
Conv layers包含了conv,pooling,relu三种层。以python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构为例,如图2,Conv layers部分共有13个conv层,13个relu层,4个pooling层。这里有一个非常容易被忽略但是又无比重要的信息,在Conv layers中:
所有的conv层都是:kernel_size=3,pad=1
所有的pooling层都是:kernel_size=2,stride=2
为何重要?在Faster RCNN Conv layers中对所有的卷积都做了扩边处理(pad=1,即填充一圈0),导致原图变为(M+2)x(N+2)大小,再做3x3卷积后输出MxN。正是这种设置,导致Conv layers中的conv层不改变输入和输出矩阵大小。如图3:
图3
类似的是,Conv layers中的pooling层kernel_size=2,stride=2。这样每个经过pooling层的MxN矩阵,都会变为(M/2)*(N/2)大小。综上所述,在整个Conv layers中,conv和relu层不改变输入输出大小,只有pooling层使输出长宽都变为输入的1/2。
那么,一个MxN大小的矩阵经过Conv layers固定变为(M/16)x(N/16)!这样Conv layers生成的feature map中都可以和原图对应起来。
2 Region Proposal Networks(RPN)经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如R-CNN使用SS(Selective Search)方法生成检测框。而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。
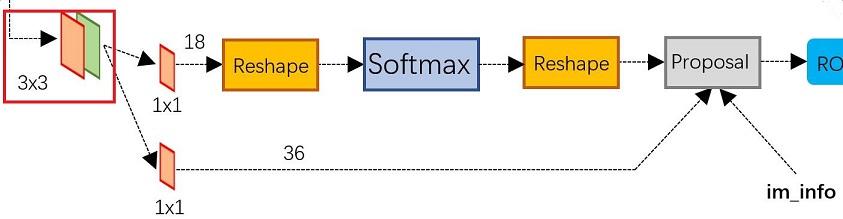
上图4展示了RPN网络的具体结构。可以看到RPN网络实际分为2条线,
上面一条通过softmax分类anchors获得foreground和background(检测目标是foreground)分类!
下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。回归!
而最后的Proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
2.1 多通道图像卷积基础知识介绍在介绍RPN前,还要多解释几句基础知识
对于单通道图像+单卷积核做卷积,第一章中的图3已经展示了;
对于多通道图像+多卷积核做卷积,计算方式如下:
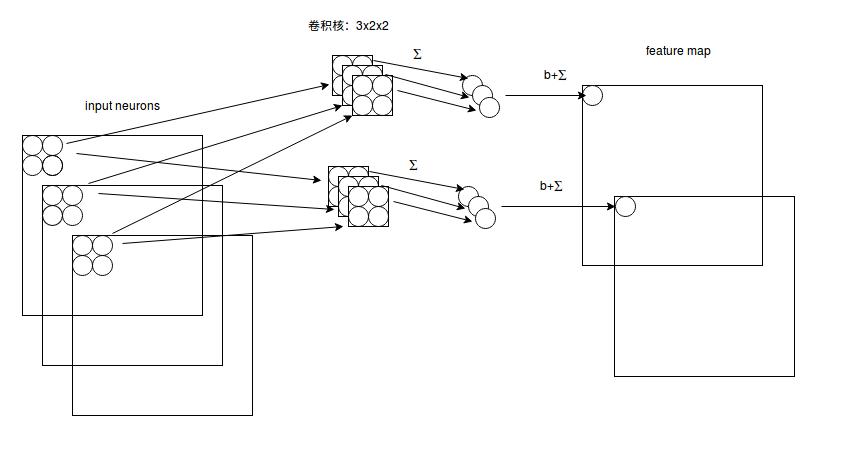
如图5,输入有3个通道,同时有2个卷积核。对于每个卷积核,先在输入3个通道分别作卷积,再将3个通道结果加起来得到卷积输出。
所以对于某个卷积层,无论输入图像有多少个通道,输出图像通道数总是等于卷积核数量!
对多通道图像做1x1卷积,其实就是将输入图像于每个通道乘以卷积系数后加在一起,即相当于把原图像中本来各个独立的通道“联通”在了一起
提到RPN网络,就不能不说anchors。所谓anchors,实际上就是一组由rpn/generate_anchors.py生成的矩形。
直接运行作者demo中的generate_anchors.py可以得到以下输出:
[[ -84. -40. 99. 55.] [-176. -88. 191. 103.] [-360. -184. 375. 199.] [ -56. -56. 71. 71.] [-120. -120. 135. 135.] [-248. -248. 263. 263.] [ -36. -80. 51. 95.] [ -80. -168. 95. 183.] [-168. -344. 183. 359.]]