
对于从事java开发工作的小伙伴来说,spring框架肯定再熟悉不过了。spring给开发者提供了非常丰富的api,满足我们日常的工作需求。
如果想要创建bean实例,可以使用@Controller、@Service、@Repository、@Component等注解。
如果想要依赖注入某个对象,可以使用@Autowired和@Resource注解。
如果想要开启事务,可以使用@Transactional注解。
如果想要动态读取配置文件中的某个系统属性,可以使用@Value注解。
等等,还有很多。。。
前面几种常用的注解,在我以往的文章中已经介绍过了,在这里就不过多讲解了。
今天咱们重点聊聊@Value注解,因为它是一个非常有用,但极其容易被忽视的注解,绝大多数人可能只用过它的一部分功能,这是一件非常遗憾的事情。
所以今天有必要和大家一起,重新认识一下@Value。
假如在UserService类中,需要注入系统属性到userName变量中。通常情况下,我们会写出如下的代码:
@Service public class UserService { @Value("${susan.test.userName}") private String userName; public String test() { System.out.println(userName); return userName; } }通过@Value注解指定系统属性的名称susan.test.userName,该名称需要使用${}包起来。
这样spring就会自动的帮我们把对应的系统属性值,注入到userName变量中。
不过,上面功能的重点是要在applicationContext.properties文件(简称:配置文件)中配置同名的系统属性:
#张三 susan.test.userName=\u5f20\u4e09那么,名称真的必须完全相同吗?
2. 关于属性名这时候,有些朋友可能会说:
在@ConfigurationProperties配置类中,定义的参数名可以跟配置文件中的系统属性名不同。
比如,在配置类MyConfig类中定义的参数名是userName:
@Configuration @ConfigurationProperties(prefix = "susan.test") @Data public class MyConfig { private String userName; }而配置文件中配置的系统属性名是:
susan.test.user-name=\u5f20\u4e09类中用的userName,而配置文件中用的user-name,不一样。但测试之后,发现该功能能够正常运行。
配置文件中的系统属性名用 驼峰标识 或 小写字母加中划线的组合,spring都能找到配置类中的属性名userName进行赋值。
由此可见,配置文件中的系统属性名,可以跟配置类中的属性名不一样。不过,有个前提,前缀susan.test必须相同。
那么,@Value注解中定义的系统属性名也可以不一样吗?
答案:不能。如果不一样,启动项目时会直接报错。
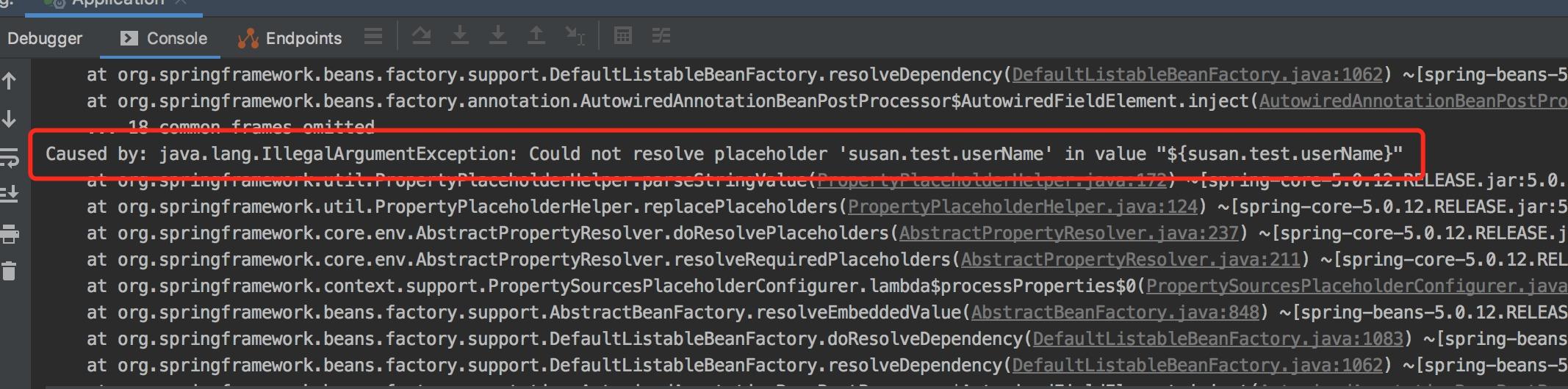
此外,如果只在@Value注解中指定了系统属性名,但实际在配置文件中没有配置它,也会报跟上面一样的错。
所以,@Value注解中指定的系统属性名,必须跟配置文件中的相同。
3. 乱码问题不知道细心的小伙伴们有没有发现,我配置的属性值:张三,其实是转义过的。
susan.test.userName=\u5f20\u4e09为什么要做这个转义?
假如在配置文件中配置中文的张三:
susan.test.userName=张三最后获取数据时,你会发现userName竟然出现了乱码:
å¼ ä¸
what?
为什么会出现乱码?
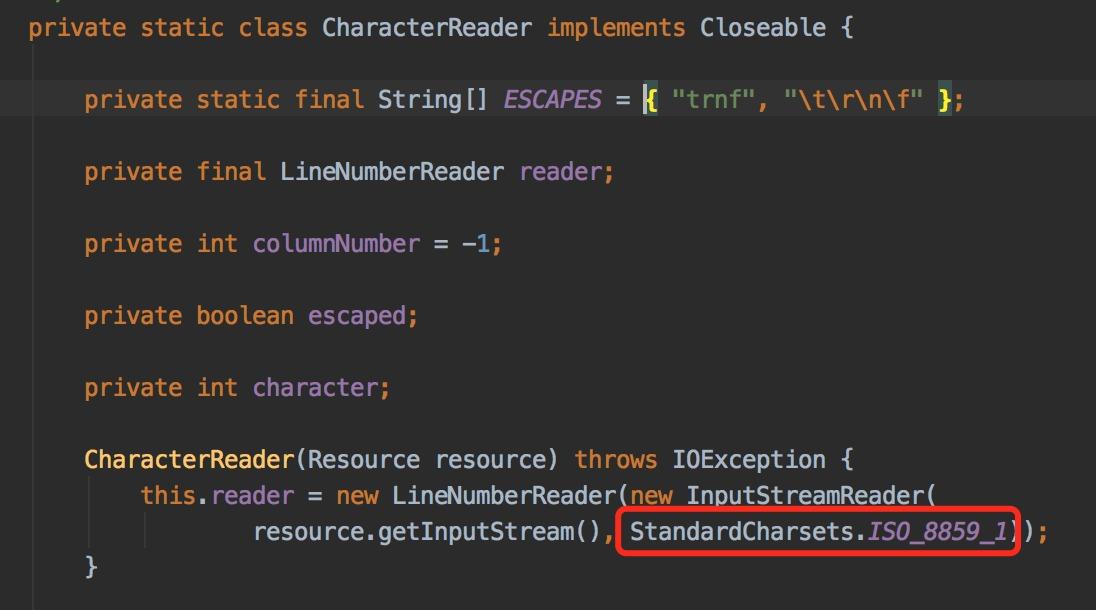
答:在springboot的CharacterReader类中,默认的编码格式是ISO-8859-1,该类负责.properties文件中系统属性的读取。如果系统属性包含中文字符,就会出现乱码。
那么,如何解决乱码问题呢?
目前主要有如下三种方案:
手动将ISO-8859-1格式的属性值,转换成UTF-8格式。
设置encoding参数,不过这个只对@PropertySource注解有用。
将中文字符用unicode编码转义。
显然@Value不支持encoding参数,所以方案2不行。
假如使用方案1,具体实现代码如下:
@Service public class UserService { @Value(value = "${susan.test.userName}") private String userName; public String test() { String userName1 = new String(userName.getBytes(StandardCharsets.ISO_8859_1), StandardCharsets.UTF_8); System.out.println(); return userName1; } }确实可以解决乱码问题。
但如果项目中包含大量中文系统属性值,每次都需要加这样一段特殊转换代码。出现大量重复代码,有没有觉得有点恶心?
反转我被恶心到了。
那么,如何解决代码重复问题呢?
答:将属性值的中文内容转换成unicode。
类似于这样的:
susan.test.userName=\u5f20\u4e09这种方式同样能解决乱码问题,不会出现恶心的重复代码。但需要做一点额外的转换工作,不过这个转换非常容易,因为有现成的在线转换工具。
推荐使用这个工具转换:
在这里顺便告诉你一个小秘密:如果你使用的是.yml或.yaml格式的配置文件,并不会出现中文乱码问题。
这又是为什么?