
适合创建索引,直接加索引
-- 此处举例中分组字段是不存在,新增一个,并创建索引 -- 实际场景中可能会有已有分组字段,但未加索引,加上索引即可 mysql> alter table t1 add column z int generated always as(id % 100), add index(z); -- 使用索引字段进行分组排序 mysql> explain select z as m,count(*) from t1 group by z ; +----+-------------+-------+------------+-------+---------------+-----+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | index | z | z | 5 | NULL | 1000 | 100 | Using index | +----+-------------+-------+------------+-------+---------------+-----+---------+------+------+----------+-------------+
索引是有序的,顺序扫描,依次累加,统计完一个再统计下一个,不需要暂存中间结果,也不需要额外排序。如果需要倒序排列,Backward index scan,从后扫描索引即可
多个分组字段,建议使用联合索引
不适合创建索引,数据量不大,走内存临时表即可。如果数据量较大,使用SQL_BIG_RESULT告诉优化器,放弃内存临时表,直接磁盘临时表
mysql> explain select SQL_BIG_RESULT id%10 as m,count(*) from t1 group by m ; +----+-------------+-------+------------+-------+---------------+-----+---------+------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----+---------+------+------+----------+-----------------------------+ | 1 | SIMPLE | t1 | NULL | index | PRIMARY,a,z | a | 5 | NULL | 1000 | 100 | Using index; Using filesort | +----+-------------+-------+------------+-------+---------------+-----+---------+------+------+----------+-----------------------------+通过执行计划可以看出实际并未使用临时表,为什么呢?
因此,磁盘临时表是B+树存储,存储效率不高,从磁盘空间考虑,直接使用数组存储,流程如下:
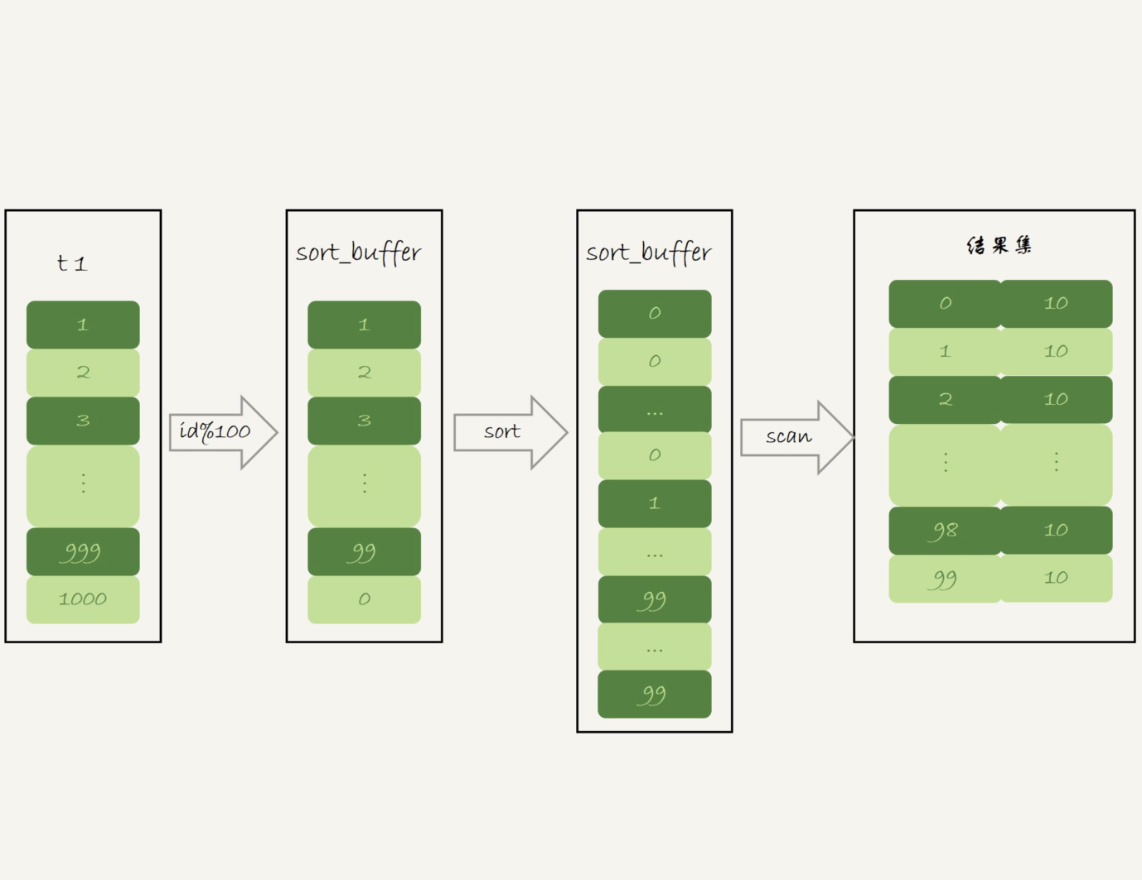
直接把分组值m放在sort_buffer中,空间不足使用磁盘临时文件辅助排序,这样就得到一个有序数组。在有序数组上计算相同值出现的次数就比较简单了,和在索引上统计计数一样,逐个累加计数即可。
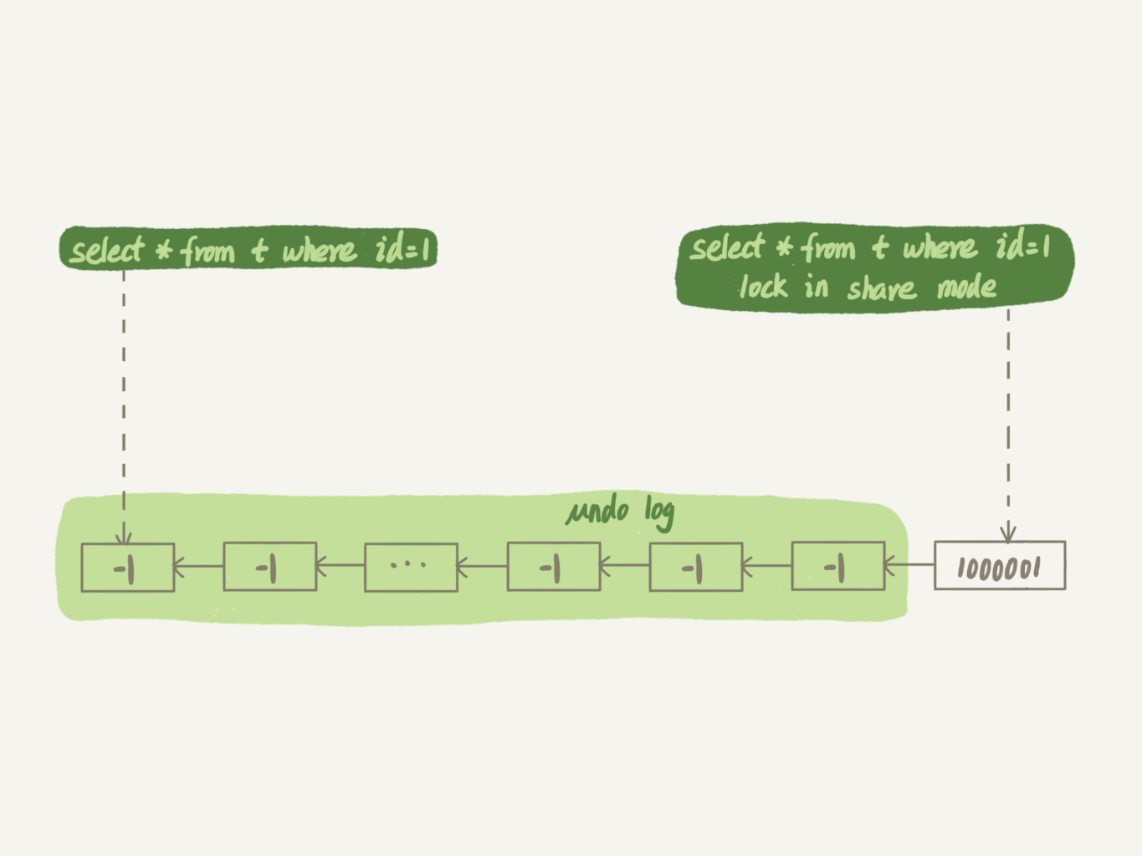
慢查询分析示例1:
session A session Bstart transaction with consistent snapshot;
update t set c=c+1 where id=1;//执行100万次
select * from t where id=1;
select * from t where id=1 lock in share mode;
示例2:
-- 创建表t CREATE TABLE `t` ( `id` INT (11) NOT NULL, `b` VARCHAR (10) NOT NULL, PRIMARY KEY (`id`), KEY `b` (`b`) ) ENGINE = INNODB; -- 值超出字段长度,字符串截断后传递给执行引擎,可能匹配上大量数据,最终导致大量回表二次验证b='1234567890abcd' explain select * from t where b='1234567890abcd'; -- 类型隐式转换,扫描全部索引树 explain select * from t where b=1235 互关问题设计业务上有这样的需求,A、B 两个用户,如果互相关注,则成为好友。
-- 创建关注表 CREATE TABLE `like` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `user_id` INT (11) NOT NULL, `liker_id` INT (11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_user_id_liker_id` (`user_id`, `liker_id`) ) ENGINE = INNODB; -- 创建好友表 CREATE TABLE `friend` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `friend_1_id` INT (11) NOT NULL, `friend_2_id` INT (11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_friend` ( `friend_1_id`, `friend_2_id` ) ) ENGINE = INNODB; session1(A关注B,A=1,B=2) session2(B关注A,A=1,B=2)begin;
select * from user_like where user_id=2 and liker_id=1;(Empty set) begin;
insert into user_like(user_id,liker_id) values(1,2);
select * from user_like where user_id=1 and liker_id=2;(Empty set)
insert into user_like(user_id,liker_id) values(2,1);
commit;
commit;