
由于Size会进行2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。通过下面的例子,可以清楚的看到,21和5在原来的数组中都处于相同的位置,但是在新的数组中,21到了新的位置,位置为原来的位置加上16,也就是旧的Capacity;但是5还在原来的位置。
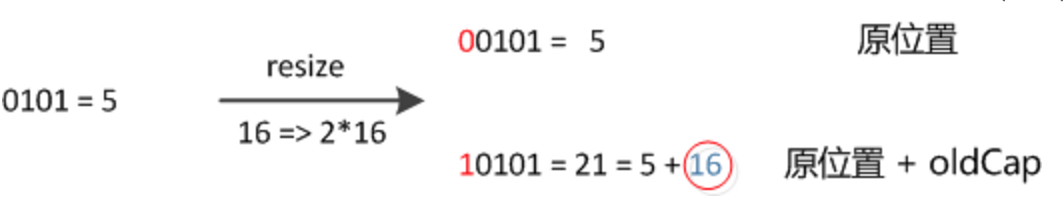
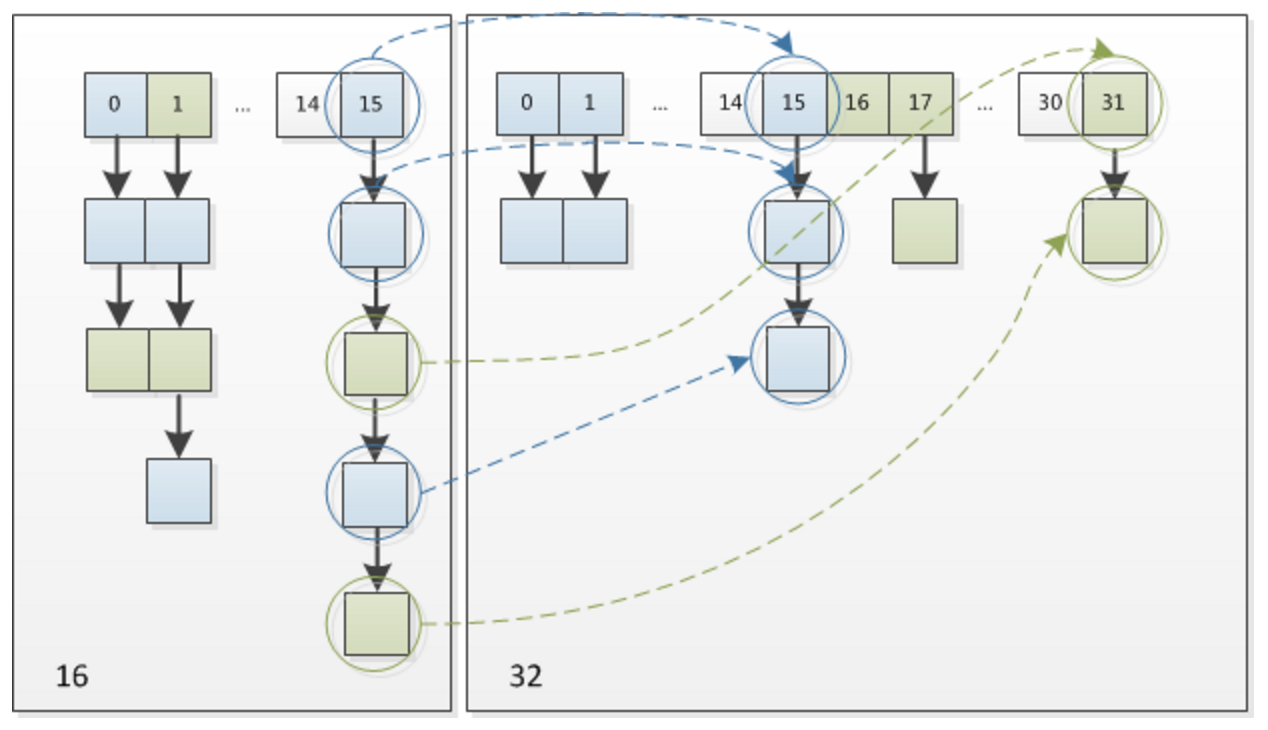
假定我们在Size变为2倍以后,重新计算hash,因为n变为2倍,相应的n-1的mask范围在高位多1bit(红色),也就是与上面示意图中红色部分对应的那一位,如果那位是1,则需要移动到新的位置,否则不变。
回到代码实现中,直接用旧的hash值与上oldCapacity,因为旧的capacity是2的倍数(二进制为00000...1000),而且获取旧index的时候采用hash&(oldCap-1),所以直接e.hash & oldCap就是判断新增加的高位是否为1,为1则需要移动,否则保持不变。
if ((e.hash & oldCap) == 0)这种巧妙的方法,同时由于高位的1和0随机出现,保证了resize之后元素分布的离散性。
下图是这一过程的模拟,
JDK8中的红黑树
引入红黑树主要是为了保证在hash分布极不均匀的情况下的性能,当一个链表太长(大于8)的时候,通过动态的将它替换成一个红黑树,这话的话会将时间复杂度从O(n)降为O(logn)。
为什么HashMap的数组长度一定保持2的次幂?
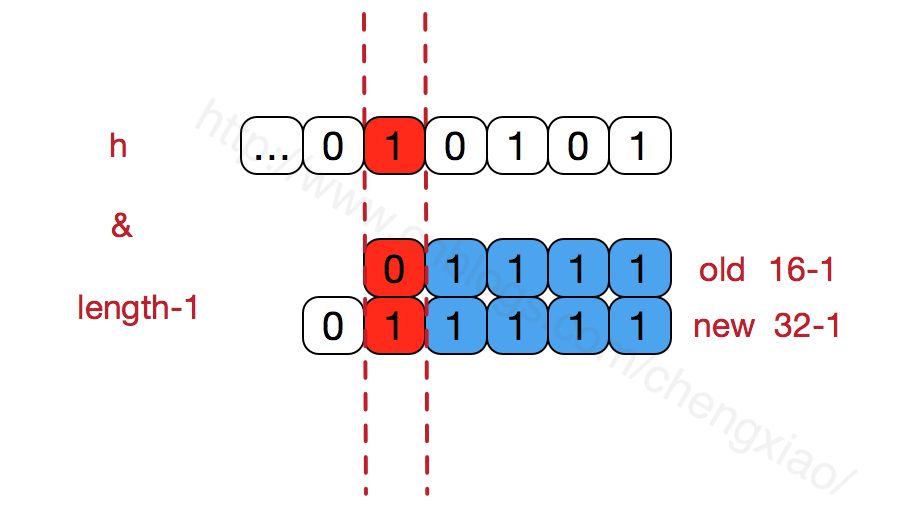
从上面的分析JDK8 resize的过程可以可能到,数组长度保持2的次幂,当resize的时候,为了通过h&(length-1)计算新的元素位置,可以看到当扩容后只有一位差异,也就是多出了最左位的1,这样计算 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致,否则index+OldCap。
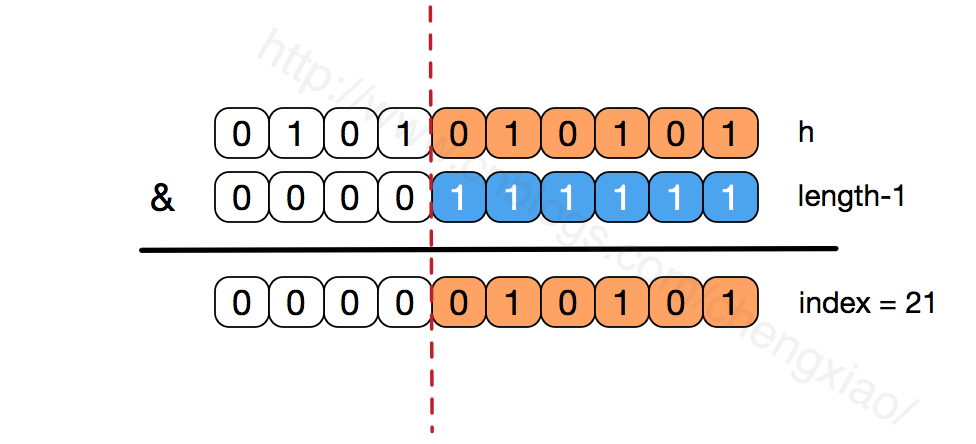
数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀。hash函数采用各种位运算也是为了使得低位更加散列,如果低位全部为1,那么对于h低位部分来说,任何一位的变化都会对结果产生影响,可以尽可能的使元素分布比较均匀。
HashMap Vs HashTable
HashMap允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许。
HashTable 继承自 Dictionary 类,而 HashMap 是 Java1.2 引进的 Map interface 的一个实现。
HashTable 的方法是 Synchronized 的,而 HashMap 不是,在多个线程访问 Hashtable 时,不需要自己为它的方法实现同步,而 HashMap 就必须为之提供外同步。
参考:
https://tech.meituan.com/2016/06/24/java-hashmap.html
https://juejin.im/post/5aa5d8d26fb9a028d2079264
https://my.oschina.net/hosee/blog/618953
https://www.imooc.com/article/22943
https://www.cnblogs.com/chengxiao/p/6059914.html
TreeMapTreeMap继承于AbstractMap,实现了Map, Cloneable, NavigableMap, Serializable接口。
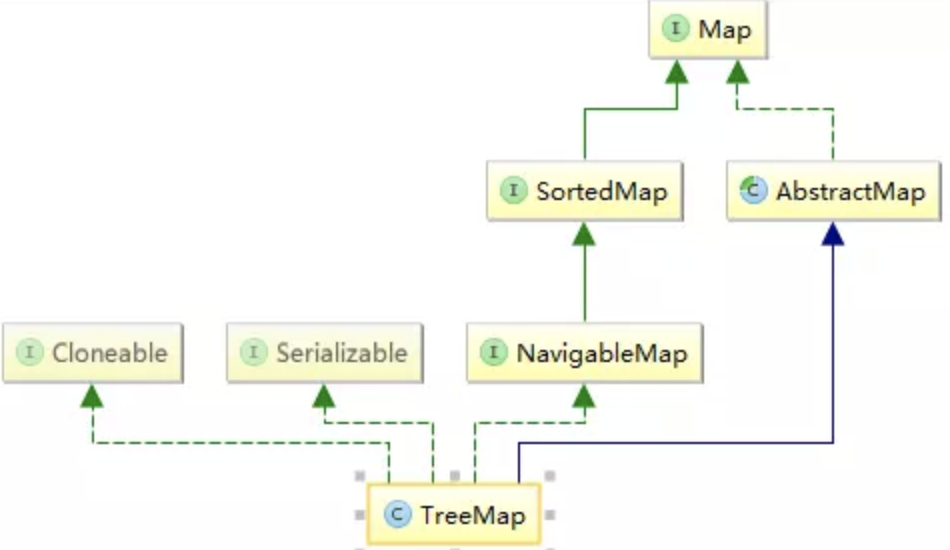
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的Comparator进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
对于SortedMap来说,该类是TreeMap体系中的父接口,也是区别于HashMap体系最关键的一个接口。SortedMap接口中定义的第一个方法Comparator<? super K> comparator();该方法决定了TreeMap体系的走向,有了比较器,就可以对插入的元素进行排序了。
TreeMap的查找、插入、更新元素等操作,主要是对红黑树的节点进行相应的更新,和数据结构中类似。
TreeSetTreeSet基于TreeMap实现,底层也是红黑树。只是每次插入元素时,value为一个默认的dummy数据。
HashSet