DARTS将每对node之间的每一个operation都赋予一个weight,最优解可以用softmax求得,也就是说有最大probability的path代表最优operation,这也是DARTS的核心部分。DARTS在搜索空间中定义了两种cell,reduction cell和normal cell。宏观网络结构是固定的,作者采用了简单的chained-structured,将reduction cell放在了网络结构的1/3和2/3处。所以说在搜索的过程中,cell内部不断更新而宏观结构没有变化。我们定义operation的参数为W,将cell中operation的weight记为Alpha。根据论文和source code,我们总结了DARTS的搜索流程如下图。
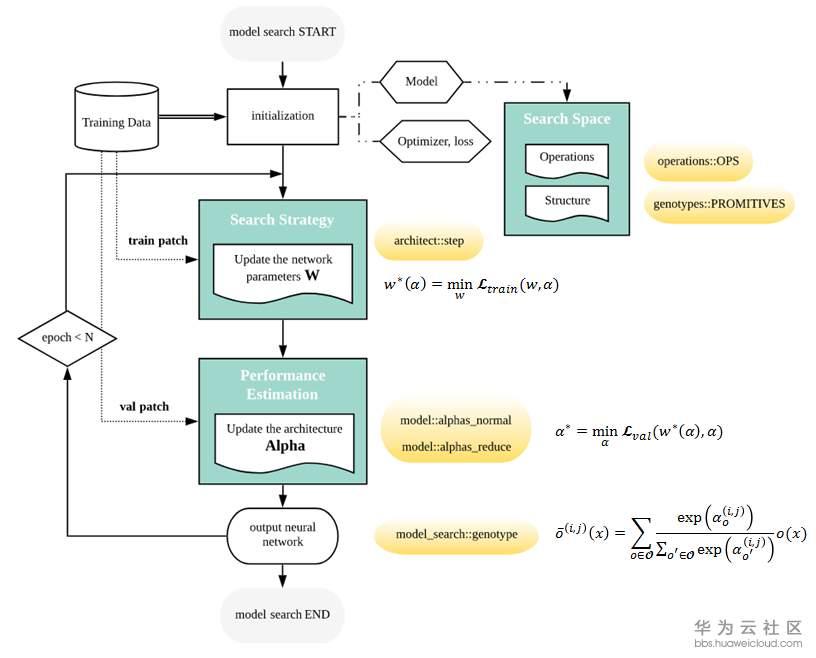
网络搜索的第一步是对模型结构,optimizer,loss进行初始化。文中定义了几种operation,代码中的定义在operation.OPS, 两种cell在代码中的定义是genotypes.PROMITIVES. 参数Alpha在代码中定义为arch_parameters()={alphas.normal, alphas.reduce}. 在搜索过程中,train data被分成两部分,train patch用来训练网络参数W而validation patch用来评估搜索到的网络结构。在代码中,搜索过程的核心部分在architect.step()。网络搜索的目标函数就是让validation在现有网络的loss最小,文章中公式(3)给出了objective:
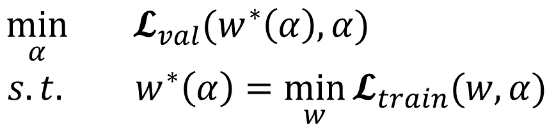
为了减少搜索时间,每一轮只用一个training patch去更新参数W计算train loss。在计算Alpha的时候涉及到二阶求导,稍微复杂一点,但是论文和代码都给了详细解释,这里不赘述,代码中architect._hession_vector_product是求二阶导的实现。在更新W和Alpha之后,最优operation通过softmax来计算。文中保留了top-k probability的operation。W和Alpha不断计算更新直到搜索过程结束。
文中进行了大量实验,我们这里只介绍一下在CIFAR-10数据上面进行的图像分类任务。作者将DARTS与传统人工设计的网络DenseNet,和几个其他常见的NAS网络进行对比,如AmoeNet和ENet都是常被提及的。DARTS在准确度上优于其他所有算法,并且在搜索速度上明显比RL快很多。由于结构简单效果好,而且不需要大量GPU和搜索时间,DARTS已经被大量引用。
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation基于DARTS的结构,Google DeepLab团队提出了Auto-DeepLab并发表在2019年CVPR上。在tensorflow deeplab官网上公布了nas backbone并且给出了可以训练的模型结构,但是搜索过程并没有公开。于是我们训练了给出的nas网络结构,在没有任何pre-training的情况下与deeplab v3+进行对比。代码参考 https://github.com/tensorflow/models/tree/master/research/deeplab 。
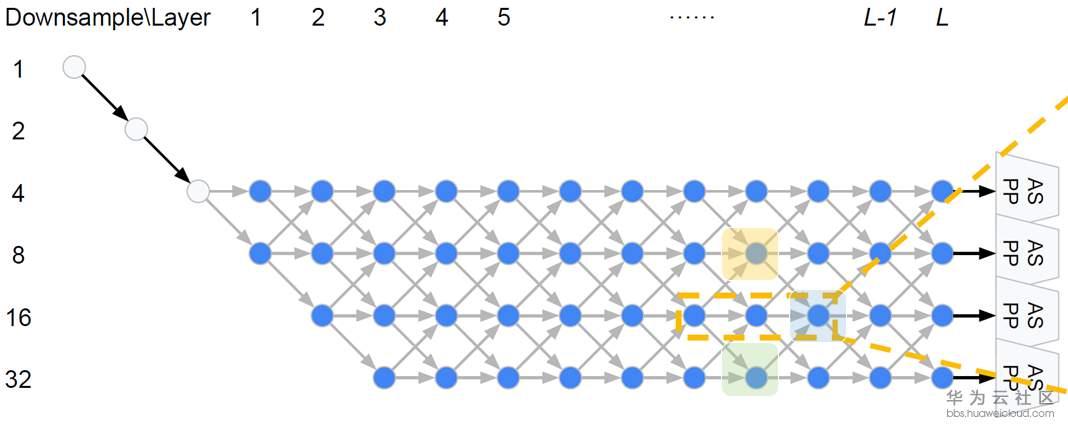
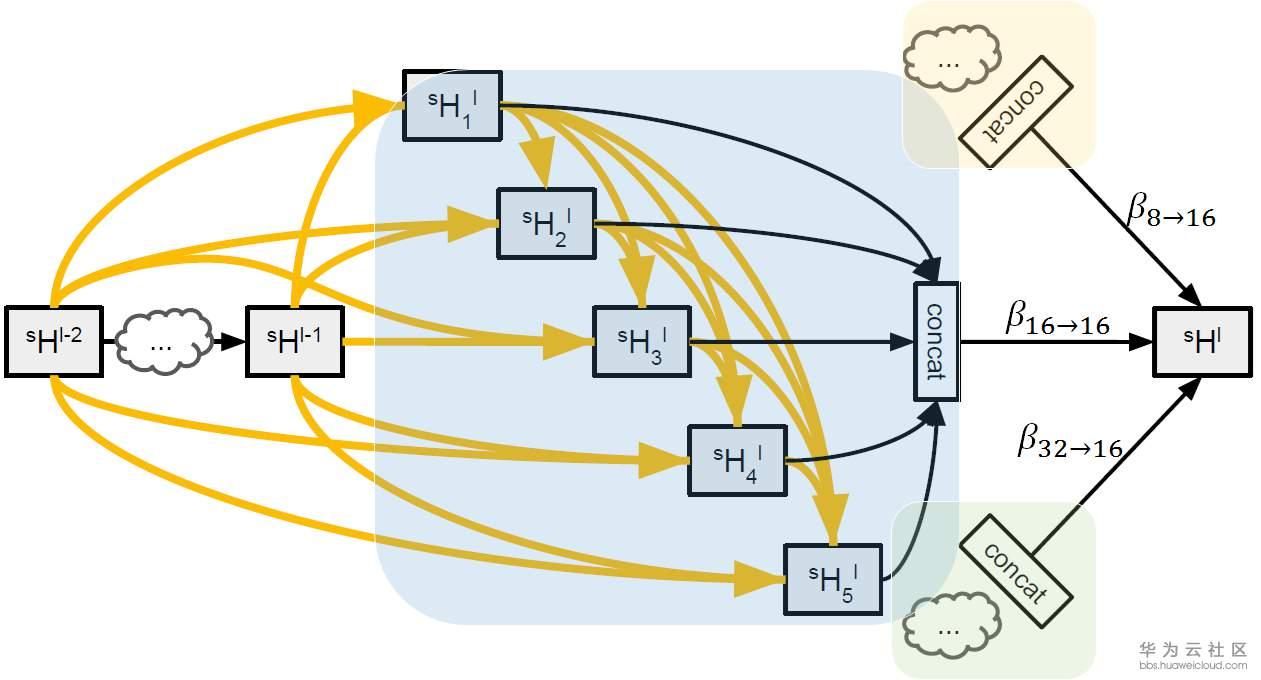
在DARTS中,宏观网络结构是提前定义的,而在Auto-DeepLab中宏观网络结构也是搜索的一部分。继承自DeepLab v3+的encoder-decoder结构,Auto-DeepLab的目的是搜索Encoder代替现有的xception65,MobileNet等backbone,decoder采用ASPP。在搜索空间中定义了reduction cell,normal cell和一些operation。Reduction cell用来改变spatial resolution,使其变大两倍,或不变,或变小两倍。为了保证feature map的精度,Auto-DeepLab规定最多downsampling 32倍 (s=32)。下图定义了宏观网络结构(左)和cell内部的结构(右)。