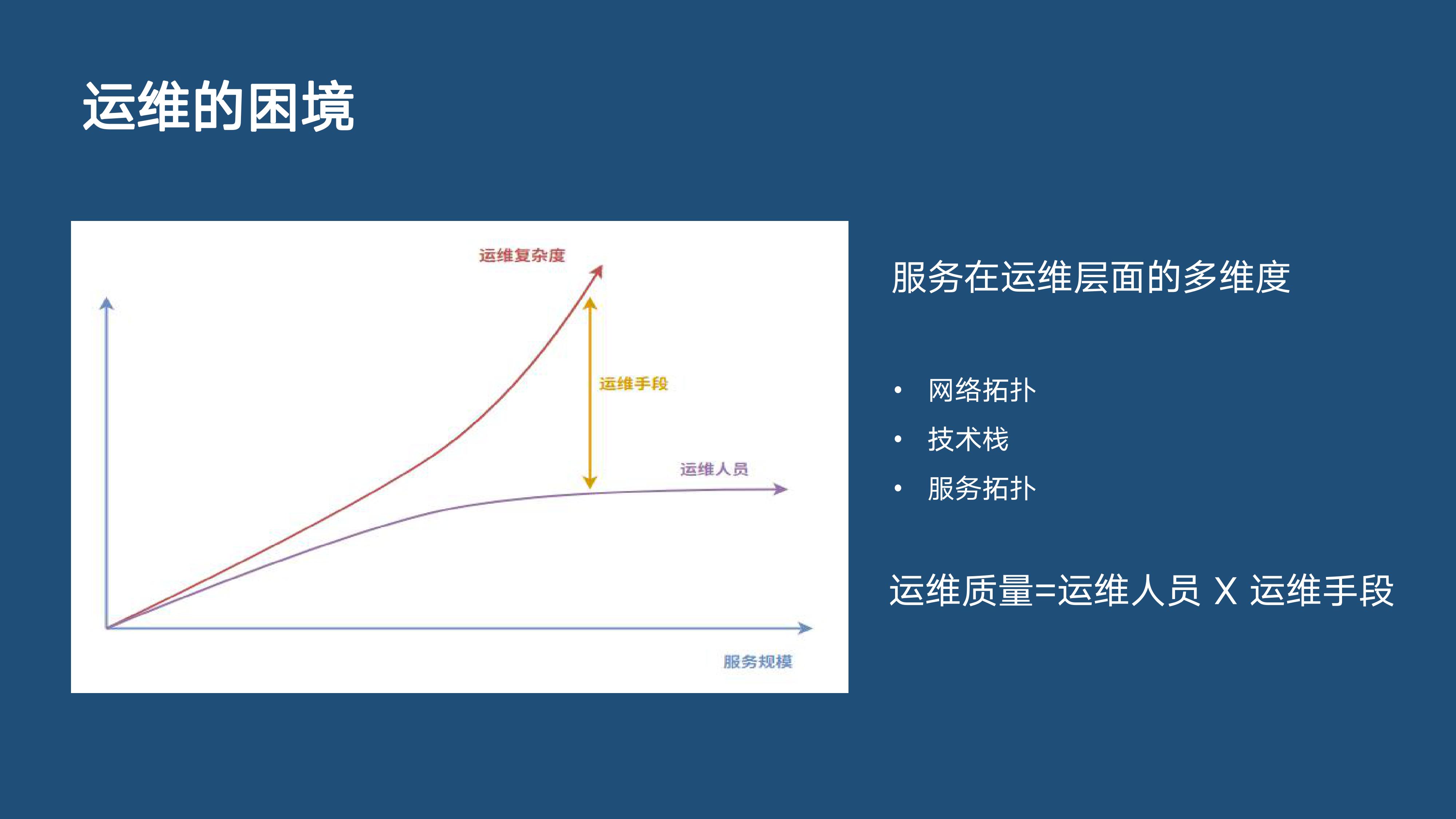
图2
如图所示,横坐标代表服务规模。公司业务不断增长,服务规模也相应增长,此处我们简单理解为这是一个线性的变化,不考虑业务的暴增。
然而,业务规模增长反映到运维的复杂度增长上最少体现在三个层面:
服务规模的增长直接导致服务器量及网络量的增长,随之而来的是网络拓扑的增长。
业务增长,服务的技术栈也是增长的。以前可能前边跑一个服务,后边跑一个数据库就可以了,现在随着服务规模的不断增长,引入不同服务形式,可能就有了队列、缓存等,相应的,技术栈也不断增加。
服务拓扑不断增长。以前可能一个烟囱型的服务就可以了,而现在随着微服务的应用,服务之间的调度非常多,需要增长服务拓扑来满足需求。
随着服务规模的增长,运维复杂度呈现指数级增长,那运维人员是否也随着增长了呢?纵观各司,答案是否定的。出于节约成本的考虑,各司各岗位人员并不会随着服务复杂度增加而扩张,反而是越来越趋于平稳。基于这个比例,相当于运维复杂度越来越高的情况下,运维人员越来越少了。
中间的差距如何来弥补呢?这就需要运用到运维手段了。即上图所示的:运维质量=运维人员 X 运维手段。运维人员要通过各种运维手段来解决运维困境,进而推动运维的发展。
1.3 运维的发展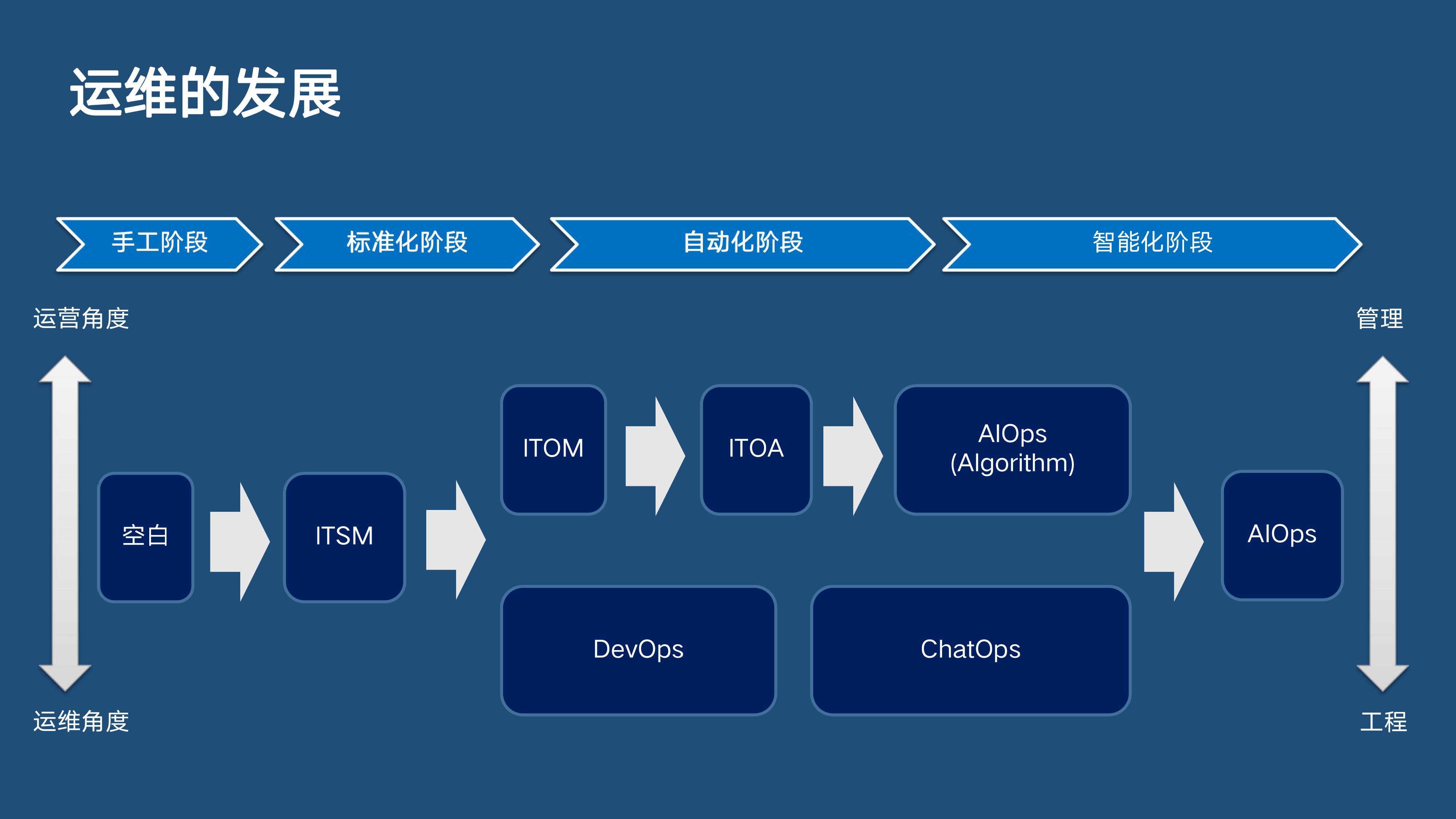
如图所示,运维的发展大致分为四个阶段:
1)手工阶段手工阶段比较好理解,研发人员交付一个系统,运维人员通过手工执行操作保障这个系统正常运行。此阶段的运维工作没有什么标准可言。
2)标准化阶段随着企业IT系统越来越多地引入运维,且所有业务都变成系统形式在线上运行,运维工作的重要性越来越高,但同时带来的是运维和研发、业务人员工作中的沟通壁垒。这时就衍生出了一些标准,其中最主要的是ITSM(IT Service Management,IT服务管理)。ITSM的目标是把日常所有的运维工作,包括流程、信息管理、风险控制等,通过系统建设和标准化固定下来,像流水线一样,人员只需要按照标准参与即可。
3)自动化阶段随着互联网大爆发,服务交付模型越来越多,用户对互联网和IT的要求越来越高,ITSM的缺点也越来越明显,主要表现为时间过长、成本过高,不能适应快速多变的需求。于是从工程或运维的角度自发出现了一种文化:DevOps,DevOps强调运维、研发及QA工程师工作的高度融合,要求运维从工程交付的角度不断迭代。