
正则作为处理字符串的一个实用工具,在Python中经常会用到,比如爬虫爬取数据时常用正则来检索字符串等等。正则表达式已经内嵌在Python中,通过导入re模块就可以使用,作为刚学Python的新手大多数都听说”正则“这个术语。
今天来给大家分享一份关于比较详细的Python正则表达式宝典,学会之后你将对正则表达式达到精通的状态。

在讲正则表达式之前,我们首先得知道哪里用得到正则表达式。正则表达式是用在findall()方法当中,大多数的字符串检索都可以通过findall()来完成。
1.导入re模块在使用正则表达式之前,需要导入re模块。
import re
2.findall()的语法:导入了re模块之后就可以使用findall()方法了,那么我们必须要清楚findall()的语法是怎么规定的。
findall(正则表达式,目标字符串)
不难看出findall()的是由正则表达式和目标字符串组成,目标字符串就是你要检索的东西,那么如何检索则是通过正则表达式来进行操作,也就是我们今天的重点。
使用findall()之后返回的结果是一个列表,列表中是符合正则要求的字符串
二、正则表达式(一).字符串的匹配
1.普通字符大多数的字母和字符都可以进行自身匹配。
import re a = "abc123+-*" b = re.findall('abc',a) print(b)
输出结果:
['abc']
2.元字符元字符指的是. ^ $ ? + {} \ []之类的特殊字符,通过它们我们可以对目标字符串进行个性化检索,返回我们要的结果。
这里我给大家介绍10个常用的元字符以及它们的用法,这里我先给大家做1个简单的汇总,便于记忆,下面会挨个讲解每一个元字符的使用。
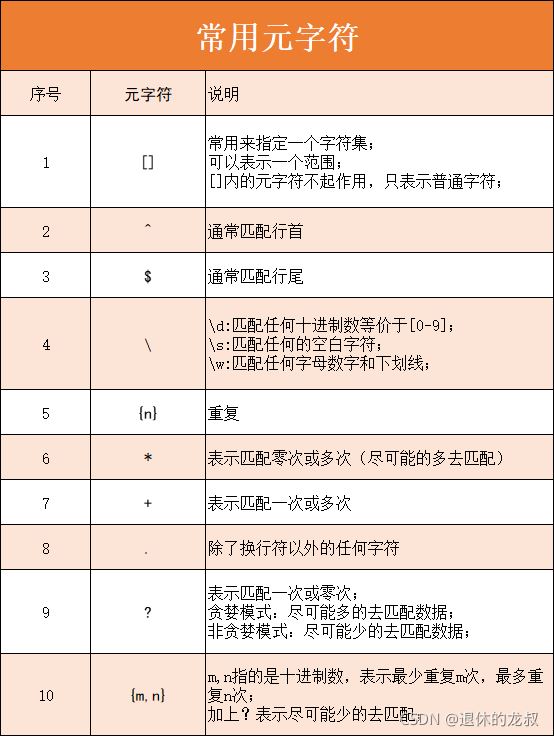
(1) []
[] 的使用方式主要有以下三种:
常用来指定一个字符集。
s = "a123456b" rule = "a[0-9][1-6][1-6][1-6][1-6][1-6]b" #这里暂时先用这种麻烦点的方法,后面有更容易的,不用敲这么多[1-6] l = re.findall(rule,s) print(l)
输出结果为:
['a123456b']
可以表示一个范围。
例如要在字符串"abcabcaccaac"中选出abc元素:
s = "abcabcaccaac" rule = "a[a,b,c]c" # rule = "a[a-z0-9][a-z0-9][a-z0-9][a-z0-9]c" l = re.findall(rule, s) print(l)
输出结果为:
['abc', 'abc', 'acc', 'aac']
[] 内的元字符不起作用,只表示普通字符。
例如要在字符串“caabcabcaabc”中选出“caa”:
print(re.findall("caa[a,^]", "caa^bcabcaabc"))
输出结果为:
['caa^']
注意点:当在[]的第一个位置时,表示除了a以外的都进行匹配,例如把[]中的和a换一下位置:
print(re.findall("caa[^,a]", "caa^bcabcaabc"))
输出:
['caa^', 'caab']
(2)^
^ 通常用来匹配行首,例如:
print(re.findall("^abca", "abcabcabc"))
输出结果:
['abca']

(3) $
$ 通常用来匹配行尾,例如:
print(re.findall("abc$", "accabcabc"))
输出结果:
['abc']

(4)\
反斜杠后面可以加不同的字符表示不同的特殊含义,常见的有以下3种。
\d:匹配任何十进制数等价于[0-9]
print(re.findall("c\d\d\da", "abc123abc"))
输出结果为:
['c123a']
\可以转义成普通字符,例如:
print(re.findall("\^abc", "^abc^abc"))
输出结果:
['^abc', '^abc']
s
匹配任何的空白字符例如:
print(re.findall("\s\s", "a c"))
输出结果:
[' ', ' ']
\w
匹配任何字母数字和下划线,等价于[a-zA-Z0-9_],例如:
print(re.findall("\w\w\w", "abc12_"))
输出:
['abc', '12_']

(5){n}
{n}可以避免重复写,比如前面我们用\w时写了3次\w,而这里我们这需要用用上{n}就可以,n表示匹配的次数,例如:
print(re.findall("\w{2}", "abc12_"))
输出结果:
['ab', 'c1', '2_']
(6)*
*表示匹配零次或多次(尽可能的多去匹配),例如:
print(re.findall("010-\d*", "010-123456789"))
输出:
['010-123456789']
**(7) + **
+表示匹配一次或多次,例如
print(re.findall("010-\d+", "010-123456789"))
输出:
['010-123456789']
(8) .
.是个点,这里不是很明显,它用来操作除了换行符以外的任何字符,例如:
print(re.findall(".", "010\n?!"))
输出:
['0', '1', '0', '?', '!']
(9) ?
?表示匹配一次或零次
print(re.findall("010-\d?", "010-123456789"))
输出:
['010-1']
这里要注意一下贪婪模式和非贪婪模式。
贪婪模式:尽可能多的去匹配数据,表现为\d后面加某个元字符,例如\d*:
print(re.findall("010-\d*", "010-123456789"))
输出:
['010-123456789']
非贪婪模式:尽可能少的去匹配数据,表现为\d后面加?,例如\d?
print(re.findall("010-\d*?", "010-123456789"))
输出为:
['010-']
(10){m,n}
m,n指的是十进制数,表示最少重复m次,最多重复n次,例如:
print(re.findall("010-\d{3,5}", "010-123456789"))
输出:
['010-12345']
加上?表示尽可能少的去匹配
print(re.findall("010-\d{3,5}?", "010-123456789"))
输出:
['010-123']
{m,n}还有其他的一些灵活的写法,比如:
{1,} 相当于前面提过的 + 的效果
{0,1} 相当于前面提过的 ? 的效果
{0,} 相当于前面提过的 * 的效果

关于常用的元字符以及使用方法就先到这里,我们再来看看正则的其他知识。
(二)正则的使用 1.编译正则在Python中,re模块可通过compile() 方法来编译正则,re.compile(正则表达式),例如: