

在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比。
Hashtable、HashMap、TreeMap 都是最常见的一些 Map 实现,是以键值对的形式存储和操作数据的容器类型。
Hashtable 是早期 Java 类库提供的一个哈希表实现,本身是同步的,不支持 null 键和值,由于同步导致的性能开销,所以已经很少被推荐使用。
HashMap 是应用更加广泛的哈希表实现,行为上大致上与 HashTable 一致,主要区别在于 HashMap 不是同步的,支持 null 键和值等。通常情况下,HashMap 进行 put 或者 get 操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个用户 ID 和用户信息对应的运行时存储结构。
HashMap 明确声明不是线程安全的数据结构,如果忽略这一点,简单用在多线程场景里,难免会出现问题,如 HashMap 在并发环境可能出现无限循环占用 CPU、size 不准确等诡异的问题。
TreeMap 则是基于红黑树的一种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
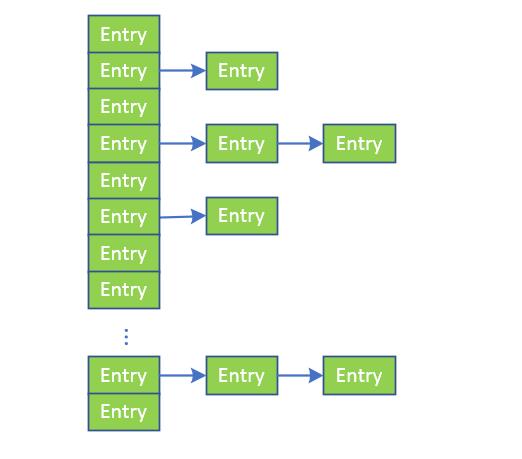
HashtableHashtable是通过"拉链法"实现的哈希表,结构如下图所示:
1. 定义
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable{}Hashtable 继承于 Dictionary 类,实现了 Map, Cloneable, java.io.Serializable接口。
2. 构造方法
Hashtable 一共提供了 4 个构造方法:
public Hashtable(int initialCapacity, float loadFactor): 用指定初始容量和指定负载因子构造一个新的空哈希表。 public Hashtable(int initialCapacity):用指定初始容量和默认的负载因子 (0.75) 构造一个新的空哈希表。 public Hashtable():默认构造函数,容量为 11,负载因子为 0.75。 - public Hashtable(Map<? extends K, ? extends V> t):构造一个与给定的 Map 具有相同映射关系的新哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table 是一个 Entry[] 数组类型,而 Entry实际上就是如上图所示的一个单向链表。Hashtable的键值对都是存储在Entry数组中的。
count 是 Hashtable 的大小,它是 Hashtable 保存的键值对的数量。
threshold 是 Hashtable 的阈值,用于判断是否需要调整 Hashtable 的容量。threshold 的值="容量 x 负载因子"。
loadFactor 就是负载因子。
modCount 记录hashTable被修改的次数,在对HashTable的操作中,无论add、remove、clear方法只要是涉及了改变Table数组元素的个数的方法都会导致modCount的改变。这主要用来实现“快速失败”也就是fail-fast,它是Java集合的一种错误检测机制。
fail-fast机制举例:有两个线程(线程A,线程B),其中线程A负责遍历list、线程B修改list。线程A在遍历list过程的某个时候(此时expectedModCount = modCount=N),线程启动,同时线程B增加一个元素,这是modCount的值发生改变(modCount + 1 = N + 1)。线程A继续遍历执行next方法时,通告checkForComodification方法发现expectedModCount = N ,而modCount = N + 1,两者不等,这时就抛出ConcurrentModificationException 异常,从而产生fail-fast机制。
3. PUT操作
put 方法的整个流程为:
判断 value 是否为空,为空则抛出异常;
计算 key 的 hash 值,并根据 hash 值获得 key 在 table 数组中的位置 index,如果 table[index] 元素不为空,则进行迭代,如果遇到相同的 key,则直接替换,并返回旧 value;
否则,我们可以将其插入到 table[index] 位置。
public synchronized V put(K key, V value) { // Make sure the value is not null确保value不为null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. //确保key不在hashtable中 //首先,通过hash方法计算key的哈希值,并计算得出index值,确定其在table[]中的位置 //其次,迭代index索引位置的链表,如果该位置处的链表存在相同的key,则替换value,返回旧的value Entry tab[] = table; int hash = hash(key); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } modCount++; if (count >= threshold) { // Rehash the table if the threshold is exceeded //如果超过阀值,就进行rehash操作 rehash(); tab = table; hash = hash(key); index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. //将值插入,返回的为null Entry<K,V> e = tab[index]; // 创建新的Entry节点,并将新的Entry插入Hashtable的index位置,并设置e为新的Entry的下一个元素 tab[index] = new Entry<>(hash, key, value, e); count++; return null; }4. Get操作