
众所周知,Redis是一个单线程架构的NoSQL数据库,但是是单线程模型的Redis为什么性能如此之高?这就是我们接下来要探究学习的内容。
1、Redis的单线程架构 1.1、Redis单线程简介首先要明白,Redis的单线程指的是执行命令时的单线程。
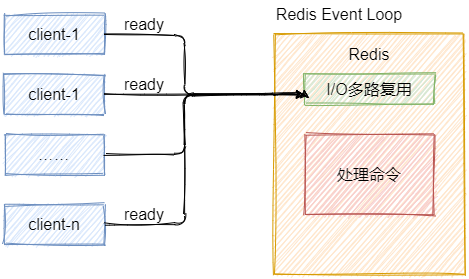
Redis客户端与服务端的模型可以简化成下图,每次客户端调用都经历了发送命令、执行命令、返回结果三个过程。

我们说的单线程就是在第二步执行命令,一条命令从从客户端达到服务端不会立刻被执行,而是会进入一个队列中等待,每次只会有一条指令被选中执行。

发送命令、返回结果、命令排队这些就不是那么简单了,例如Redis使用了I/O多路复用技术来解决I/O的问题。
1.2、Redis为什么要使用单线程这是官方的解释:https://redis.io/topics/faq

官方FAQ表示,因为Redis是基于内存的操作,CPU成为Redis的瓶颈的情况很少见,Redis的瓶颈最有可能是内存的大小或者网络限制。
如果想要最大程度利用CPU,可以在一台机器上启动多个Redis实例。
值得一提的,网络上存在这样的观点:吐槽官方的解释有些敷衍,其实就是历史原因,开发者嫌多线程麻烦,后来这个CPU的利用问题就被抛给了使用者。
同时FAQ里还提到了, Redis 4.0 之后开始变成多线程,除了主线程外,它也有后台线程在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 Key 的删除等等。
1.3、为什么单线程还能这么快通常来讲,单线程处理能力要比多线程差,那么为什么Redis使用单线程模型会达到每秒万级别的处理能力呢?可以将其归结为三点:
第一:纯内存访问,Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,这是Redis达到每秒万级别访问的最重要的基础。
第二:非阻塞I/O,Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间
这里再扩展一下I/O多路复用:
引用知乎上一个高赞的回答来解释什么是I/O多路复用。假设你是一个老师,让30个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:
第一种选择:按顺序逐个检查,先检查A,然后是B,之后是C、D。。。这中间如果有一个学生卡主,全班都会被耽误。这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者线程处理连接。
第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。
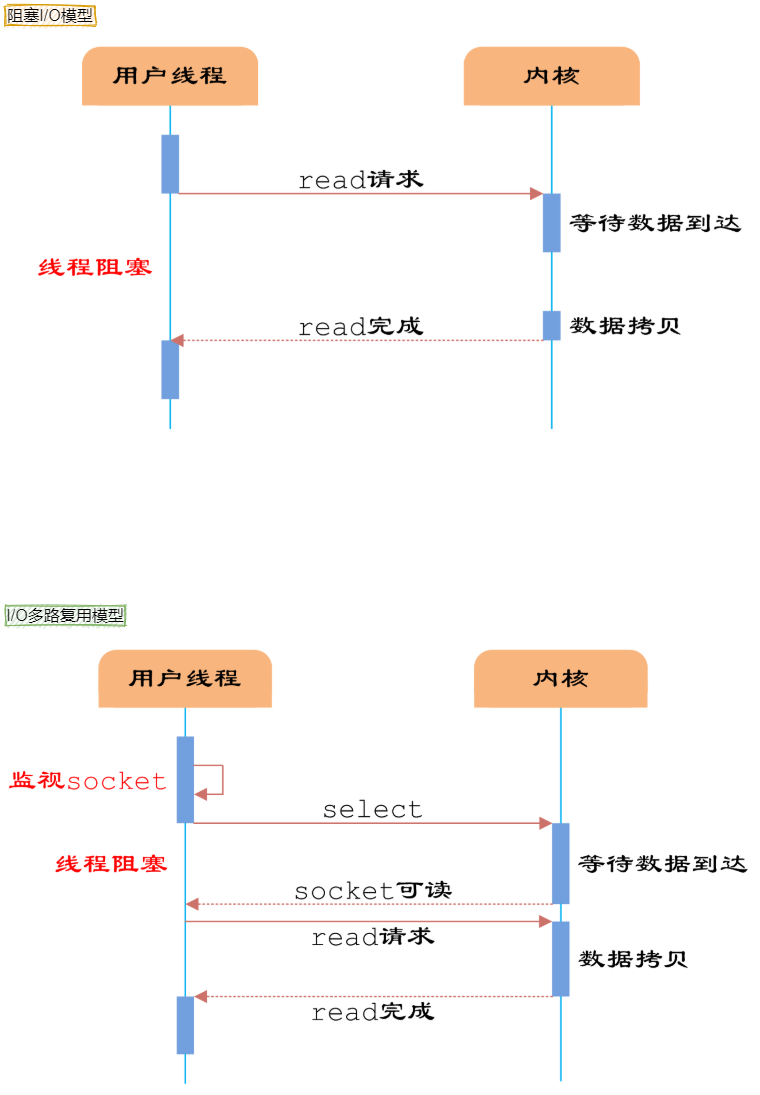
第一种就是阻塞IO模型,第三种就是I/O复用模型,Linux下的select、poll和epoll就是干这个的。将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。
这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。
第三:单线程避免了线程切换和竞态产生的消耗。
我们继续来看Redis单线程却很快的最后一条原因,在多线程开发中,存在线程的切换和竞争,这样一来,是有时间的消耗的。对于需要磁盘I/O的程序来讲,磁盘I/O是一个比较耗时的操作,所以对于需要进行磁盘I/O的程序,我们可以使用多线程,在某个线程进行I/O时,CPU切换到当前程序的其他线程执行,以此减少CPU的等待时间。
那么问题来了。Redis的数据存放在内存中,将内存中的数据读入CPU时,CPU不是依然需要等待吗,为什么不能在等待数据从内存读入CPU期间执行其他线程,以此提高CPU的使用率呢?这个问题的答案很简单,内存的读些速度虽然比CPU慢很多,但是也是非常快的。CPU切换线程需要花费一定的时间,而多次切换线程所花费的时间,可能比直接使用单线程执行相同的任务,花费的时间要更多,这是非常不划算的。