

如上图,常用的有三种表达方式,点积,预选相似度(归一化卷积),MLP网络(神经网络)。
Self Attention模型
通过上述对Attention本质思想的梳理,我们可以更容易理解本节介绍的Self Attention模型。Self Attention也经常被称为intra Attention(内部Attention),最近一年也获得了比较广泛的使用,比如Google最新的机器翻译模型内部大量采用了Self Attention模型。
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已,所以此处不再赘述其计算过程细节。
如果是常规的Target不等于Source情形下的注意力计算,其物理含义正如上文所讲,比如对于机器翻译来说,本质上是目标语单词和源语单词之间的一种单词对齐机制。那么如果是Self Attention机制,一个很自然的问题是:通过Self Attention到底学到了哪些规律或者抽取出了哪些特征呢?或者说引入Self Attention有什么增益或者好处呢?我们仍然以机器翻译中的Self Attention来说明,图11和图12是可视化地表示Self Attention在同一个英语句子内单词间产生的联系。
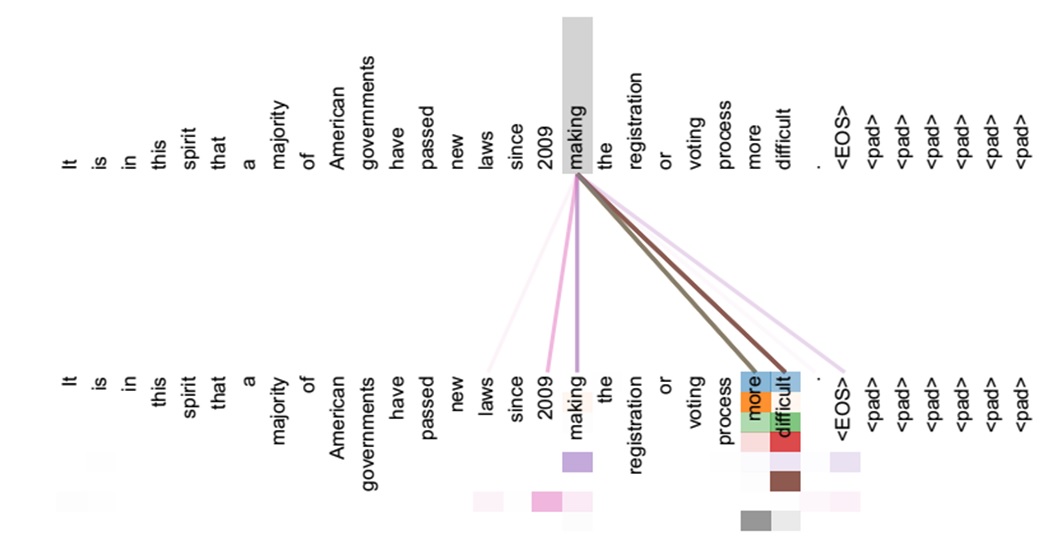
图11 可视化Self Attention实例