
相对于普通读写来说,volatile读写具有更高的成本,因为它需要保证可见性和有序性。在执行get操作时,会强制从主存中获取属性值,在使用put方法设置属性值时,会强制将值更新到主存中,从而保证这些变更对其他线程是可见的。
有序写入的方法有以下三个:
public native void putOrderedObject(Object o, long offset, Object x); public native void putOrderedInt(Object o, long offset, int x); public native void putOrderedLong(Object o, long offset, long x);有序写入的成本相对volatile较低,因为它只保证写入时的有序性,而不保证可见性,也就是一个线程写入的值不能保证其他线程立即可见。为了解决这里的差异性,需要对内存屏障的知识点再进一步进行补充,首先需要了解两个指令的概念:
Load:将主内存中的数据拷贝到处理器的缓存中
Store:将处理器缓存的数据刷新到主内存中
顺序写入与volatile写入的差别在于,在顺序写时加入的内存屏障类型为StoreStore类型,而在volatile写入时加入的内存屏障是StoreLoad类型,如下图所示:

在有序写入方法中,使用的是StoreStore屏障,该屏障确保Store1立刻刷新数据到内存,这一操作先于Store2以及后续的存储指令操作。而在volatile写入中,使用的是StoreLoad屏障,该屏障确保Store1立刻刷新数据到内存,这一操作先于Load2及后续的装载指令,并且,StoreLoad屏障会使该屏障之前的所有内存访问指令,包括存储指令和访问指令全部完成之后,才执行该屏障之后的内存访问指令。
综上所述,在上面的三类写入方法中,在写入效率方面,按照put、putOrder、putVolatile的顺序效率逐渐降低,
b、使用Unsafe的allocateInstance方法,允许我们使用非常规的方式进行对象的实例化,首先定义一个实体类,并且在构造函数中对其成员变量进行赋值操作:
@Data public class A { private int b; public A(){ this.b =1; } }分别基于构造函数、反射以及Unsafe方法的不同方式创建对象进行比较:
public void objTest() throws Exception{ A a1=new A(); System.out.println(a1.getB()); A a2 = A.class.newInstance(); System.out.println(a2.getB()); A a3= (A) unsafe.allocateInstance(A.class); System.out.println(a3.getB()); }打印结果分别为1、1、0,说明通过allocateInstance方法创建对象过程中,不会调用类的构造方法。使用这种方式创建对象时,只用到了Class对象,所以说如果想要跳过对象的初始化阶段或者跳过构造器的安全检查,就可以使用这种方法。在上面的例子中,如果将A类的构造函数改为private类型,将无法通过构造函数和反射创建对象,但allocateInstance方法仍然有效。
4、数组操作在Unsafe中,可以使用arrayBaseOffset方法可以获取数组中第一个元素的偏移地址,使用arrayIndexScale方法可以获取数组中元素间的偏移地址增量。使用下面的代码进行测试:
private void arrayTest() { String[] array=new String[]{"str1str1str","str2","str3"}; int baseOffset = unsafe.arrayBaseOffset(String[].class); System.out.println(baseOffset); int scale = unsafe.arrayIndexScale(String[].class); System.out.println(scale); for (int i = 0; i < array.length; i++) { int offset=baseOffset+scale*i; System.out.println(offset+" : "+unsafe.getObject(array,offset)); } }上面代码的输出结果为:
16 4 16 : str1str1str 20 : str2 24 : str3通过配合使用数组偏移首地址和各元素间偏移地址的增量,可以方便的定位到数组中的元素在内存中的位置,进而通过getObject方法直接获取任意位置的数组元素。需要说明的是,arrayIndexScale获取的并不是数组中元素占用的大小,而是地址的增量,按照openJDK中的注释,可以将它翻译为元素寻址的转换因子(scale factor for addressing elements)。在上面的例子中,第一个字符串长度为11字节,但其地址增量仍然为4字节。
那么,基于这两个值是如何实现的寻址和数组元素的访问呢,这里需要借助一点在前面的文章中讲过的Java对象内存布局的知识,先把上面例子中的String数组对象的内存布局画出来,就很方便大家理解了:
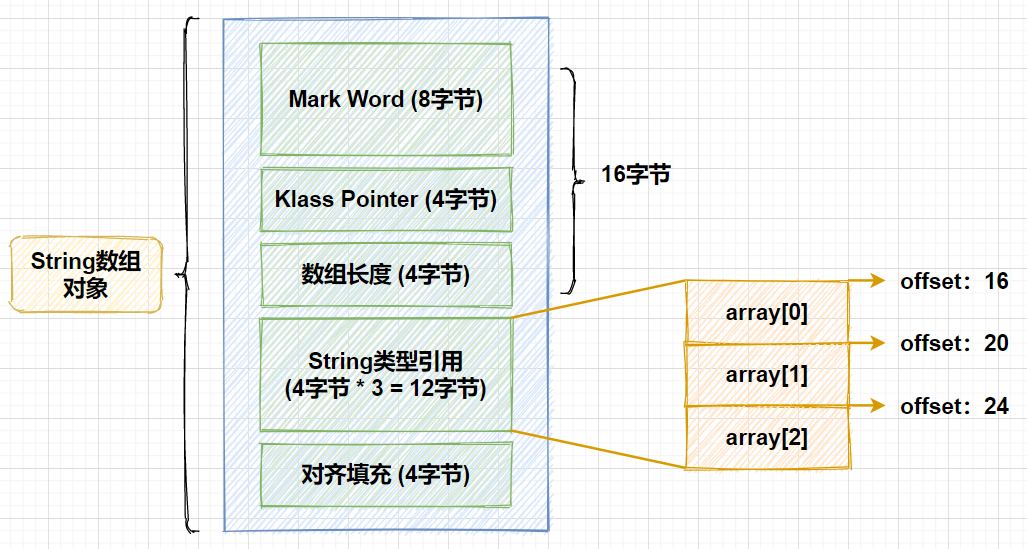
在String数组对象中,对象头包含3部分,mark word标记字占用8字节,klass point类型指针占用4字节,数组对象特有的数组长度部分占用4字节,总共占用了16字节。第一个String的引用类型相对于对象的首地址的偏移量是就16,之后每个元素在这个基础上加4,正好对应了我们上面代码中的寻址过程,之后再使用前面说过的getObject方法,通过数组对象可以获得对象在堆中的首地址,再配合对象中变量的偏移量,就能获得每一个变量的引用。
5、CAS操作