
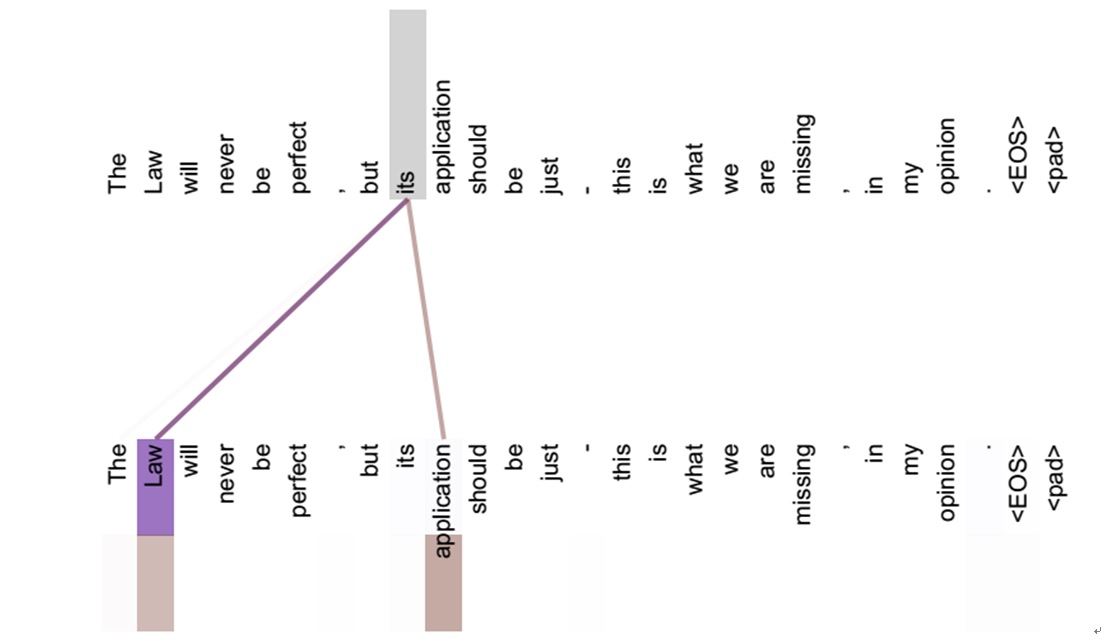
图12 可视化Self Attention实例
从两张图(图11、图12)可以看出,Self Attention可以捕获同一个句子中单词之间的一些句法特征(比如图11展示的有一定距离的短语结构)或者语义特征(比如图12展示的its的指代对象Law)。
很明显,引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。
Self Attention其实就是把让Value充当Query,用来表示某个单词自身与此句子其他单词的关联权重。作用可以增强句子中长距离的依赖关系(这就解决了RNN的通病,长时间依赖问题)。
Attention机制的应用
前文有述,Attention机制在深度学习的各种应用领域都有广泛的使用场景。上文在介绍过程中我们主要以自然语言处理中的机器翻译任务作为例子,下面分别再从图像处理领域和语音识别选择典型应用实例来对其应用做简单说明。
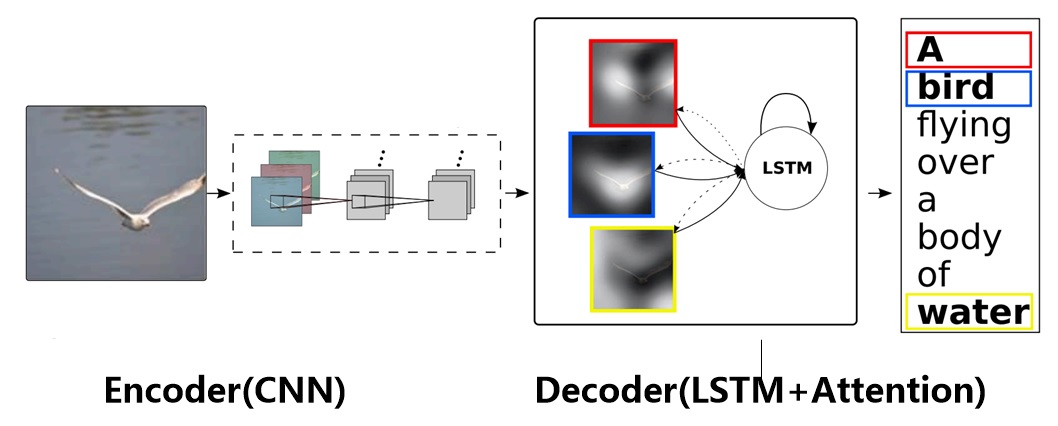
图13 图片-描述任务的Encoder-Decoder框架
图片描述(Image-Caption)是一种典型的图文结合的深度学习应用,输入一张图片,人工智能系统输出一句描述句子,语义等价地描述图片所示内容。很明显这种应用场景也可以使用Encoder-Decoder框架来解决任务目标,此时Encoder输入部分是一张图片,一般会用CNN来对图片进行特征抽取,Decoder部分使用RNN或者LSTM来输出自然语言句子(参考图13)。
此时如果加入Attention机制能够明显改善系统输出效果,Attention模型在这里起到了类似人类视觉选择性注意的机制,在输出某个实体单词的时候会将注意力焦点聚焦在图片中相应的区域上。图14给出了根据给定图片生成句子“A person is standing on a beach with a surfboard.”过程时每个单词对应图片中的注意力聚焦区域。