
MVCC实现的读写不阻塞正如其名:多版本并发控制--->通过一定机制生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。从用户的角度来看,好像是数据库可以提供同一数据的多个版本。
其中数据快照有两个级别:
语句级
针对于Read committed隔离级别
事务级别
针对于Repeatable read隔离级别
InnoDB 可重复读(Repeatable read)级别为什么可以大概率避免幻读表象:快照读(非阻塞读不加锁,对应加锁的叫当前读)伪MVCC
内在:next-key锁(行锁 + gap锁)
Mysql事务日志描述
使用事务日志,存储引擎在修改表的数据时只需要修改其内存拷贝,再把该修改行为记录到持久在硬盘上的事务日志中,而不用每次都将修改的数据本身持久到磁盘
事务日志采用的是追加的方式,因此写日志的操作是磁盘上一小块区域内的顺序I/O,而不像随机I/O需要在磁盘的多个地方移动磁头,所以采用事务日志的方式相对来说要快得多
事务日志持久以后,内存中被修改的数据在后台可以慢慢地刷回到磁盘,所以修改数据需要写两次磁盘
回滚日志 -- Undo Log
描述
保证事务的 原子性
在 MySQL 中,恢复机制是通过回滚日志(undo log)实现的,所有事务进行的修改都会先记录到这个回滚日志中,然后在对数据库中的对应行进行写入
重做日志 -- Redo Log
描述
保证事务的持久性
重做日志由两部分组成,一是 内存 中的重做日志缓冲区,因为重做日志缓冲区在内存中,所以它是易失的,另一个就是在 磁盘 上的重做日志文件,它是持久的
MySQL Server 日志binlog
描述
是 Mysql sever 层维护的一种二进制日志,其主要是用来记录对 mysql 数据更新或潜在发生更新的 SQL 语句,并以"事务"的形式保存在磁盘中
作用
复制:MySQL Replication 在 Master 端开启 binlog ,Master 把它的二进制日志传递给 slaves 并回放来达到 master-slave 数据一致的目的
数据恢复:通过 mysqlbinlog 工具恢复数据
增量备份
SQL语句执行得很慢的原因偶尔很慢
数据库在刷新脏页
redolog写满了
内存不够用了
MySQL 认为系统“空闲”的时候
MySQL 正常关闭的时候
拿不到锁
如果要判断是否真的在等待锁,我们可以用 show processlist
一直很慢
没用到索引
数据库选错了索引
SQL慢查询的优化分析过程
开启慢日志,查看慢日志,找到查询比较慢的语句
使用explain分析sql
分析结果中type字段,从好到坏是const、eq_reg、ref、range、index和all,是index和all就有问题需要优化
extra字段是Using filesort指用的外部索引例如文件系统索引等,Using temporary指用的临时表,这两种情况也需要优化
解决
没有索引可以试图建立索引,反复测试
加索引 alter table add index index_name()
有时候优化器选择不一定准确,需要手动测试,强制使用某一个索引可以在sql语句中加入 force index()
最后稳定之后再把不必要的索引删除
增加查询筛选的限制条件
改写一些导致索引失效的SQL语句
优化数据库结构
将字段很多的表分解成多个表
对于需要经常联合查询的表,可以建立中间表以提高查询效率
分解关联查询
将一个大的查询分解为多个小查询
优化LIMIT分页
筛选字段上加索引
先查询出主键id值
关延迟联
建立联合索引
索引为什么能提高查询速度
不使用索引如和查询
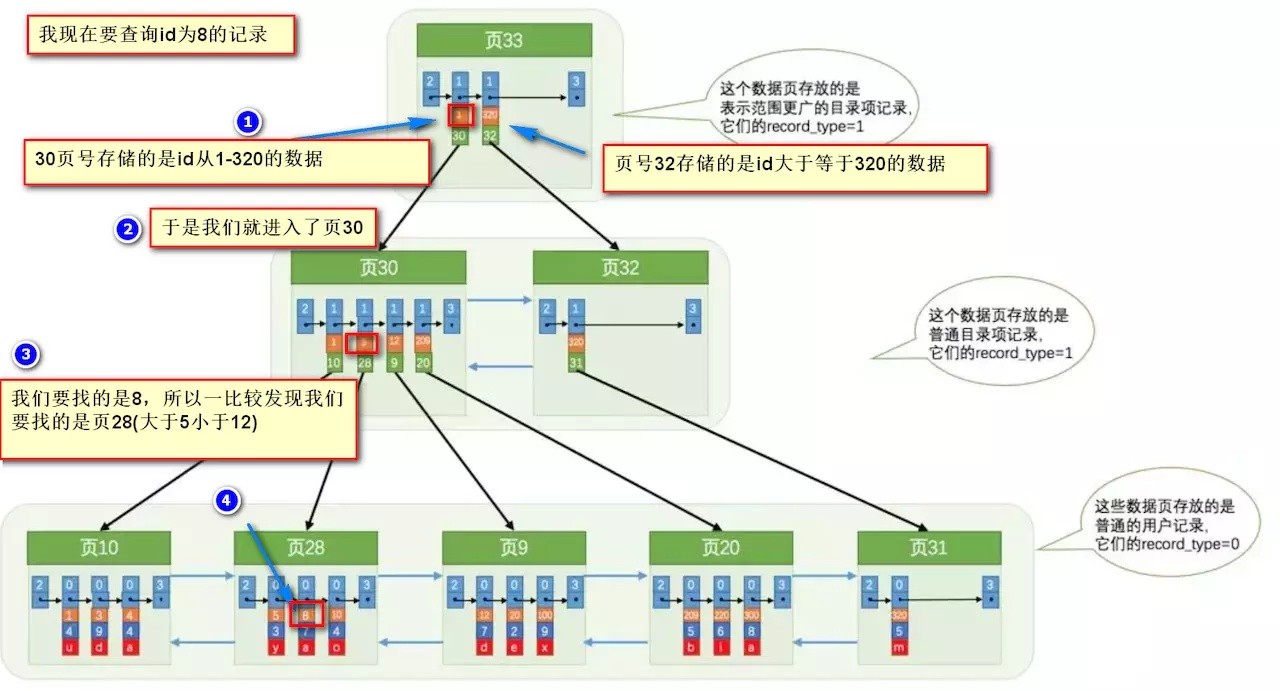
Mysql最小存储结构是页,页是一个单链表把数据连在一起
各个页通过双端链表连在一起
查询时,我们要遍历双端链表找到数据所在的页,然后再在页中遍历找到对应的数据项
而我们使用索引时Innodb默认使用B+树实现如下效果,大大提高了效率
哈希索引也没办法利用索引完成排序
不支持最左匹配原则
在有大量重复键值情况下,哈希索引的效率也是极低的---->哈希碰撞问题。
不支持范围查询
稀疏索引和聚集索引聚集索引
指索引项的排序方式和表中数据记录排序方式一致的索引
在叶子节点存储的是表中的数据
稀疏索引