
Auto-DeepLab定义了12个cell,而上图(左)中前面两个白色的node是固定的两层为了缩小spatial resolution。如图左灰色箭头所示,正式搜索之后,每一个cell的位置都有多种cell类型可以选择:可以来自于当前cell相同的spatial resolution的cell,也可以是比当前cell的spatial resolution大一倍或小一倍的cell。作者将这些空间路径(灰色箭头表示的路径)也赋予一个weight,记作Beta。如图右,每一个cell的输出都是由相邻spatial resolution的cell结合而成,而Beta的值可以理解成不同路径的probability。为了更直观,我们把图右的三个cell分别用蓝色,黄色和绿色标注,对应图左的三个cell。与DARTS类似,我们将operation的parameters记作W,将cell内部operation的权重记作Alpha。所以搜索最优网络结构,即迭代计算并更新W,Alpha和Beta。文中给出每一个cell的实际输出为:
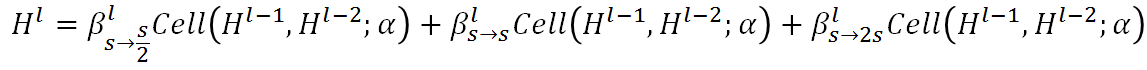
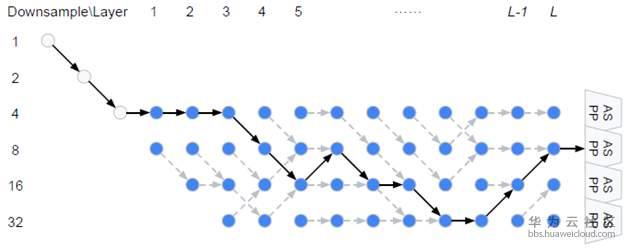
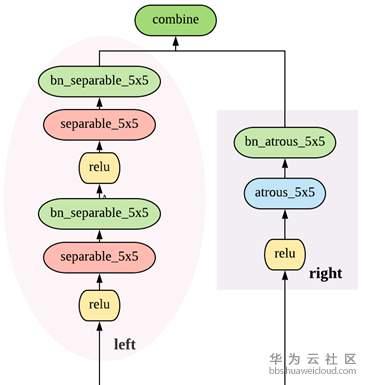
从上面公式可以看出,W和{Alpha,Beta}要分别计算和更新。所有的weight都是非负数。Alpha的计算方式依然是ArgMax,而计算Beta用了经典的贪心算法Viterbi算法。下图给出的宏观网络结构是基于Cityscapes搜索到的结果,对应代码中的backbone是[0,0,0,1,2,1,2,2,3,3,2,1], 数字代表downsample倍数。在模型中,每一个cell中的node由两个路径组成,如图右。
文中用了三组开源数据PASCAL VOC 12, Cityscapes和ADE20k做了对比实验。具体实验参数设置和对比算法在论文中有详细说明,这里只对比和Deeplab v3+。Cityscapes训练数据尺寸是[769x769],而PASCAL VOC 12和ADE20k训练数据尺寸是[513x513]。一般来说,Auto-DeepLab和DeepLabv3+准确度相差无几,但是速度上要快2.33倍,并且Auto-DeepLab可以从零开始训练。

除了文中给出的实验结果以外,我们在PASCAL VOC 12数据上从零开始训练了Auto-DeepLab,用代码中给出的模型结构,并且与DeepLabv3+(xception65)进行结果对比。但是并不是所有结果都能复现,分析原因大概是这样:首先,上文中给出的模型结构是用Cityscapes数据集搜索得到,也许在PASCAL VOC 12上并不是最优解;其次没有用ImageNet做pre-training,训练环境也不同。我们在下面表格中对比了FLOPs, 参数数量, 在K80 GPU上面的fps和mIoU。

下图中直观对比了ground truth(第二列),deeplabv3+(第三列)和Auto-DeepLab-S(第四列)的分割结果。与上面的mIoU一致,DeepLabv3+的分割结果要比Auto-DeepLab更精准一些,尤其是在边缘。对于简单的图像案例,两者分割结果相差无几,但是在较难的情况下,Auto-DeepLab会有很大误差(在第三个案例中,Auto-DeepLab将女孩识别成狗)。