
对于云计算行业来说,云服务的可用性和可扩展性是的检测其服务质量的重要标准,也是最受用户关注的两大难题。各云计算厂商针对容灾、升级等需求的解决方案,最能够体现其底层架构的实力。腾讯云基于基础架构的优势,为分期乐、微信红包等平台提供技术支持,可以完美满足如下三点需求:
1. 高可用能力,容灾能力强,升级不停服
2. 可扩展性强,功能丰富,性能超高
3. 避免重复造轮子,性价比之王
近期,针对一些客户对腾讯云产品可用性的问询,腾讯云基础产品团队对负载均衡产品的原理做出详细阐述,并希望通过对腾讯负载均衡集群底层架构的实现的讲解分析,揭示其强劲性能、高可用性的根源所在。
一、什么是负载均衡单台web 服务器如 apache、nginx 往往受限于自身的可扩展硬件能力。在面对海量的 web 请求时,需要引入load balance将访问流量均匀的分发到后端的web集群,实现接入层的水平扩展。
Tencent 所有业务的负载均衡都是基于内部 Tencent GateWay 实现的,运行在标准x86服务器上,优点包括:自主研发、代码可控。Tencent GateWay 对外的版本为 Cloud load balance,是多机 active 部署的,通过 BGP 发布VIP、local adress 路由、同步 DNS 信息等,实现集群负载通过路由 OSPF 将流量分发到不同的服务器上。
Load balance 作为 IT 集群的出入口、咽喉要塞。开发商使用负载均衡器看中的无非是高可用能力、分发性能以及产品功能的丰富程度,咱先从高可用说起。
二、高可用能力 a. 单集群容灾能力集群容灾,简单来说就是一个集群中一台服务器倒掉不会影响整个集群的服务能力。LVS是国内厂商常用的开源框架,常用Keepalived完成主备模式的容灾。有3个主要缺点:
1、主备模式利用率低。一个集群同时只有一半的服务器在工作,另外一半的机器处于冷备状态,主节点不可用之后的切换速度相对较慢;
2、横向平行扩展能力差。LVS服务集群扩展后转发效率大幅下降;
3、依赖的VRRP协议存在脑裂的风险,需引入第三方仲裁节点,在金融领域、跨园区容灾领域备受挑战。
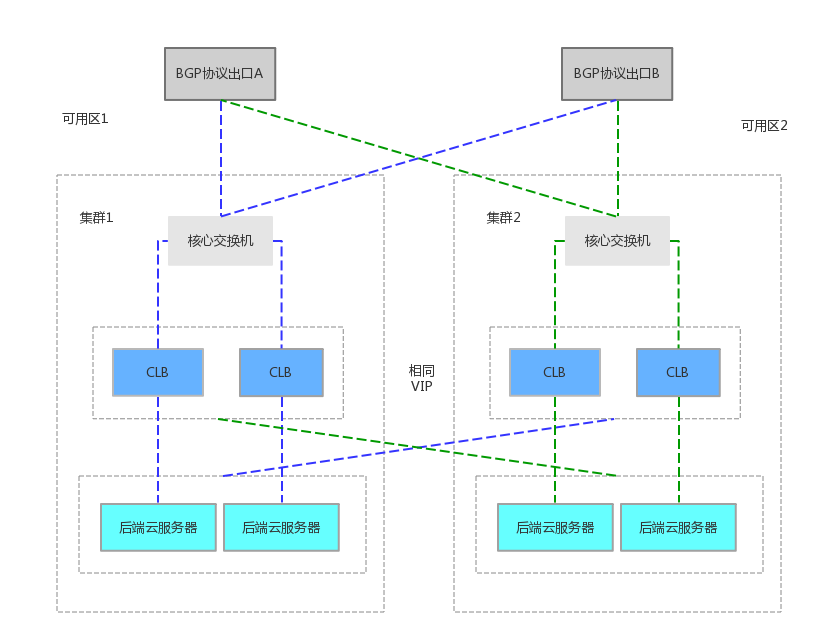
CLB在设计之初就考虑到这个问题,采用自研的ospf动态路由协议来实现集群的容灾,若一台机器倒掉,ospf协议可以保证在10s以内把机器从集群中剔除。
CLB一个集群放在两个接入交换机下,并且保证跨机架的容灾,这样保证在即便有单边的交换机出故障或者单边机架掉电时,本集群的服务不受影响。同事实现了集群内session连接定期同步。这样在别的服务器接管故障机器的包时,client端的用户体验不受影响(如未登录的账户,在电商购物车里的未付款商品不丢失)
b. 跨园区容灾能力为了满足金融核心客户,24小时核心业务持续服务的要求。腾讯云负载均衡已在各金融专区(region)部署了多可用区(zone)容灾套件,从路由器、交换机和服务器以及布线是全冗余的,任意一个路由器、交换机或者服务器接口挂掉之后,流量会从冗余组件提供服务。
当client端请求,经过CLB代理,访问到后端CVM时,负载均衡的源 ip、目的ip、转发策略、会话保持机制,健康探测机制等业务配置。会实时的同步到另一个zone的集群。当主可用区的机房故障、不可用时,负载均衡仍然有能力在非常短的时间内(小于10s)切换到另外一个备可用区的机房恢复服务能力,而业界产品的切换时间一般在分钟级别。当主可用区恢复时,负载均衡同样会自动切换到主可用区的机房提供服务。目前包括webank、富途证券等金融开发商已启用跨园区容灾能力。
容灾演练实测:
1、协议切换(模拟交换机、CLB集群任何一层故障导致整个机房外网LB不可用),切换时间ping丢包不超过1秒,但长链接会瞬断,结果符合预期。
2、在高可用机房的LB外网完全瘫痪发生切换,恢复后不主动回切,过程中瘫痪机房的任何操作不应影响另外一边,结果符合预期。
3、模拟(与CLB开发商沟通好以后)流量回切操作,流量回切时间ping丢包不超过1秒,但长链接发生瞬断,结果符合预期。
c. 升级不停服CLB内核升级、Linux 内核缺陷、安全漏洞等原因,免不了要做后端集群的重启升级,如果服务器每年由于维护等原因重启一次,1小时的恢复时间就已经达不到99.99%的可用性了。