反向映射,或者说是 RMAP,就是为解决此问题而在 2.5 内核中实现的。反向映射提供了一个发现哪些进程正在使用给定的内存物理页的机制。不再是遍历每个进程的页表,内存管理器现在为每一个物理页建立了一个链表,包含了指向当前映射那个页的每一个进程的页表条目(page-table entries, PTE)的指针。这个链表叫做 PTE 链 。PTE 链极大地提高了找到那些映射某个页的进程的速度,如图 1 所示
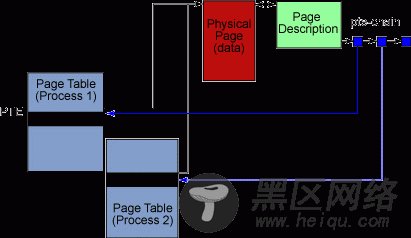
当然,没有什么是免费的:用反向映射获得性能提高也要付出代价。反向映射最重要、明显的代价是,它带来了一些内存开销。不得不用一些内存来保持对所有那些反向映射的追踪。PTE 链的每一个条目使用 4 个字节来存储指向页表条目的指针,用另外 4 个字节来存储指向链的下一个条目的指针。这些内存必须使用低端内存,而这在 32 位硬件上有点不够用。有时这可以优化到只使用一个条目而不使用链表。这种方法叫做 p页直接方法(page-direct approach)。如果只有一个到这个页的映射,那么可以用一个叫做“direct”的指针来代替链表。只有在某个页只是由一个惟一的进程映射时才可以进行这种优化。如果稍后这个页被另一个进程所映射,它将不得不再去使用 PTE 链。一个标记设置用来告诉内存管理器什么时候这种优化对一个给定的页有效。