
https://github.com/PhantomThief/more-lambdas-java
如果你想把它用起来,得引入下面这个 maven 地址:
<dependency><groupId>com.github.phantomthief</groupId>
<artifactId>more-lambdas</artifactId>
<version>0.1.55</version>
</dependency>
其核心代码是这个接口:
com.github.phantomthief.pool.KeyAffinityExecutor
这个接口里面有大量的注释,大家可以拉下来看一下。
我这里主要给大家看一下接口上面,作者写的注释,他是这样介绍自己的这个工具的。
这是一个按指定的 Key 亲和顺序消费的线程池。
KeyAffinityExecutor 是一个特殊的任务线程池。
它可以确保投递进来的任务按 Key 相同的任务依照提交顺序依次执行。在既要通过并行处理来提高吞吐量、又要保证一定范围内的任务按照严格的先后顺序来运行的场景下非常适用。
KeyAffinityExecutor 的内建实现方式,是将指定的 Key 映射到固定的单线程线程池上,它内部会维护多个(数量可配)这样的单线程线程池,来保持一定的任务并行度。
需要注意的是,此接口定义的 KeyAffinityExecutor,并不要求 Key 相同的任务在相同的线程上运行,尽管实现类可以按照这种方式来实现,但它并非一个强制性的要求,因此在使用时也请不要依赖这样的假定。
很多人问,这和自己使用一个线程池的数组,并通过简单取模的方式来实现有什么区别?
事实上,大多数场景的确差异不大,但是当数据倾斜发生时,被散列到相同位置的数据可能会因为热点倾斜数据被延误。
本实现在并发度较低时(阈值可设置),会挑选最闲置的线程池投递,尽最大可能隔离倾斜数据,减少对其它数据带来的影响。
在作者的这段介绍里面,简单的说明了该项目的应用场景和内部原理,和我们前面分析的差不多。
除此之外,还有两个需要特别注意的地方。
第一个地方是这里:
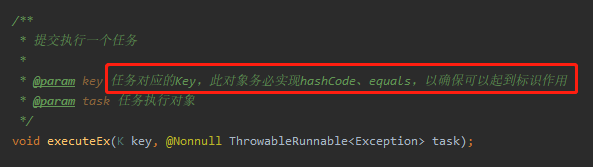
作为区分的任务维度的对象,如果是自定义对象,那么一定要重写其 hashCode、equals,以确保可以起到标识作用。
这一处的提醒就和 HashMap 的 key 如果是对象的话,应该要重写 hashCode、equals 方法的原因是一样一样的。
编程基础,只提一下,不多赘述。
第二个地方得好好说一下,属于他的核心思想。
他没有采用简单取模的方式,因为在简单取模的场景上,数据是有可能发生倾斜的。
我个人是这样理解作者的思路的。
首先说明一下取模的数据倾斜是咋回事,举个简单的例子:
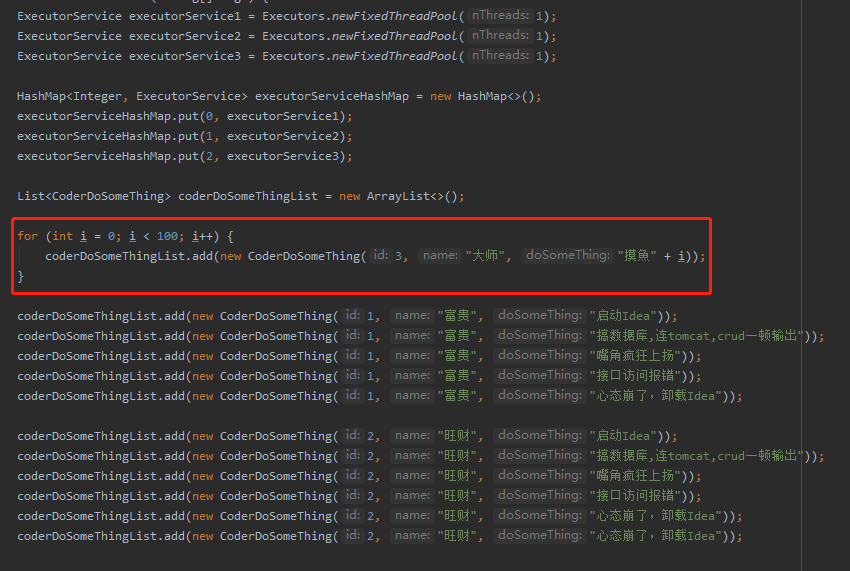
上面的代码片段中,我加入了一个新角色“摸鱼大师”。同时给对象新增了一个 id 字段。
假设,我们对 id 字段用 2 取余:

那么会出现的情况就是大师和富贵对应的 id 取余结果都是 1,它们将同用一个线程池。
很明显,由于大师的频繁操作,导致“摸鱼”变成了热点数据,从而导致编号为 0 的连接池发了倾斜,进而影响到了富贵的正常工作。
而 KeyAffinityExecutor 的策略是什么样的呢?
它会挑选最闲置的线程池进行投递。
怎么理解呢?
还是上面的例子,如果我们构建这样的线程池:
KeyAffinityExecutor executorService =KeyAffinityExecutor.newSerializingExecutor(3, 200, "MY-POOL-%d");
第一个参数 3,代表它会在这里线程池里面构建 3 个只有一个线程的线程池。
那么当用它来提交任务的时候,由于维度是 id 维度,我们刚好三个 id,所以刚好把这个线程池占满:

这个时候是不存在数据倾斜的。
但是,如果我把前面构建线程池的参数从 3 变成 2 呢?
KeyAffinityExecutor executorService =KeyAffinityExecutor.newSerializingExecutor(2, 200, "MY-POOL-%d");
提交方式不变,里面加上对 id 为 1 和 2 的任务延迟的逻辑,目的是观察 id 为 3 的数据怎么处理:
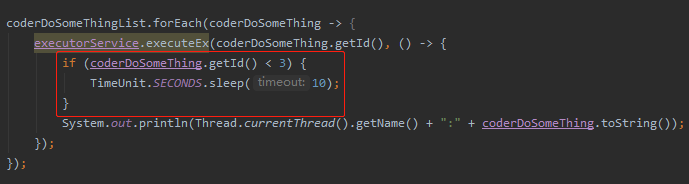
毋庸置疑,当提交执行大师的摸鱼操作的时候线程池肯定不够用了,怎么办?
这个时候,根据作者描述“会挑选最闲置的线程池投递”。
我用这样的数据来说明:
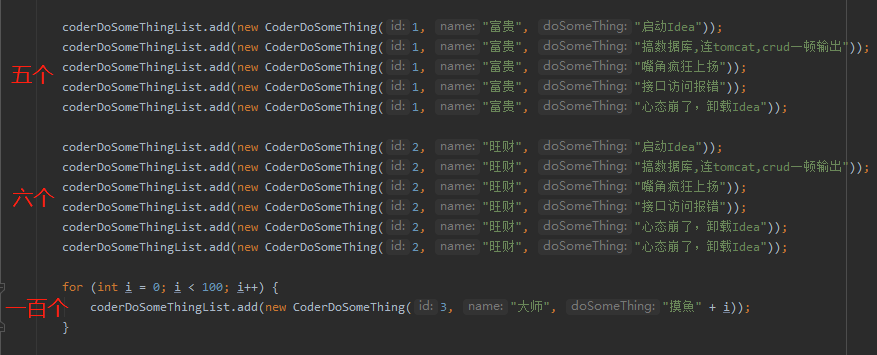
所以,当执行大师摸鱼操作的时候,会去从仅有的两个选项中选一个出来。
怎么选?
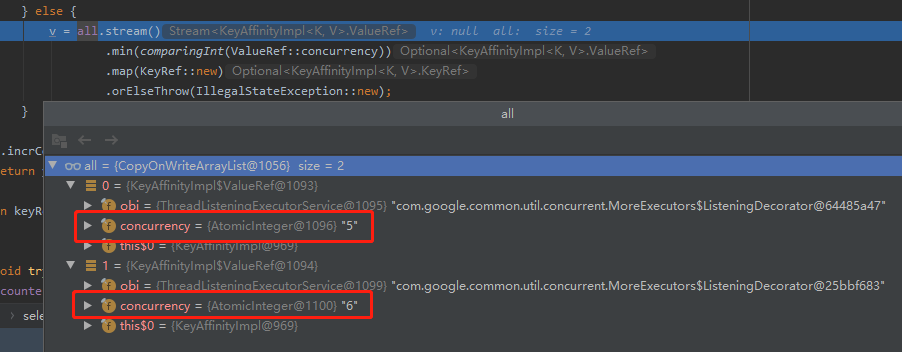
谁的并发度低,就选谁。
由于有延迟时间在任务里面,所以我们可以观察到执行富贵的线程的并发度是 5,而执行旺财的线程的并发度是 6。
因此执行大师的摸鱼操作的时候,会选择并发度为 5 的线程进行处理。
这个场景下就出现了数据倾斜。但是倾斜的前提发生了变化,变成了当前已经没有可用线程了。
所以,作者说“尽最大可能隔离倾斜数据”。
这两个方案最大的差异就是对线程资源的利用程度,如果是单纯的取模,那么有可能出现发生数据倾斜的时候,还有可用线程。
如果是 KeyAffinityExecutor 的方式,它可以保证发生数据倾斜的时候,线程池里面的线程一定是已经用完了。
然后,你再品一品这两个方案之间的细微差异。
KeyAffinityExecutor源码源码不算多,一共就这几个类:
但是他的源码里面绝大部分都是 lambdas 的写法,基本上都是函数式编程,如果你对这方面比较薄弱的话那么看起来会比较吃力一点。
如果你想掌握其源码的话,我建议是把项目拉到本地,然后从他的测试用例入手: