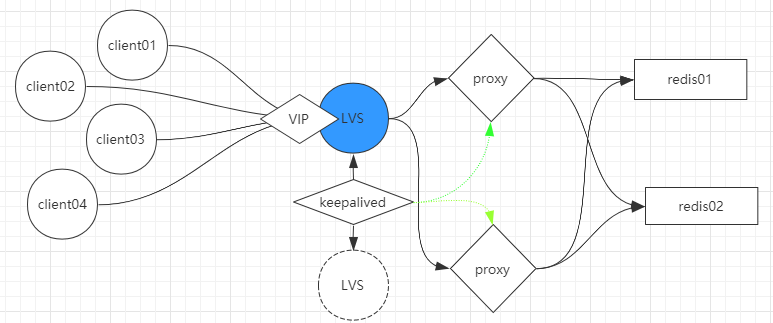
假如客户端许多,前面压力过大,一台署理撑不住的话,署理可以做一个集群,在署理之前还可以加一层LVS,不需要对署理层做高可用,因为假如LVS挂掉的话,后头处事都不行用了,所以LVS会做一个主备,主备之间靠keepalived来打点,除了可以监控LVS之外,还可以监控署理层的康健状态,假如个中一台署理挂了,那么只会走另一台。
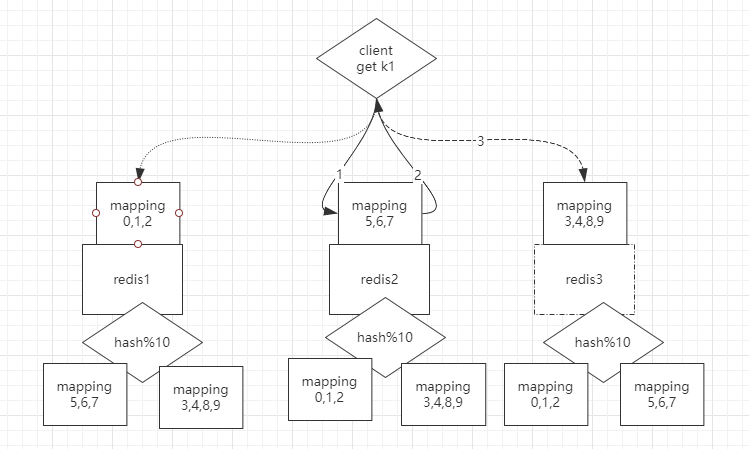
不管是在client照旧proxy的算法,新增一台Redis的时候总会有问题,要么从头取模全局洗牌,要么丢失一部门数据,所以爽性一开始取模值大一点,好比说取模为10,模数值的范畴09。此时中间还需要一层`mapping`做映射,如果说一开始有两台Redis1和Redis12,Redis1上是04槽位,Redis2上是5~9槽位,这样新增一个节点的时候,只需要从之前的Redis上让出几个槽位即可。那么在数据迁移的进程中,允不答允修改?这时候可以先把时点数据RDB传已往,再把增量的日志传已往。
Redis集群实现:cluster模式:只需要一个client,而且是无主模子,client连哪一个都行,在每一个Redis都有hash算法,还需要有其他Redis上的映射干系,如果说client要get一个k1,而k1按照hash取模算出来在4号槽位,而此时client毗连Redis2,那么会返回给客户端并跳转到key对应地址的Redis节点,找到之后直接返回给client即可。(查询路由)
数据分治会导致聚合操纵难以实现,好比说求两个荟萃的交集,两个荟萃在差异的Redis节点上。事务也难以支持,Redis并没有去实现,但可以工钱界说举办hash的算法,好比说用沟通的前缀(键哈希标签),这样数据就会存储到同一Redis节点上。
好比这两个键 {user1000}.following 和 {user1000}.followers 会被哈希到同一个哈希槽里,因为只有 user1000 这个子串会被用来计较哈希值。
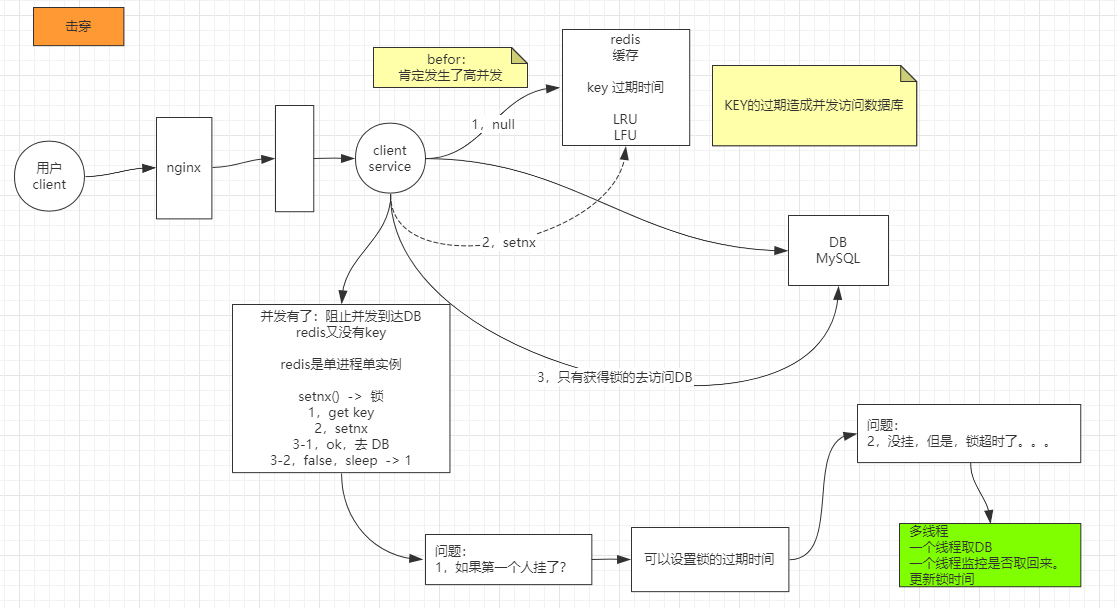
2|0Redis常见问题 2|1缓存击穿Redis的key会有逾期时间,包罗自带的LRU、LFU导致的裁减key,当在逾期的时候,正好有大量并发请求来查询这个key,这个时候请求会直接打到数据库上,称为缓存击穿。强调的是高并发对某个逾期key查询。
办理方案:
Redis是单历程单实例的,用setnx()加锁,第一个去获取key发明没有,然后加一把锁,加锁乐成的话,就去会见数据库,后头的加锁失败,就sleep期待,一般按照实际业务场景选择期待时间。
问题1:只要加锁就大概会有死锁的问题,如果说第一小我私家挂了怎么办?
可以配置锁的逾期时间
问题2:假如没挂,可是会见数据库阻塞了,导致锁超时了怎么办?
利用多线程,一个线程取数据库,一个线程监控是否取返来,更新锁的时间。可是这样的话会增加业务代码的巨大度。
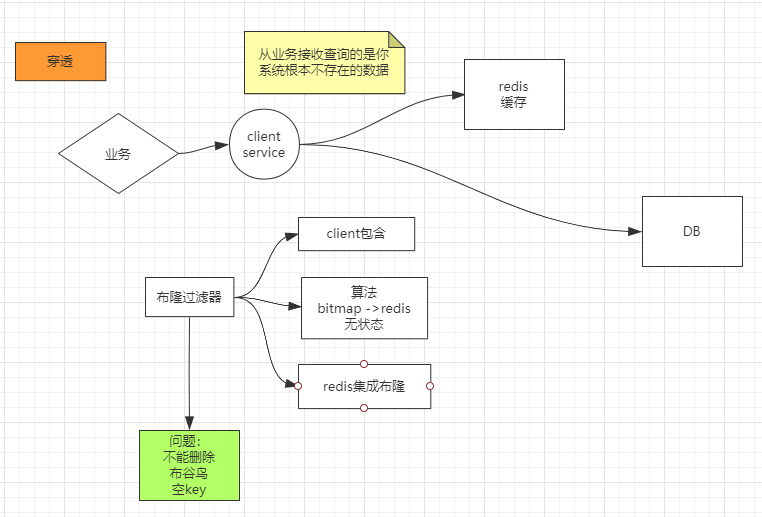
从业务系统吸收到的查询请求的是系统中基础不存在的数据,称为缓存穿透。
办理方案:
布隆过滤器:三种利用方法
client包括:压力到不了Redis,客户端代码巨大度高。
client只写算法,bitmap在Redis。
Redis集成布隆,客户端轻盈。
布隆过滤器的一个缺点是不能删除,假如有须要的话可以用布谷鸟过滤器,可能把key的值设为null。
大量的key同时失效,间接造成大量的会见达到数据库,为缓存雪崩。
办理方案:
两方面,一是时点性无关的话,把逾期时间随机,防备大量key同时逾期。
假如是业务上0点,可能1点失效的话,可以强依赖击穿方案,也可以在业务层加判定,做零点延迟,这样压力不会到Redis。