
如果要问最近几年,IT行业哪个技术方向最火?一定属于ABC,即AI + Big Data + Cloud,也就是人工智能、大数据和云计算。
这几年,随着互联网大潮走向低谷,同时传统企业纷纷进行数字化转型,基本各个公司都在考虑如何进一步挖掘数据价值,提高企业的运营效率。在这种趋势下,大数据技术越来越重要。所以,AI时代,还不了解大数据就真的OUT了!
相比较AI和云计算,大数据的技术门槛更低一些,而且跟业务的相关性更大。我个人感觉再过几年,大数据技术将会像当前的分布式技术一样,变成一项基本的技能要求。
前几天,我在团队内进行了一次大数据的技术分享,重点是对大数据知识做一次扫盲,同时提供一份学习指南。这篇文章,我基于分享的内容再做一次系统性整理,希望对大数据方向感兴趣的同学有所帮助,内容分成以下5个部分:
1、大数据的发展历史
2、大数据的核心概念
3、大数据平台的通用架构和技术体系
4、大数据的通用处理流程
5、大数据下的数仓体系架构
01 大数据的发展历史在解释「大数据」这个概念之前,先带大家了解下大数据将近30年的发展历史,共经历了5个阶段。那在每个阶段中,大数据的历史定位是怎样的?又遇到了哪些痛点呢?
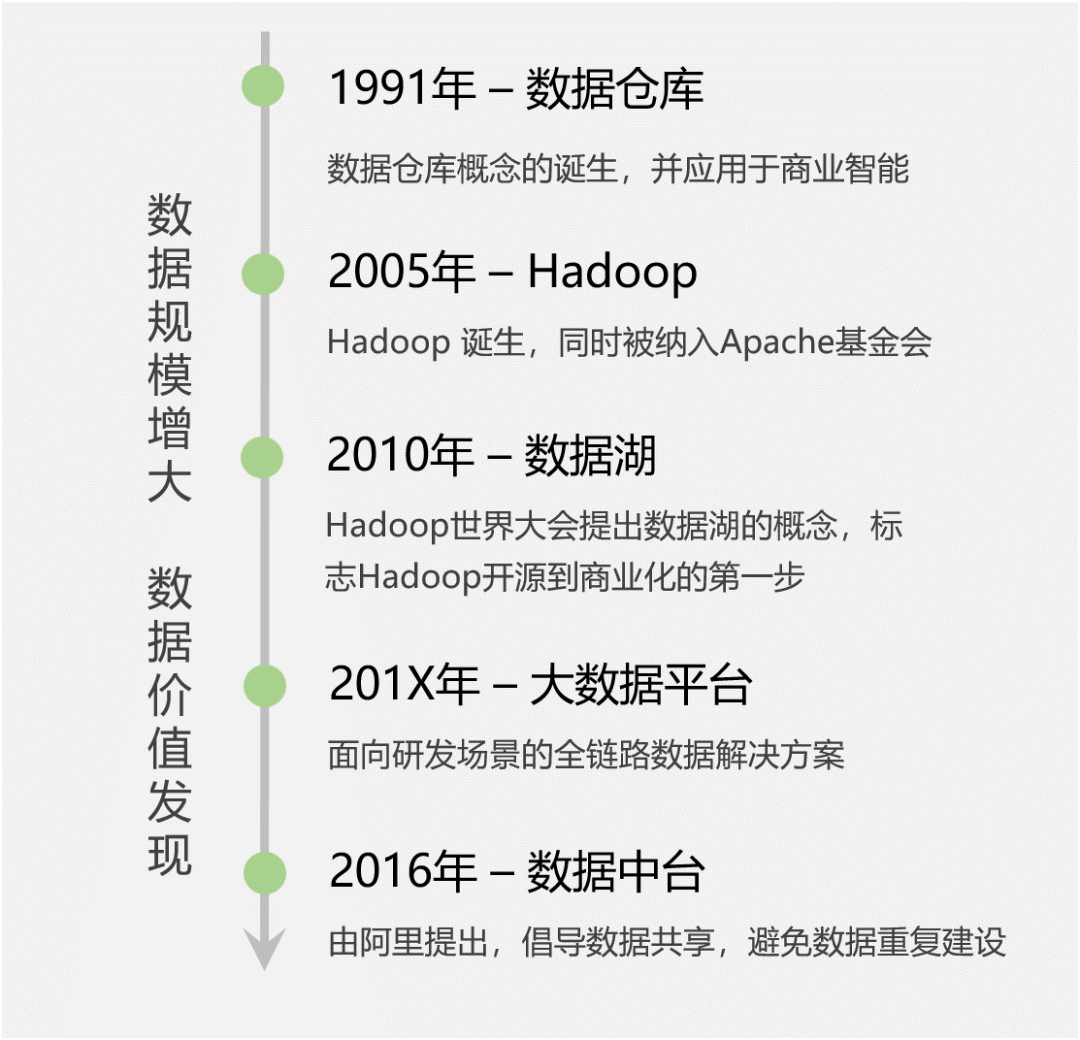
20世纪90年代,商业智能(也就是我们熟悉的BI系统)诞生,它将企业已有的业务数据转化成为知识,帮助老板们进行经营决策。比如零售场景中:需要分析商品的销售数据和库存信息,以便制定合理的采购计划。
显然,商业智能离不开数据分析,它需要聚合多个业务系统的数据(比如交易系统、仓储系统),再进行大数据量的范围查询。而传统数据库都是面向单一业务的增删改查,无法满足此需求,这样就促使了数据仓库概念的出现。
传统的数据仓库,第一次明确了数据分析的应用场景,并采用单独的解决方案去实现,不依赖业务数据库。
1.2 技术变革:Hadoop诞生
2000年左右,PC互联网时代来临,同时带来了海量信息,很典型的两个特征:
数据规模变大:Google、雅虎等互联网巨头一天可以产生上亿条行为数据。
数据类型多样化:除了结构化的业务数据,还有海量的用户行为数据,以图像、视频为代表的多媒体数据。
很显然,传统数据仓库无法支撑起互联网时代的商业智能。2003年,Google公布了3篇鼻祖型论文(俗称「谷歌3驾马车」),包括:分布式处理技术MapReduce,列式存储BigTable,分布式文件系统GFS。这3篇论文奠定了现代大数据技术的理论基础。
苦于Google并没有开源这3个产品的源代码,而只是发布了详细设计论文。2005年,Yahoo资助Hadoop按照这3篇论文进行了开源实现,这一技术变革正式拉开了大数据时代的序幕。
Hadoop相对于传统数据仓库,有以下优势:
完全分布式,可以采用廉价机器搭建集群,完全可以满足海量数据的存储需求。
弱化数据格式,数据模型和数据存储分离,可以满足对异构数据的分析需求。
随着Hadoop技术的成熟,2010年的Hadoop世界大会上,提出了「数据湖」的概念。
数据湖是一个以原始格式存储数据的系统。
企业可以基于Hadoop构建数据湖,将数据作为企业的核心资产。由此,数据湖拉开了Hadoop商业化的大幕。
1.3 数据工厂时代:大数据平台兴起商用Hadoop包含上十种技术,整个数据研发流程非常复杂。为了完成一个数据需求开发,涉及到数据抽取、数据存储、数据处理、构建数据仓库、多维分析、数据可视化等一整套流程。这种高技术门槛显然会制约大数据技术的普及。
此时,大数据平台(平台即服务的思想,PaaS)应运而生,它是面向研发场景的全链路解决方案,能够大大提高数据的研发效率,让数据像在流水线上一样快速完成加工,原始数据变成指标,出现在各个报表或者数据产品中。
1.4 数据价值时代:阿里提出数据中台2016年左右,已经属于移动互联网时代了,随着大数据平台的普及,也催生了很多大数据的应用场景。
此时开始暴露出一些新问题:为了快速实现业务需求,烟囱式开发模式导致了不同业务线的数据是完全割裂的,这样造成了大量数据指标的重复开发,不仅研发效率低、同时还浪费了存储和计算资源,使得大数据的应用成本越来越高。