
对于二级索引来说,索引列的值可能为NULL,对于索引列值为NULL的二级索引记录来说,它们被放在B+树的最左边。由此,可以看出SQL中的NULL值认为是列中最小的值。因此,is null使用了索引,is not null由于需要查询所有值,最终还需要回表到主键索引,因此,直接使用全部扫描。
上述现象的本质还是优化器对索引成本的估算,如果上述案例中a is NULL的数量达到一定的程度,回表成本增加,可能就会被优化器放弃,改走全部扫描。
同理,!=、not in是否走索引,都是同样的原理。
select count()在不同的 MySQL 引擎中,count(*) 有不同的实现方式。
MyISAM 引擎:表的总行数存在磁盘上,没有where条件的情况下,会直接返回这个数,效率很高;
InnoDB 引擎:由于MVCC,不同事务中返回多少行是不确定的,需要把数据一行一行地从引擎里面读出来,然后累积计数。因此,优化器会找到最小的索引树来遍历
不同count的用法对比:
count(1):InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加
count(*):MySQL专门进行了优化,不取值,等价于count(1),建议优先使用
count(主键id):InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加
count(字段):
如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;
如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加
order by工作方式 CREATE TABLE `t` ( `id` INT (11) NOT NULL, `city` VARCHAR (16) NOT NULL, `name` VARCHAR (16) NOT NULL, `age` INT (11) NOT NULL, `addr` VARCHAR (128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE = INNODB; select city,name,age from t where city='杭州' order by name limit 1000; -- MySQL中用于控制排序行数据长度的一个参数,如果单行的长度超过这个值,改用rowid排序 SET max_length_for_sort_data = 16; 全字段排序 rowid 排序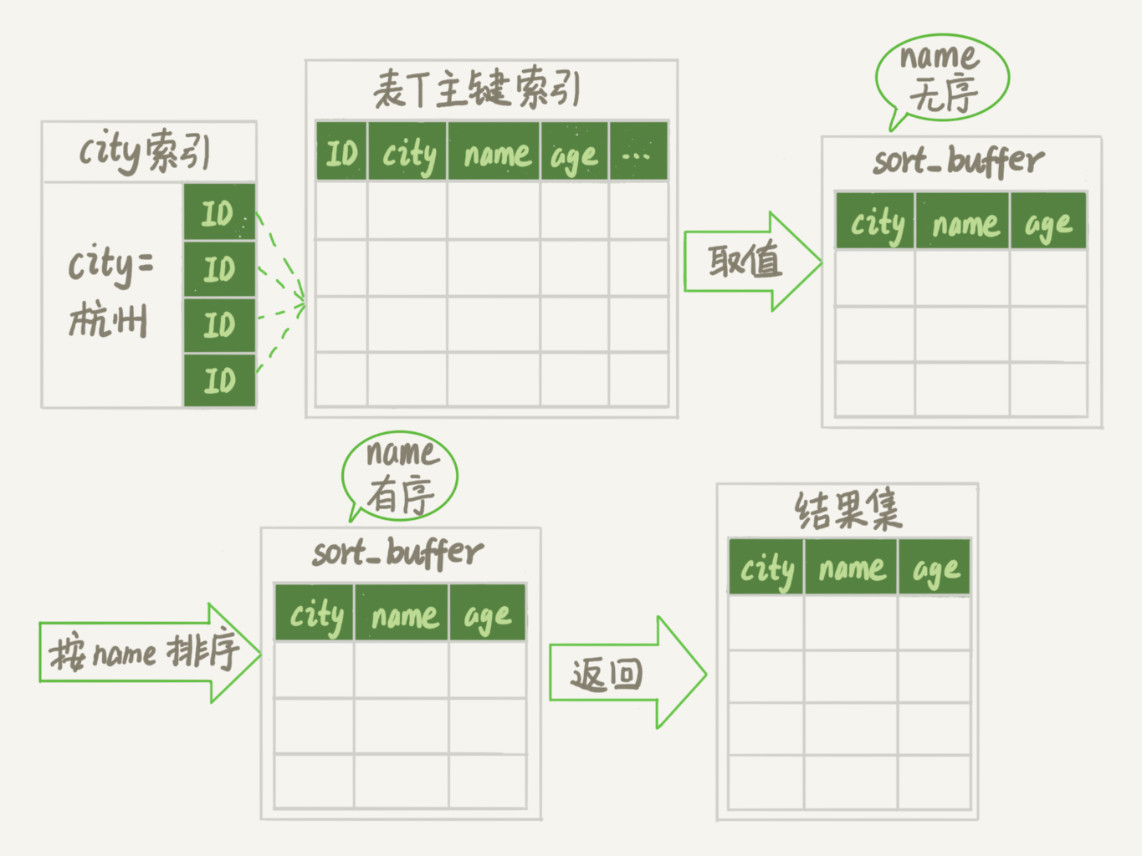
sort_buffer_size:如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。反之,利用磁盘临时文件辅助排序
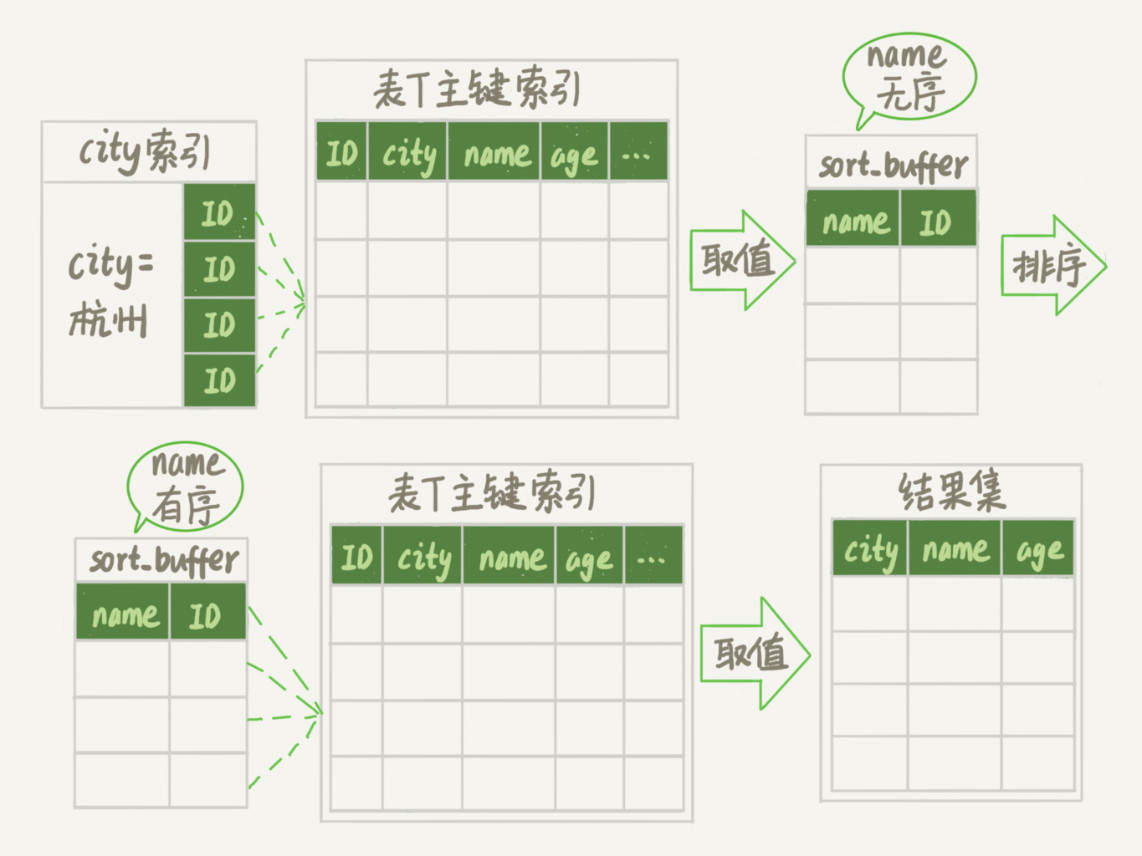
rowid 排序多访问了一次表 t 的主键索引,因此,MySQL会优先选择全字段排序,可以通过修改参数max_length_for_sort_data让优化器选择rowid排序算法,默认16,当要查询的单条数据全文本长度大于16采用rowid排序
对于需要使用临时表进行排序时,需要看临时表是内存临时表,还是磁盘临时表,由tmp_table_size决定,默认16M。若是内存临时表,回表在内存中完成,不会访问磁盘,优先选用rowid排序
优化方案:使数据本身有序
alter table t add index city_user(city, name); -- 利用索引中相同city下name有序性 select city,name,age from t where city='杭州' order by name limit 1000; -- 进一步优化,使用覆盖索引,减少回表 alter table t add index city_user_age(city, name, age); -- city多值情况下,又该如何处理? sql拆分 select * from t where city in ('杭州'," 苏州 ") order by name limit 100; group by优化 CREATE TABLE t1 ( id INT PRIMARY KEY, a INT, b INT, INDEX (a) ); select id%10 as m,count(*) as c from t2 group by m;首先分析下group by语句的执行计划,如下:
-- 此处使用MySQL 8.0+,已取消group by隐式排序,否则Exta中还会多一个Using filesort mysql> explain select id%10 as m,count(*) from t group by m; +----+-------------+-------+------------+-------+---------------+-----+---------+------+--------+----------+------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----+---------+------+--------+----------+------------------------------+ | 1 | SIMPLE | t2 | NULL | index | PRIMARY,a | a | 5 | NULL | 998529 | 100 | Using index; Using temporary | +----+-------------+-------+------------+-------+---------------+-----+---------+------+--------+----------+------------------------------+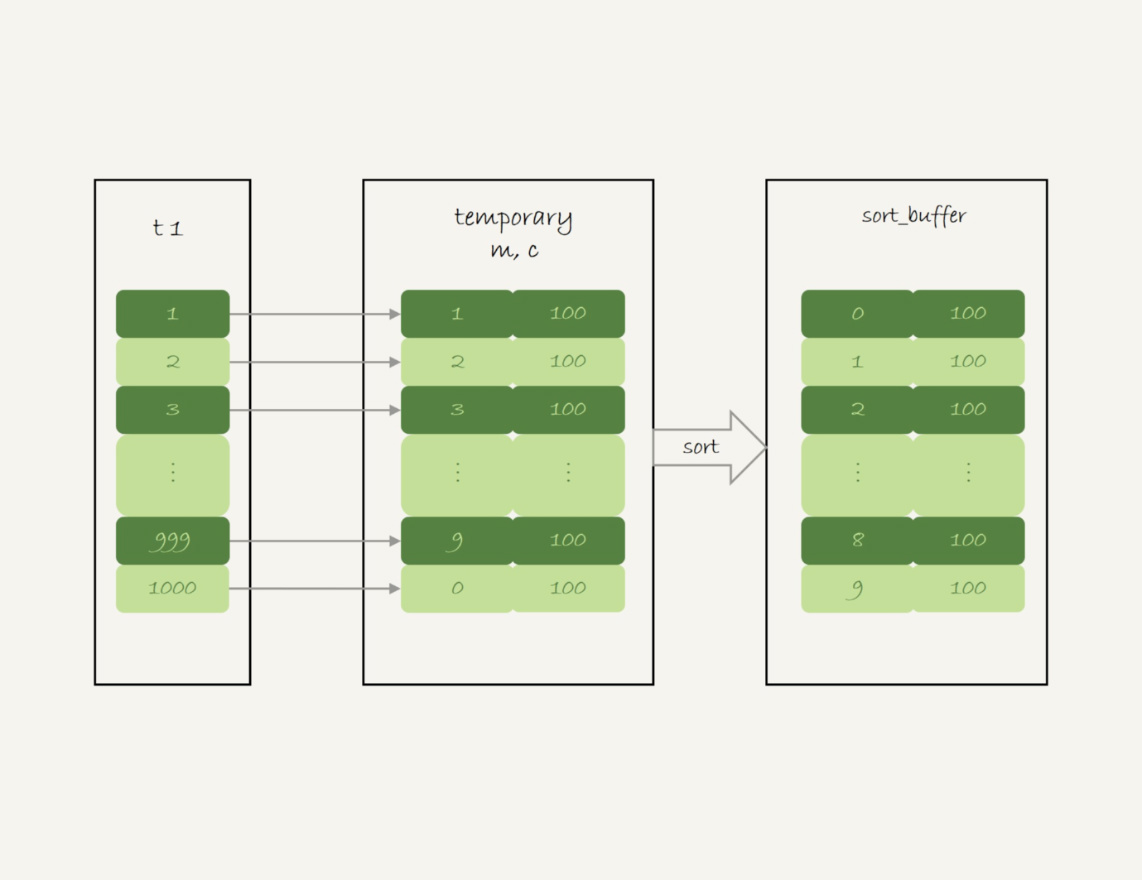
只用到了主键id字段,可以使用覆盖索引,因此选择了索引a,不用回表
获取主键id,id%10后放入临时表,如果存在,计数列加1
MySQL 8.0前group by支持隐式排序,无排序需求时,建议加上order by null
如何优化?