
4..权重如何优化,只要把权重表示好,使得网络可以通过前向传播,使用Encoder-Decoder框架的loss就可以把权重与其他网络参数优化好。
5.Attention机制的本质思想
如果把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。
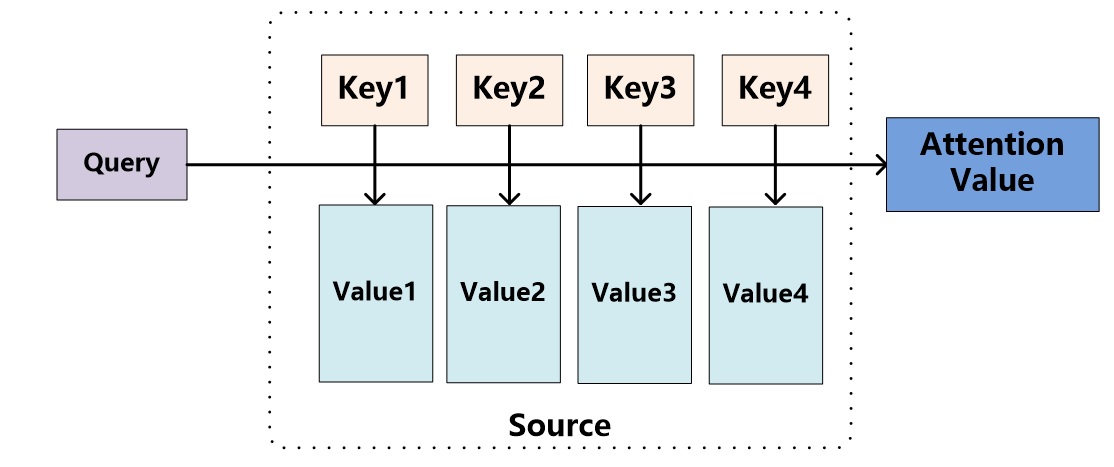
图9 Attention机制的本质思想
我们可以这样来看待Attention机制(参考图9):将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
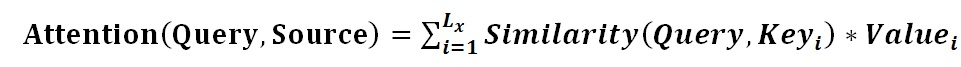
其中,
