Redis作为缓存利用,单历程单实例存在的问题:
单点妨碍
容量有限
压力过大
1|1Redis主从复制办理单点妨碍: AKF拆分原则:
x轴:全量、镜像。复制多个镜像,办理单点妨碍
y轴:按业务成果拆分为多个实例,同时在x轴偏向同时建设多份镜像。
z轴:优先级、逻辑再拆分。好比说某个模块数据过多,可以拆分为多个Redis客户端,全量数据分为多份,每个Redis中存一部门数据。
此时固然办理了单实例存在的三个问题,那么又会带来数据一致性问题。
办理数据一致性问题:
同步阻塞方法:

如果说一个客户端做了一个写操纵,达到主Redis,那么client将阻塞,直到主Redis通知两个备Redis都乐成写入才返回功效。这时候为强一致性,带来的问题是,如果说备用Redis这时候挂掉,没有写入乐成,那么主Redis期待超时之后,就返回给客户端失败,相当于处事不行用,粉碎了可用性。
异步方法:
弱一致性:
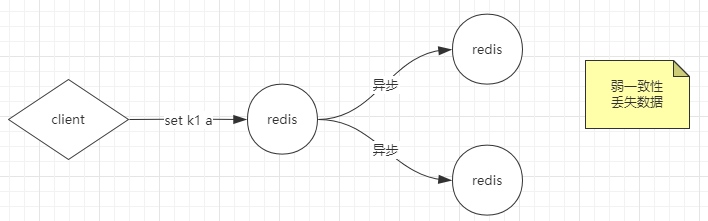
容忍数据丢失一部门,当client发送一个写请求,Redis立即返回OK,这时候通知备Redis去写,假如两个都写失败了,那么就会丢失数据。
最终一致性:

这种方法固然数据最终会一致,可是在这期间假如有客户端去读数据,大概会造成脏读。
小常识:主备与主从的区别
主备:备机一般不参加业务,当主挂了之后,备机可以取代主去提供处事。
主从:客户端可以会见主,也可以会见从。
Redis一般利用主从复制的模式,可是此时主本身又是一个单点。
对主做HA高可用:对主做高可用并不是说不让主呈现问题,而是对外表示为没有呈现问题。人工可以去把个中一个从机配置为主,让另一个从去跟随它。可是人往往是不行靠的,所以需要技能或措施来实现,主要是一个措施就会有单点妨碍的问题,所以措施也必需是一个集群。
如果说有三个监控措施监控一个主Redis的存活状态,那么也就是说Redis的存活状态由三个监控措施说了算。
强一致性,都给出OK:如果说都给出OK,才暗示Redis存活,那么一定会粉碎可用性,好比说个中一个监控阻塞了,而实际Redis还存活,这相当于监控不行用,所以不行取。
一部门给出OK,另一部门不算数:那么一部门是几个呢?如果拿三个监控举例,那么就只能是1可能2。
推导进程:
1个:统计禁绝确,不足势力范畴,因为每个都可以做主。大概会导致数据纷歧致,会有网络分区的问题,对外表示为同一处事拿到的数据差异,也就是脑裂。
并不是说产生脑裂欠好,有个观念叫分区容忍性。好比说SpringCloud中的Eureka注册中心,如果说原来有十个处事注册到差异的Eureka中,负载的时候需要打到差异的呆板上,每个负载发明的处事呆板数纷歧致,但并不影响,对客户端来说,只要有处事可用即可。
2个:这个时候会有两台结成势力范畴,两台之间相互通信,这时候给出的功效就是Redis要么存活,要么挂了,不会有中间状态。
2在3个节点乐成办理脑裂问题,3在4/5个节点乐成办理脑裂问题,可以得出结论,当有n个节点的时候需要n/2+1,也就是过半,一般利用奇数台。
为什么是奇数台?
3台、4台能遭受的风险都是只答允1台呈现问题,4台的本钱更高。
4台的时候比3台更容易呈现问题,即1台呈现问题的概率更大。
主从复制设置:
replica-serve-stale-data yes
暗示一个Redis在启动之后,而且将跟随一个主Redis,在主给生成RDB文件到从Redis去load RDB文件之前,是否提供查询处事。no的话,直到全部同步完之前不提供处事。
replica-read-only yes
备机是否开启只读模式。
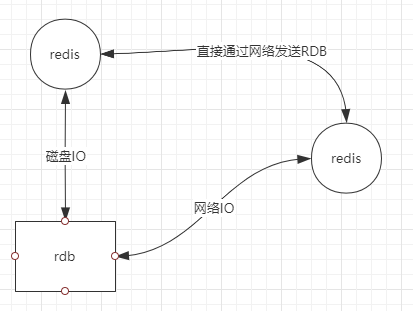
repl-diskless-sync no
主Redis发送RDB有两种方法,第一种方法是通过落到磁盘,从Redis再去load,第二种方法是直接通过网络发送RDB传给从Redis。这就取决于磁盘IO和网络IO哪个更快一些。设置no的话默认是走磁盘方法。
repl-backlog-size 1mb