
基础 操作系统 I/O 模型
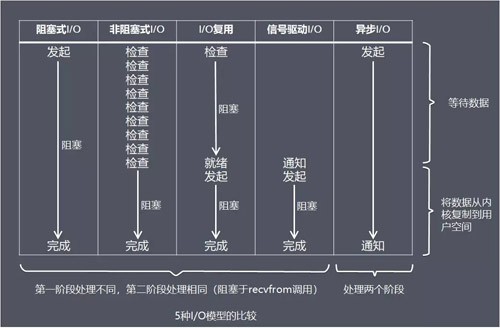
阻塞式 I/O 模型(blocking I/O)
描述:在阻塞式 I/O 模型中,应用程序在从调用 recvfrom 开始到它返回有数据报准备好这段时间是阻塞的,recvfrom 返回成功后,应用进程开始处理数据报
优点:程序简单,在阻塞等待数据期间进程/线程挂起,基本不会占用 CPU 资源
缺点:每个连接需要独立的进程/线程单独处理,当并发请求量大时为了维护程序,内存、线程切换开销较大,这种模型在实际生产中很少使用
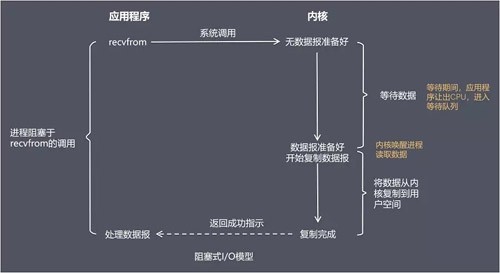
非阻塞式 I/O 模型(non-blocking I/O)
描述:在非阻塞式 I/O 模型中,应用程序把一个套接口设置为非阻塞,就是告诉内核,当所请求的 I/O 操作无法完成时,返回一个错误,应用程序基于 I/O 操作函数将不断的轮询数据是否已经准备好,直到数据准备好为止
优点:不会阻塞在内核的等待数据过程,每次发起的 I/O 请求可以立即返回,不用阻塞等待,实时性较好
缺点:轮询将会不断地询问内核,这将占用大量的 CPU 时间,系统资源利用率较低,所以一般 Web 服务器不使用这种 I/O 模型
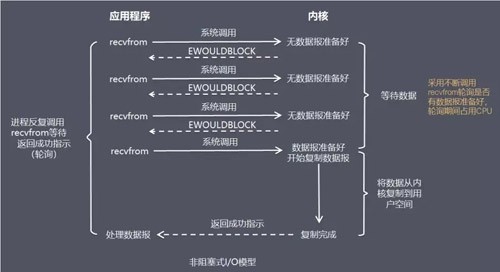
I/O 复用模型(I/O multiplexing)
描述:在 I/O 复用模型中,会用到 Select 或 Poll 函数或 Epoll 函数(Linux 2.6 以后的内核开始支持),可以同时阻塞多个 I/O 操作,而且可以同时对多个读或者写操作的 I/O 函数进行检测,直到有数据可读或可写时,才真正调用 I/O 操作函数
优点:可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程),这样可以大大节省系统资源
缺点:当连接数较少时效率相比多线程+阻塞 I/O 模型效率较低,可能延迟更大,因为单个连接处理需要 2 次系统调用,占用时间会有增加
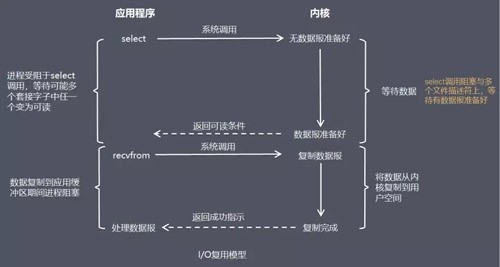
信号驱动式 I/O 模型(signal-driven I/O)
描述:在信号驱动式 I/O 模型中,应用程序使用套接口进行信号驱动 I/O,并安装一个信号处理函数,进程继续运行并不阻塞,当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 I/O 操作函数处理数据
优点:线程并没有在等待数据时被阻塞,可以提高资源的利用率
缺点:信号 I/O 在大量 IO 操作时可能会因为信号队列溢出导致没法通知,信号驱动 I/O 尽管对于处理 UDP 套接字来说有用,即这种信号通知意味着到达一个数据报,或者返回一个异步错误。但是,对于 TCP 而言,信号驱动的 I/O 方式近乎无用,因为导致这种通知的条件为数众多,每一个来进行判别会消耗很大资源,与前几种方式相比优势尽失
异步 I/O 模型(asynchronous I/O)
描述:由 POSIX 规范定义,应用程序告知内核启动某个操作,并让内核在整个操作(包括将数据从内核拷贝到应用程序的缓冲区)完成后通知应用程序。这种模型与信号驱动模型的主要区别在于:信号驱动 I/O 是由内核通知应用程序何时启动一个 I/O 操作,而异步 I/O 模型是由内核通知应用程序 I/O 操作何时完成
优点:异步 I/O 能够充分利用 DMA 特性,让 I/O 操作与计算重叠
缺点:要实现真正的异步 I/O,操作系统需要做大量的工作
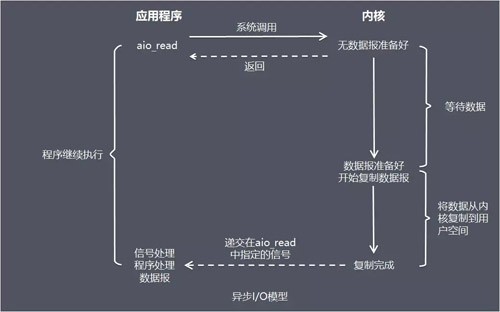
总结
这五种 I/O 模型中,前四种属于同步 I/O,因为其中真正的 I/O 操作(recvfrom)将阻塞进程/线程,只有异步 I/O 模型才与 POSIX 定义的异步 I/O 相匹配
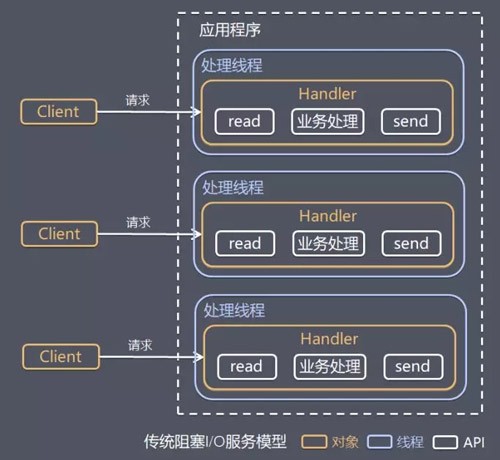
传统阻塞 I/O 服务模型
特点:
采用阻塞式 I/O 模型获取输入数据。
每个连接都需要独立的线程完成数据输入,业务处理,数据返回的完整操作
问题:
当并发数较大时,需要创建大量线程来处理连接,系统资源占用较大。
连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 Read 操作上,造成线程资源浪费
Reactor 模式
Reactor是非阻塞同步网络模型,通过一个或多个输入同时传递给服务处理器的服务请求的事件驱动处理模式, 基本设计思想就是I/O 复用模型结合线程池,Reactor 模式也叫 Dispatcher 模式
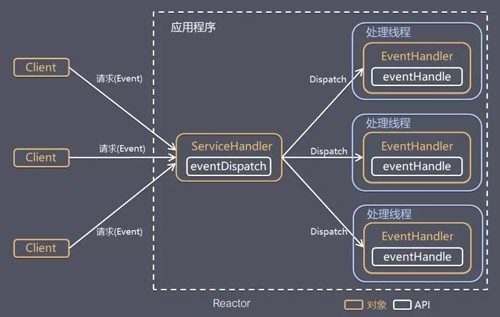
单 Reactor 单线程