主从复制,增量复制。在Redis中,除了写入RDB文件外,还维护一个小的行列。当从Redis load完RDB之后,溘然挂掉了,然后处事又好了,这时候又需要去同步数据,可是此时的RDB文件已颠末期,可以把RDB文件从头包围一遍,可是假如此时文件很大的话,又需要挥霍时间。此时可以把一个偏移量给到主Redis,然后按照偏移量去获取增量数据,可是这时候取决于行列巨细,默认为1MB,假如写的速度很是慢,在这期间没有高出配置的巨细,那么是可以的,可是假如写的数据很是多,高出了配置的巨细,那么又会走全量复制,所以要按照实际写入的数据配置符合的行列巨细。

min-replicas-to-write 3 min-replicas-max-lag 10
可以配置最少写几个写乐成,当体贴数据一致性的时候,可以配置。默认是注释掉的,假如配置的话其实是在向强一致性靠拢,所以需按照实际应用场景设置。
HA高可用(x轴):
sentinel哨兵取代人工去自动修复妨碍,可以是单机也可以是集群,只监控master节点,因为master节点上有slave节点信息,通过宣布订阅发明其他哨兵。
1|2Redis办理容量问题: 办理方案client端:
当数据可以拆分的时候,可以按业务逻辑拆分,并分派到各个Redis实例。

当数据不行拆分的时候,有三种办理方案(sharding分片):
这三种模式都只能作为缓存用,不能做数据库用。
操作算法:hash+取模(modula),模的巨细为Redis实例数。当key颠末hash之后,存放在某一台Redis实例中。
漏洞:取模的数必需牢靠,当再增加Redis实例时,大概会取不到本来的值,需要从头取模,全局洗牌,影响漫衍式下的扩展性。

random随机:这种有一个应用场景,一般用于list范例,即动静行列。当并发流量大时,可以用Redis作为缓冲,可是一台实例有扛不住,可以多搞几台,每一台上有沟通的key,当client去lpush一个key时,随机写到一台Redis实例中,另一个client去rpop,这个key其实相当于topic,而每个Redis相当于partition,就是kafka的模子,只不外kafka是基于磁盘的,数据可以从头消费,Redis是基于内存的,速度快。

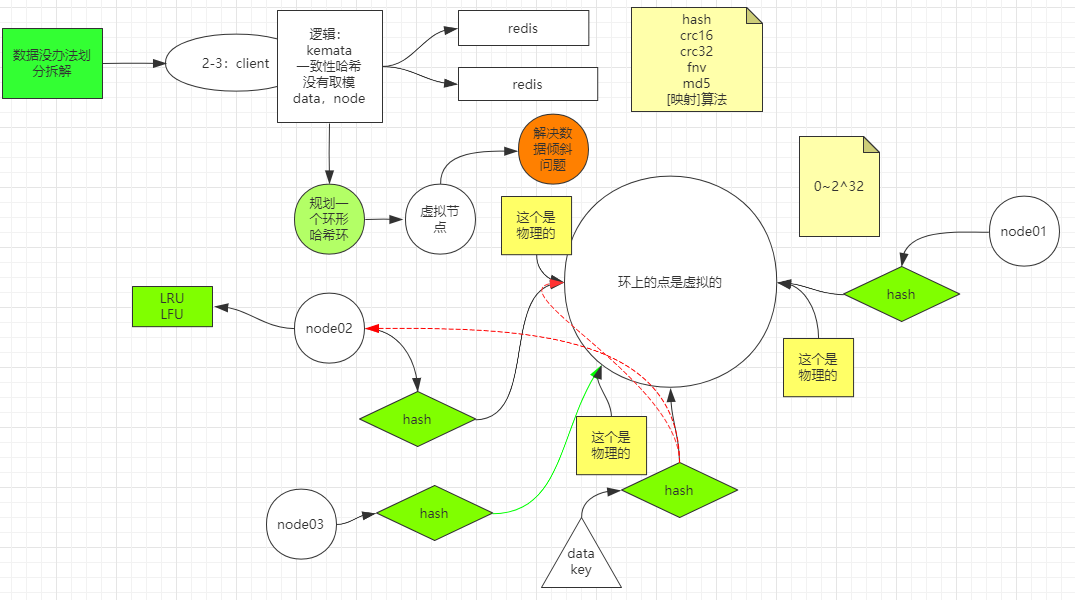
一致性哈希(ketama)
筹划一个环形哈希环,环上有许多点,好比说0~2^32,然后有一个映射算法(如hash、md5等许多),有两个Redis节点,别离为node01,node02,把这两个节点信息通过一个hash算法映射到这个环上某一个点,这两个点是物理的,其他的点都是虚拟的。当一个数据(data)进来时,也颠末这个hash算法映射在环上某个点,如果说这些点都在一个排好序的荟萃里(好比说TreeMap),然后遍历这个map去找大于这个点的最近的物理点在哪,找到这个点代表的物理机然后存放进去,即存到了node02中。如果说此刻想加一个node03,颠末hash后刚巧分派到了两个物理节点之间。
利益:增加节点可以分管其他节点的压力,不会造成像取模一样全局洗牌。
缺点:
问题:新增节点导致一小部门数据不能掷中,大概会造成缓存击穿。
方案:每次取的时候,找离我最近的两个物理节点。
那么在取不到的数据存在node02节点上会造成空间挥霍,可以操作Redis自带的接纳计策,譬喻LRU、LFU。
扩展:在哈希环上增加虚拟节点,一个物理设备可以通过hash算法映射为多个虚拟节点,使数据存储更匀称。
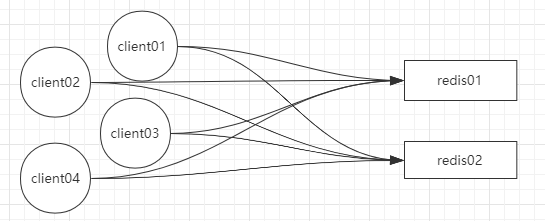
上述算法都是产生在客户端的,那么当客户端毗连Redis的时候,socket毗连过多,对server端的影响是毗连本钱很高。
此时可以用署理的方法办理,让所有的客户端去毗连中间署理,此时server端的socket毗连压力不大,只需要体贴署理层机能即可。
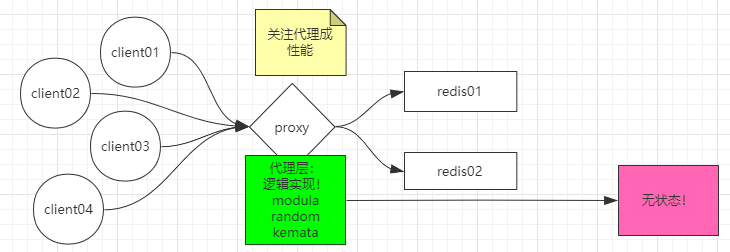
所谓无状态,就是自己并不需要数据库,不需要存储数据,数据是存在后端的,只有到达无状态的署理,像Nginx这种,才更容易一变多。