
主定理:如果有一个问题规模为 n,递推的子问题数量为 a,每个子问题的规模为n/b(假设每个子问题的规模基本一样),递推以外进行的计算工作为 f(n)(比如归并排序,需要合并序列,则 f(n)就是合并序列需要的运算量),那么对于这个问题有如下递推关系式:
然后就可以套公式估算递归的时间复杂度
B树和B+树定义与区别M阶B树
定义
任意非叶子结点最多只有M个儿子,且M>2
根结点的儿子数为[2, M]
除根结点以外的非叶子结点的儿子数为[M/2, M],向上取整
非叶子结点的关键字个数=儿子数-1
所有叶子结点位于同一层
k个关键字把节点拆成k+1段,分别指向k+1个儿子,同时满足查找树的大小关系
特征
关键字集合分布在整颗树中
任何一个关键字出现且只出现在一个结点中
搜索有可能在非叶子结点结束
其搜索性能等价于在关键字全集内做一次二分查找
M阶B+树
定义
有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)
所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接
所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字
通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点
同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素
特征
b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”
b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢)
对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历
并查集用于解决
两个元素是否在同一个集合(优化,查的过程中把路过的节点直接连头节点)
合并两个元素所在的集合
实现
数组
双HashMap
红黑树特点
每个节点非红即黑
根节点总是黑色的
如果节点是红色的,则它的子节点必须是黑色的(反之不一定)
每个叶子节点都是黑色的空节点
从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
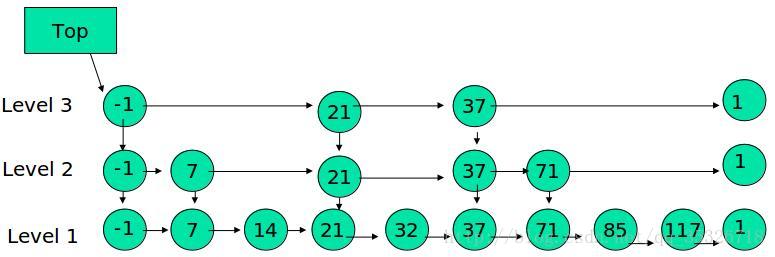
跳跃表
特点
最底层包含所有节点的一个有序的链表
每一层都是一个有序的链表
每个节点都有两个指针,一个指向右侧节点(没有则为空),一个指向下层节点(没有则为空)
必备一个头节点指向最高层的第一个节点,通过它可以遍历整张表
用于解决
常用于快速检索
大量字符串的排序和统计
基本性质
根节点不包含字符,除根节点外每个节点只包含一个字符
从根节点到某个节点,路径上所有的字符连接起来,就是这个节点所对应的字符串
每个节点的子节点所包含的字符都不同
如何从暴力递归改动态规范首先写好一个暴力递归
分析这个递归是否有重复计算
分析这个递归的当前状态和之前递归计算的顺序是不是无关
如果都满足就可以改成动态规划
改写成DP
找出递归中变化的参数
确定递归的开始位置
确定一些边界或者特殊情况
抽象出一次递归的步骤,分析步骤和已经固定的边界的关系
找出规律后coding
布隆过滤(Bloom Filter)解决问题:判断一个元素是否在一个集合中,优势是只需要占用很小的内存空间以及有着高效的查询效率
原理:保存了很长的二进制向量,同时结合 Hash 函数实现
首先需要k个hash函数,每个函数可以把key散列成为1个整数
初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
特点
只要返回数据不存在,则肯定不存在
返回数据存在,只能是大概率存在
不能清除其中的数据
计算误差
先根据样本大小n,可以接受的误差p,计算需要申请多大内存m
再由m,n得到hash function的个数k
再计算实际的误差p
Java 核心 HashMap应用场景
键值对高效存取
数据结构
1.7数组加链表
1.8数组加链表加红黑树
线程安全
不安全
多线程下使用扩容步骤存在问题
线程安全的替代
Hashtable
ConcurrentHashMap
默认大小
初始数组默认长度16
何时扩容
HashMap.Size >= Capacity * LoadFactor当前容量超过总容量乘以散列因子(默认0.75)就扩容,每次2倍扩容
扩容机制
jdk1.7